 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiases in Large Language Model-Elicited Text: A Case Study in Natural Language Inference
Mar 06, 2025We test whether NLP datasets created with Large Language Models (LLMs) contain annotation artifacts and social biases like NLP datasets elicited from crowd-source workers. We recreate a portion of the Stanford Natural Language Inference corpus using GPT-4, Llama-2 70b for Chat, and Mistral 7b Instruct. We train hypothesis-only classifiers to determine whether LLM-elicited NLI datasets contain annotation artifacts. Next, we use pointwise mutual information to identify the words in each dataset that are associated with gender, race, and age-related terms. On our LLM-generated NLI datasets, fine-tuned BERT hypothesis-only classifiers achieve between 86-96% accuracy. Our analyses further characterize the annotation artifacts and stereotypical biases in LLM-generated datasets.
Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks
Nov 07, 2024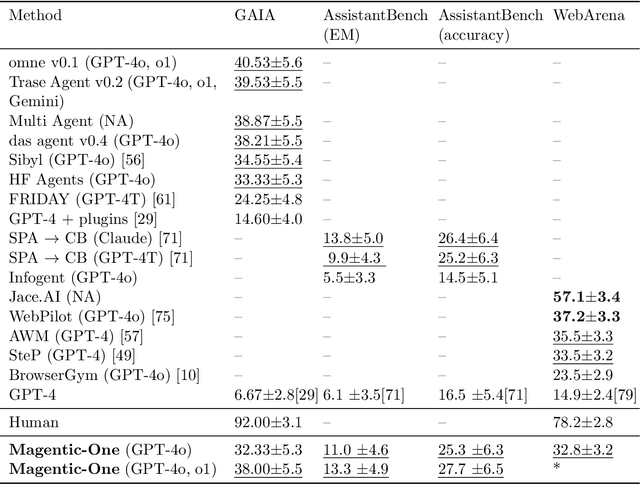
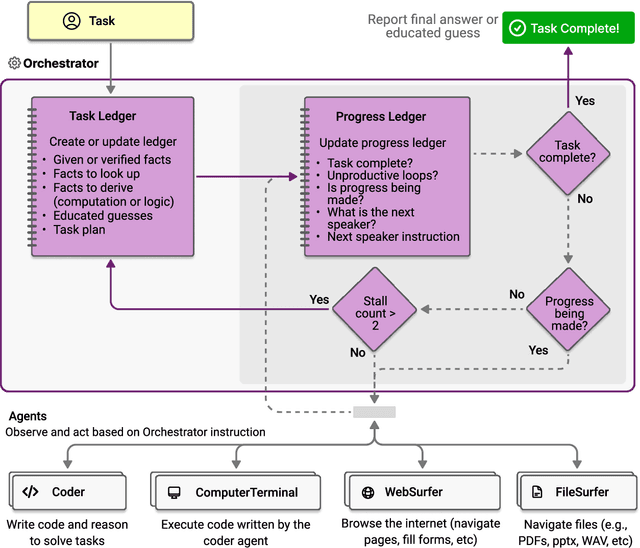
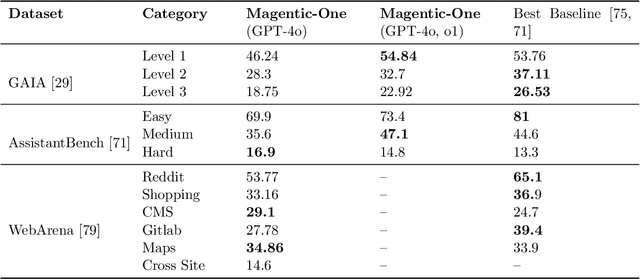
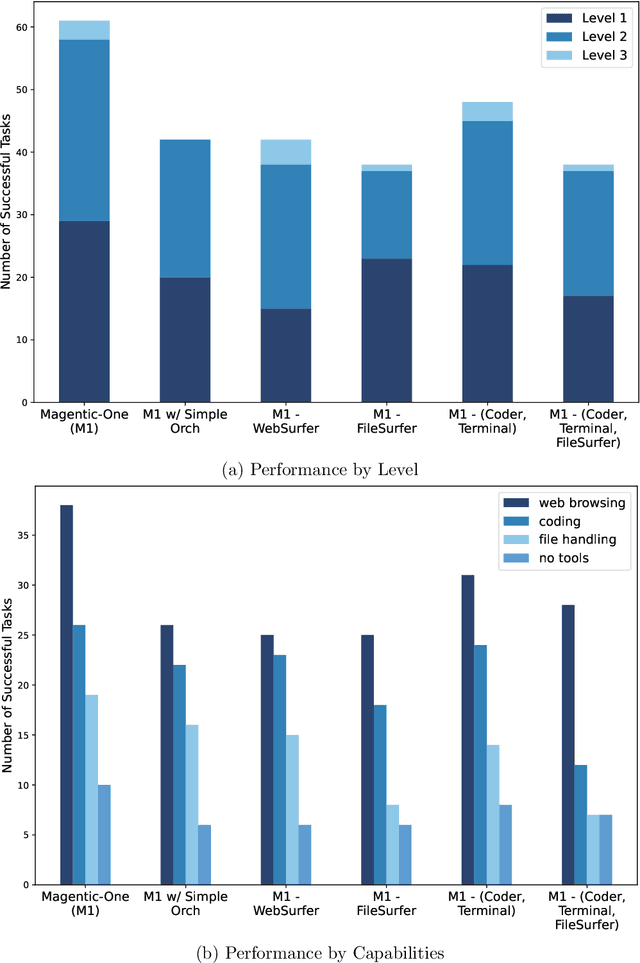
Modern AI agents, driven by advances in large foundation models, promise to enhance our productivity and transform our lives by augmenting our knowledge and capabilities. To achieve this vision, AI agents must effectively plan, perform multi-step reasoning and actions, respond to novel observations, and recover from errors, to successfully complete complex tasks across a wide range of scenarios. In this work, we introduce Magentic-One, a high-performing open-source agentic system for solving such tasks. Magentic-One uses a multi-agent architecture where a lead agent, the Orchestrator, plans, tracks progress, and re-plans to recover from errors. Throughout task execution, the Orchestrator directs other specialized agents to perform tasks as needed, such as operating a web browser, navigating local files, or writing and executing Python code. We show that Magentic-One achieves statistically competitive performance to the state-of-the-art on three diverse and challenging agentic benchmarks: GAIA, AssistantBench, and WebArena. Magentic-One achieves these results without modification to core agent capabilities or to how they collaborate, demonstrating progress towards generalist agentic systems. Moreover, Magentic-One's modular design allows agents to be added or removed from the team without additional prompt tuning or training, easing development and making it extensible to future scenarios. We provide an open-source implementation of Magentic-One, and we include AutoGenBench, a standalone tool for agentic evaluation. AutoGenBench provides built-in controls for repetition and isolation to run agentic benchmarks in a rigorous and contained manner -- which is important when agents' actions have side-effects. Magentic-One, AutoGenBench and detailed empirical performance evaluations of Magentic-One, including ablations and error analysis are available at https://aka.ms/magentic-one
Hypothesis-only Biases in Large Language Model-Elicited Natural Language Inference
Oct 11, 2024We test whether replacing crowdsource workers with LLMs to write Natural Language Inference (NLI) hypotheses similarly results in annotation artifacts. We recreate a portion of the Stanford NLI corpus using GPT-4, Llama-2 and Mistral 7b, and train hypothesis-only classifiers to determine whether LLM-elicited hypotheses contain annotation artifacts. On our LLM-elicited NLI datasets, BERT-based hypothesis-only classifiers achieve between 86-96% accuracy, indicating these datasets contain hypothesis-only artifacts. We also find frequent "give-aways" in LLM-generated hypotheses, e.g. the phrase "swimming in a pool" appears in more than 10,000 contradictions generated by GPT-4. Our analysis provides empirical evidence that well-attested biases in NLI can persist in LLM-generated data.