 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMagentic-UI: Towards Human-in-the-loop Agentic Systems
Jul 30, 2025AI agents powered by large language models are increasingly capable of autonomously completing complex, multi-step tasks using external tools. Yet, they still fall short of human-level performance in most domains including computer use, software development, and research. Their growing autonomy and ability to interact with the outside world, also introduces safety and security risks including potentially misaligned actions and adversarial manipulation. We argue that human-in-the-loop agentic systems offer a promising path forward, combining human oversight and control with AI efficiency to unlock productivity from imperfect systems. We introduce Magentic-UI, an open-source web interface for developing and studying human-agent interaction. Built on a flexible multi-agent architecture, Magentic-UI supports web browsing, code execution, and file manipulation, and can be extended with diverse tools via Model Context Protocol (MCP). Moreover, Magentic-UI presents six interaction mechanisms for enabling effective, low-cost human involvement: co-planning, co-tasking, multi-tasking, action guards, and long-term memory. We evaluate Magentic-UI across four dimensions: autonomous task completion on agentic benchmarks, simulated user testing of its interaction capabilities, qualitative studies with real users, and targeted safety assessments. Our findings highlight Magentic-UI's potential to advance safe and efficient human-agent collaboration.
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Nov 07, 2024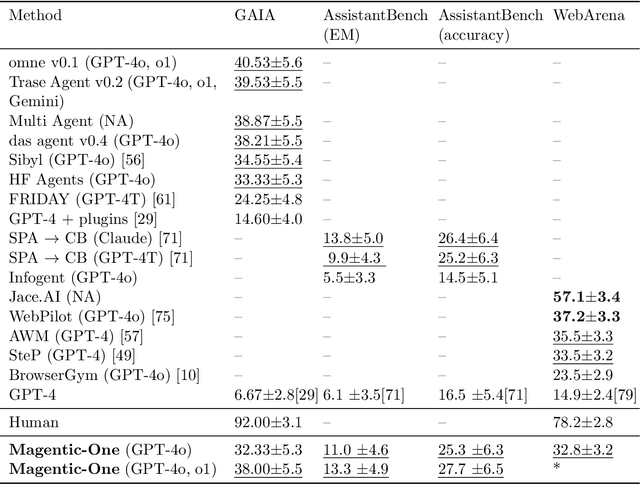
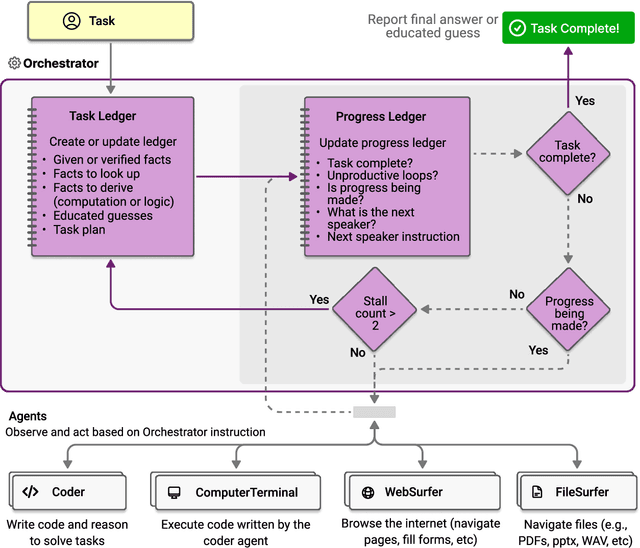
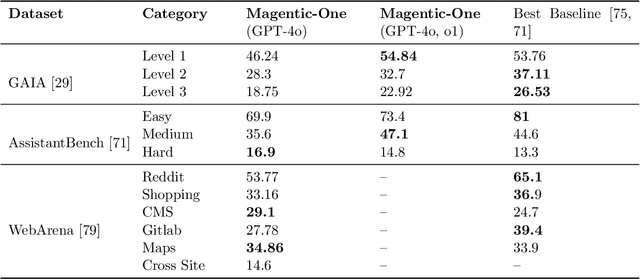
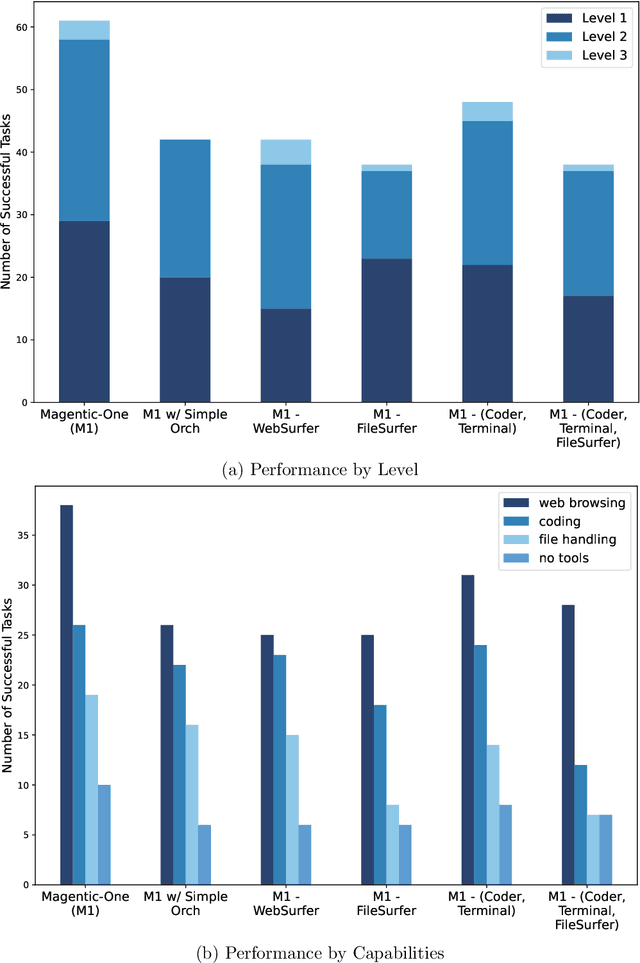
Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
Challenging the Machine: Contestability in Government AI Systems
Jun 14, 2024In an October 2023 executive order (EO), President Biden issued a detailed but largely aspirational road map for the safe and responsible development and use of artificial intelligence (AI). The challenge for the January 24-25, 2024 workshop was to transform those aspirations regarding one specific but crucial issue -- the ability of individuals to challenge government decisions made about themselves -- into actionable guidance enabling agencies to develop, procure, and use genuinely contestable advanced automated decision-making systems. While the Administration has taken important steps since the October 2023 EO, the insights garnered from our workshop remain highly relevant, as the requirements for contestability of advanced decision-making systems are not yet fully defined or implemented. The workshop brought together technologists, members of government agencies and civil society organizations, litigators, and researchers in an intensive two-day meeting that examined the challenges that users, developers, and agencies faced in enabling contestability in light of advanced automated decision-making systems. To ensure a free and open flow of discussion, the meeting was held under a modified version of the Chatham House rule. Participants were free to use any information or details that they learned, but they may not attribute any remarks made at the meeting by the identity or the affiliation of the speaker. Thus, the workshop summary that follows anonymizes speakers and their affiliation. Where an identification of an agency, company, or organization is made, it is done from a public, identified resource and does not necessarily reflect statements made by participants at the workshop. This document is a report of that workshop, along with recommendations and explanatory material.
Recommendations for Government Development and Use of Advanced Automated Systems to Make Decisions about Individuals
Mar 04, 2024Contestability -- the ability to effectively challenge a decision -- is critical to the implementation of fairness. In the context of governmental decision making about individuals, contestability is often constitutionally required as an element of due process; specific procedures may be required by state or federal law relevant to a particular program. In addition, contestability can be a valuable way to discover systemic errors, contributing to ongoing assessments and system improvement. On January 24-25, 2024, with support from the National Science Foundation and the William and Flora Hewlett Foundation, we convened a diverse group of government officials, representatives of leading technology companies, technology and policy experts from academia and the non-profit sector, advocates, and stakeholders for a workshop on advanced automated decision making, contestability, and the law. Informed by the workshop's rich and wide-ranging discussion, we offer these recommendations. A full report summarizing the discussion is in preparation.
Teaching Language Models to Hallucinate Less with Synthetic Tasks
Oct 10, 2023



Large language models (LLMs) frequently hallucinate on abstractive summarization tasks such as document-based question-answering, meeting summarization, and clinical report generation, even though all necessary information is included in context. However, optimizing LLMs to hallucinate less on these tasks is challenging, as hallucination is hard to efficiently evaluate at each optimization step. In this work, we show that reducing hallucination on a synthetic task can also reduce hallucination on real-world downstream tasks. Our method, SynTra, first designs a synthetic task where hallucinations are easy to elicit and measure. It next optimizes the LLM's system message via prefix-tuning on the synthetic task, and finally transfers the system message to realistic, hard-to-optimize tasks. Across three realistic abstractive summarization tasks, SynTra reduces hallucination for two 13B-parameter LLMs using only a synthetic retrieval task for supervision. We also find that optimizing the system message rather than the model weights can be critical; fine-tuning the entire model on the synthetic task can counterintuitively increase hallucination. Overall, SynTra demonstrates that the extra flexibility of working with synthetic data can help mitigate undesired behaviors in practice.
Attention Satisfies: A Constraint-Satisfaction Lens on Factual Errors of Language Models
Sep 26, 2023We investigate the internal behavior of Transformer-based Large Language Models (LLMs) when they generate factually incorrect text. We propose modeling factual queries as Constraint Satisfaction Problems and use this framework to investigate how the model interacts internally with factual constraints. Specifically, we discover a strong positive relation between the model's attention to constraint tokens and the factual accuracy of its responses. In our curated suite of 11 datasets with over 40,000 prompts, we study the task of predicting factual errors with the Llama-2 family across all scales (7B, 13B, 70B). We propose SAT Probe, a method probing self-attention patterns, that can predict constraint satisfaction and factual errors, and allows early error identification. The approach and findings demonstrate how using the mechanistic understanding of factuality in LLMs can enhance reliability.
Increasing Diversity While Maintaining Accuracy: Text Data Generation with Large Language Models and Human Interventions
Jun 07, 2023Large language models (LLMs) can be used to generate text data for training and evaluating other models. However, creating high-quality datasets with LLMs can be challenging. In this work, we explore human-AI partnerships to facilitate high diversity and accuracy in LLM-based text data generation. We first examine two approaches to diversify text generation: 1) logit suppression, which minimizes the generation of languages that have already been frequently generated, and 2) temperature sampling, which flattens the token sampling probability. We found that diversification approaches can increase data diversity but often at the cost of data accuracy (i.e., text and labels being appropriate for the target domain). To address this issue, we examined two human interventions, 1) label replacement (LR), correcting misaligned labels, and 2) out-of-scope filtering (OOSF), removing instances that are out of the user's domain of interest or to which no considered label applies. With oracle studies, we found that LR increases the absolute accuracy of models trained with diversified datasets by 14.4%. Moreover, we found that some models trained with data generated with LR interventions outperformed LLM-based few-shot classification. In contrast, OOSF was not effective in increasing model accuracy, implying the need for future work in human-in-the-loop text data generation.
Sparks of Artificial General Intelligence: Early experiments with GPT-4
Mar 27, 2023
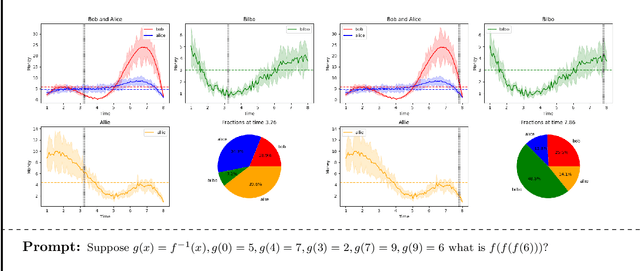


Artificial intelligence (AI) researchers have been developing and refining large language models (LLMs) that exhibit remarkable capabilities across a variety of domains and tasks, challenging our understanding of learning and cognition. The latest model developed by OpenAI, GPT-4, was trained using an unprecedented scale of compute and data. In this paper, we report on our investigation of an early version of GPT-4, when it was still in active development by OpenAI. We contend that (this early version of) GPT-4 is part of a new cohort of LLMs (along with ChatGPT and Google's PaLM for example) that exhibit more general intelligence than previous AI models. We discuss the rising capabilities and implications of these models. We demonstrate that, beyond its mastery of language, GPT-4 can solve novel and difficult tasks that span mathematics, coding, vision, medicine, law, psychology and more, without needing any special prompting. Moreover, in all of these tasks, GPT-4's performance is strikingly close to human-level performance, and often vastly surpasses prior models such as ChatGPT. Given the breadth and depth of GPT-4's capabilities, we believe that it could reasonably be viewed as an early (yet still incomplete) version of an artificial general intelligence (AGI) system. In our exploration of GPT-4, we put special emphasis on discovering its limitations, and we discuss the challenges ahead for advancing towards deeper and more comprehensive versions of AGI, including the possible need for pursuing a new paradigm that moves beyond next-word prediction. We conclude with reflections on societal influences of the recent technological leap and future research directions.
Benchmarking Spatial Relationships in Text-to-Image Generation
Dec 20, 2022



Spatial understanding is a fundamental aspect of computer vision and integral for human-level reasoning about images, making it an important component for grounded language understanding. While recent large-scale text-to-image synthesis (T2I) models have shown unprecedented improvements in photorealism, it is unclear whether they have reliable spatial understanding capabilities. We investigate the ability of T2I models to generate correct spatial relationships among objects and present VISOR, an evaluation metric that captures how accurately the spatial relationship described in text is generated in the image. To benchmark existing models, we introduce a large-scale challenge dataset SR2D that contains sentences describing two objects and the spatial relationship between them. We construct and harness an automated evaluation pipeline that employs computer vision to recognize objects and their spatial relationships, and we employ it in a large-scale evaluation of T2I models. Our experiments reveal a surprising finding that, although recent state-of-the-art T2I models exhibit high image quality, they are severely limited in their ability to generate multiple objects or the specified spatial relations such as left/right/above/below. Our analyses demonstrate several biases and artifacts of T2I models such as the difficulty with generating multiple objects, a bias towards generating the first object mentioned, spatially inconsistent outputs for equivalent relationships, and a correlation between object co-occurrence and spatial understanding capabilities. We conduct a human study that shows the alignment between VISOR and human judgment about spatial understanding. We offer the SR2D dataset and the VISOR metric to the community in support of T2I spatial reasoning research.
Artificial Intelligence and Life in 2030: The One Hundred Year Study on Artificial Intelligence
Oct 31, 2022In September 2016, Stanford's "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the first report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Peter Stone of the University of Texas at Austin. The report, entitled "Artificial Intelligence and Life in 2030," examines eight domains of typical urban settings on which AI is likely to have impact over the coming years: transportation, home and service robots, healthcare, education, public safety and security, low-resource communities, employment and workplace, and entertainment. It aims to provide the general public with a scientifically and technologically accurate portrayal of the current state of AI and its potential and to help guide decisions in industry and governments, as well as to inform research and development in the field. The charge for this report was given to the panel by the AI100 Standing Committee, chaired by Barbara Grosz of Harvard University.