 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Complexity Hybrid Precoding Designs for Multiuser mmWave/THz Ultra Massive MIMO Systems
Jul 24, 2021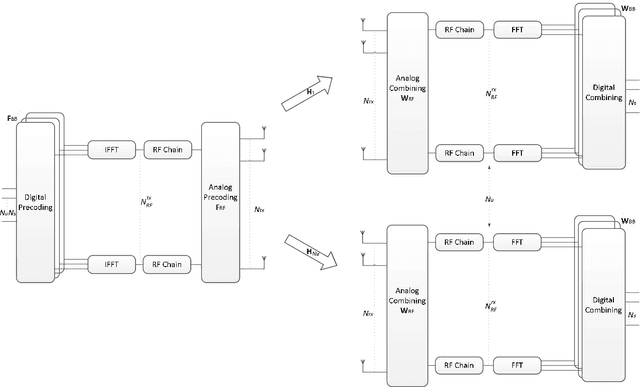
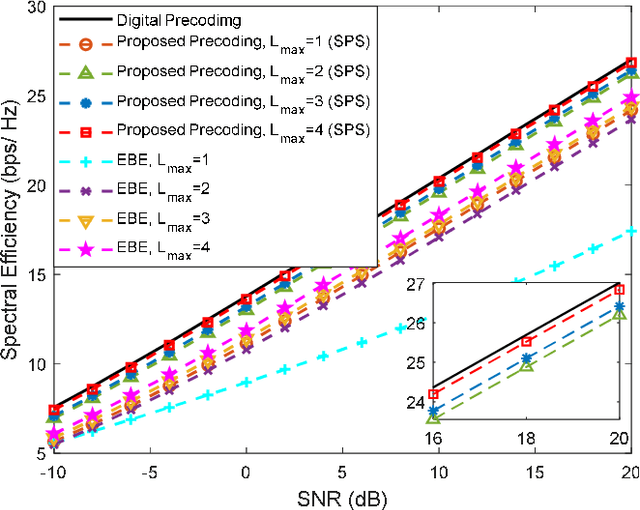
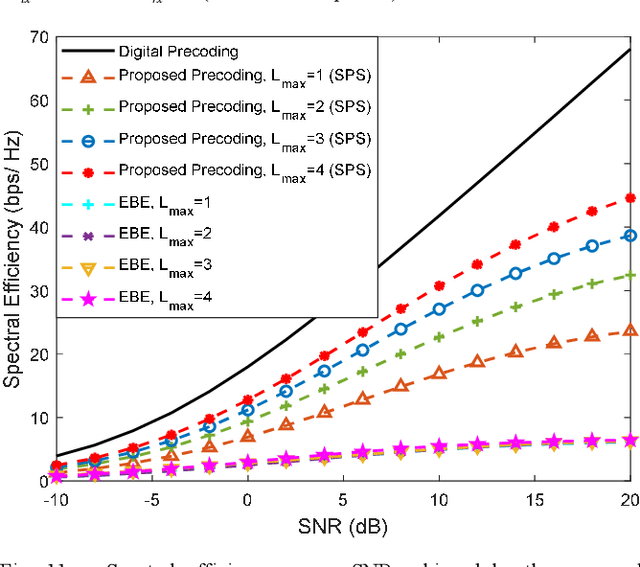
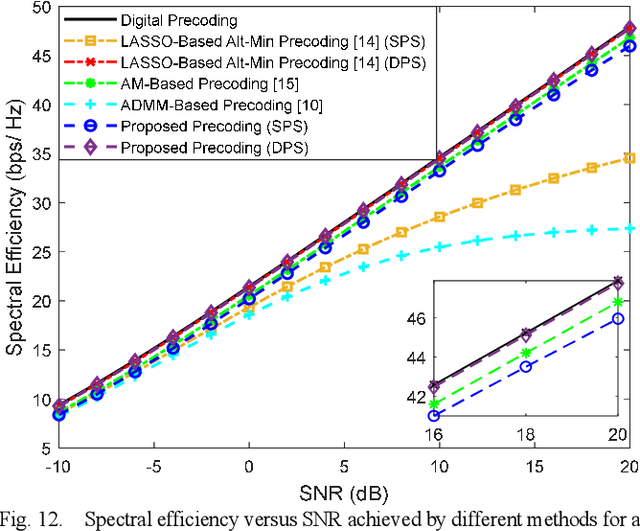
Millimeter-wave and terahertz technologies have been attracting attention from the wireless research community since they can offer large underutilized bandwidths which can enable the support of ultra-high-speed connections in future wireless communication systems. While the high signal attenuation occurring at these frequencies requires the adoption of very large (or the so-called ultra-massive) antenna arrays, in order to accomplish low complexity and low power consumption, hybrid analog/digital designs must be adopted. In this paper we present a hybrid design algorithm suitable for both mmWave and THz multiuser multiple-input multiple-output (MIMO) systems, which comprises separate computation steps for the digital precoder, analog precoder and multiuser interference mitigation. The design can also incorporate different analog architectures such as phase shifters, switches and inverters, antenna selection and so on. Furthermore, it is also applicable for different structures namely, fully connected, arrays of subarrays (AoSA) and dynamic arrays of subarrays (DAoSA), making it suitable for the support of ultra-massive MIMO (UM-MIMO) in severely hardware constrained THz systems. We will show that, by using the proposed approach, it is possible to achieve good trade-offs between spectral efficiency and simplified implementation, even as the number of users and data streams increases.)
SQuINTing at VQA Models: Interrogating VQA Models with Sub-Questions
Jan 20, 2020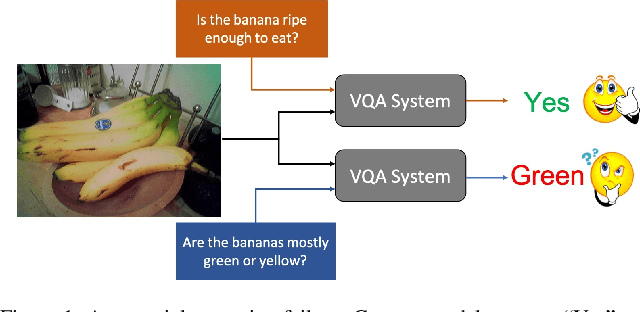

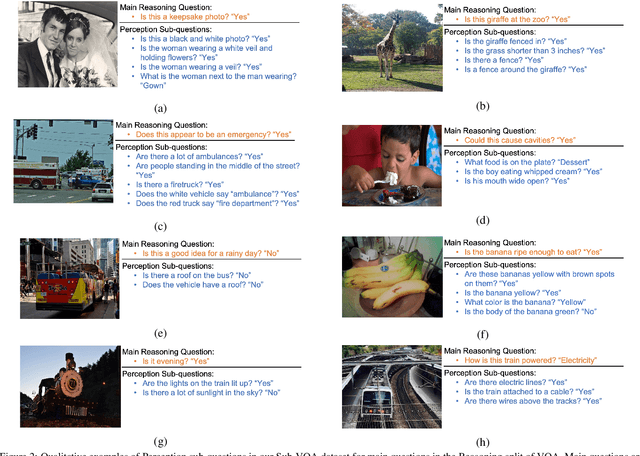
Existing VQA datasets contain questions with varying levels of complexity. While the majority of questions in these datasets require perception for recognizing existence, properties, and spatial relationships of entities, a significant portion of questions pose challenges that correspond to reasoning tasks -- tasks that can only be answered through a synthesis of perception and knowledge about the world, logic and / or reasoning. This distinction allows us to notice when existing VQA models have consistency issues -- they answer the reasoning question correctly but fail on associated low-level perception questions. For example, models answer the complex reasoning question "Is the banana ripe enough to eat?" correctly, but fail on the associated perception question "Are the bananas mostly green or yellow?" indicating that the model likely answered the reasoning question correctly but for the wrong reason. We quantify the extent to which this phenomenon occurs by creating a new Reasoning split of the VQA dataset and collecting Sub-VQA, a new dataset consisting of 200K new perception questions which serve as sub questions corresponding to the set of perceptual tasks needed to effectively answer the complex reasoning questions in the Reasoning split. Additionally, we propose an approach called Sub-Question Importance-aware Network Tuning (SQuINT), which encourages the model to attend do the same parts of the image when answering the reasoning question and the perception sub questions. We show that SQuINT improves model consistency by 7.8%, also marginally improving its performance on the Reasoning questions in VQA, while also displaying qualitatively better attention maps.