 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAG: Boosting Text-VQA via Text-aware Visual Question-answer Generation
Paper and Code
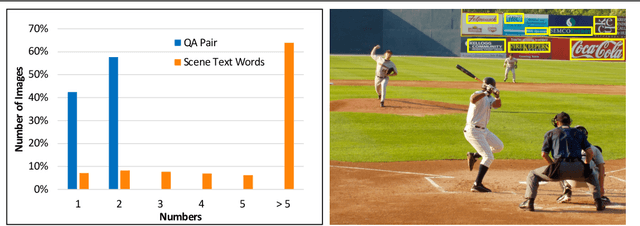
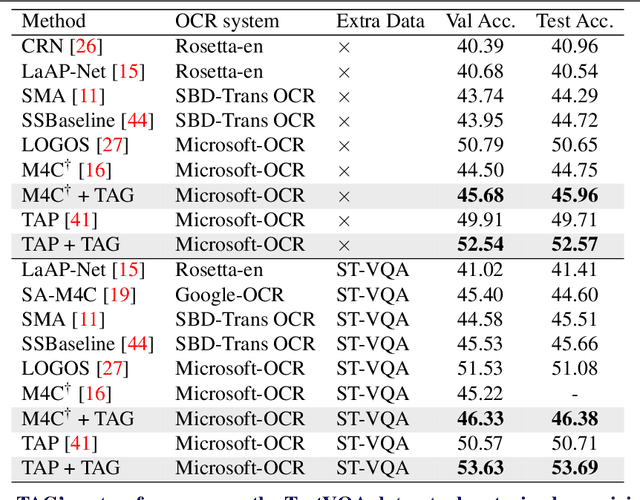

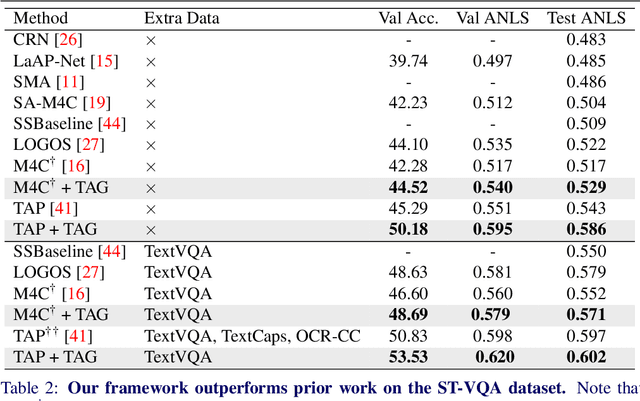
Text-VQA aims at answering questions that require understanding the textual cues in an image. Despite the great progress of existing Text-VQA methods, their performance suffers from insufficient human-labeled question-answer (QA) pairs. However, we observe that, in general, the scene text is not fully exploited in the existing datasets -- only a small portion of text in each image participates in the annotated QA activities. This results in a huge waste of useful information. To address this deficiency, we develop a new method to generate high-quality and diverse QA pairs by explicitly utilizing the existing rich text available in the scene context of each image. Specifically, we propose, TAG, a text-aware visual question-answer generation architecture that learns to produce meaningful, and accurate QA samples using a multimodal transformer. The architecture exploits underexplored scene text information and enhances scene understanding of Text-VQA models by combining the generated QA pairs with the initial training data. Extensive experimental results on two well-known Text-VQA benchmarks (TextVQA and ST-VQA) demonstrate that our proposed TAG effectively enlarges the training data that helps improve the Text-VQA performance without extra labeling effort. Moreover, our model outperforms state-of-the-art approaches that are pre-trained with extra large-scale data. Code is available at https://github.com/HenryJunW/TAG.