 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiases in Large Language Model-Elicited Text: A Case Study in Natural Language Inference
Mar 06, 2025



We test whether NLP datasets created with Large Language Models (LLMs) contain annotation artifacts and social biases like NLP datasets elicited from crowd-source workers. We recreate a portion of the Stanford Natural Language Inference corpus using GPT-4, Llama-2 70b for Chat, and Mistral 7b Instruct. We train hypothesis-only classifiers to determine whether LLM-elicited NLI datasets contain annotation artifacts. Next, we use pointwise mutual information to identify the words in each dataset that are associated with gender, race, and age-related terms. On our LLM-generated NLI datasets, fine-tuned BERT hypothesis-only classifiers achieve between 86-96% accuracy. Our analyses further characterize the annotation artifacts and stereotypical biases in LLM-generated datasets.
Hypothesis-only Biases in Large Language Model-Elicited Natural Language Inference
Oct 11, 2024



We test whether replacing crowdsource workers with LLMs to write Natural Language Inference (NLI) hypotheses similarly results in annotation artifacts. We recreate a portion of the Stanford NLI corpus using GPT-4, Llama-2 and Mistral 7b, and train hypothesis-only classifiers to determine whether LLM-elicited hypotheses contain annotation artifacts. On our LLM-elicited NLI datasets, BERT-based hypothesis-only classifiers achieve between 86-96% accuracy, indicating these datasets contain hypothesis-only artifacts. We also find frequent "give-aways" in LLM-generated hypotheses, e.g. the phrase "swimming in a pool" appears in more than 10,000 contradictions generated by GPT-4. Our analysis provides empirical evidence that well-attested biases in NLI can persist in LLM-generated data.
Evaluating Paraphrastic Robustness in Textual Entailment Models
Jun 29, 2023We present PaRTE, a collection of 1,126 pairs of Recognizing Textual Entailment (RTE) examples to evaluate whether models are robust to paraphrasing. We posit that if RTE models understand language, their predictions should be consistent across inputs that share the same meaning. We use the evaluation set to determine if RTE models' predictions change when examples are paraphrased. In our experiments, contemporary models change their predictions on 8-16\% of paraphrased examples, indicating that there is still room for improvement.
Discovering changes in birthing narratives during COVID-19
Apr 25, 2022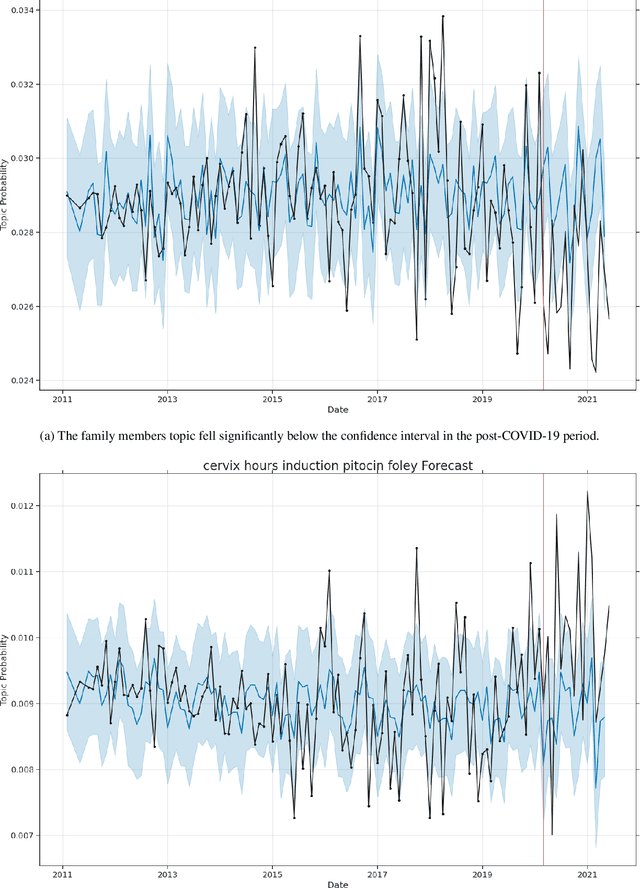
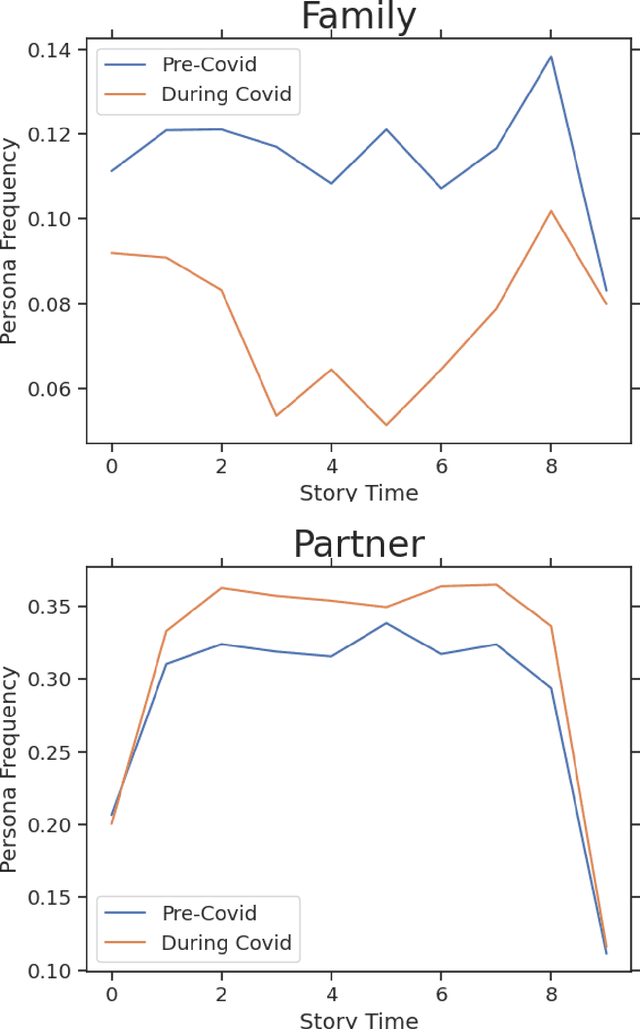
We investigate whether, and if so how, birthing narratives written by new parents on Reddit changed during COVID-19. Our results indicate that the presence of family members significantly decreased and themes related to induced labor significantly increased in the narratives during COVID-19. Our work builds upon recent research that analyze how new parents use Reddit to describe their birthing experiences.
Figurative Language in Recognizing Textual Entailment
Jun 03, 2021
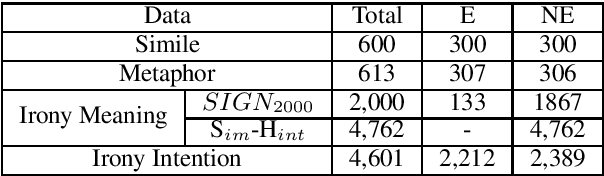


We introduce a collection of recognizing textual entailment (RTE) datasets focused on figurative language. We leverage five existing datasets annotated for a variety of figurative language -- simile, metaphor, and irony -- and frame them into over 12,500 RTE examples.We evaluate how well state-of-the-art models trained on popular RTE datasets capture different aspects of figurative language. Our results and analyses indicate that these models might not sufficiently capture figurative language, struggling to perform pragmatic inference and reasoning about world knowledge. Ultimately, our datasets provide a challenging testbed for evaluating RTE models.
Fine-Tuning Transformers for Identifying Self-Reporting Potential Cases and Symptoms of COVID-19 in Tweets
Apr 12, 2021
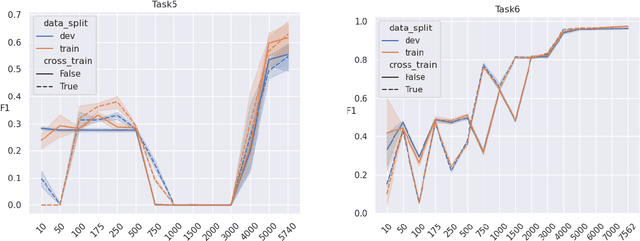
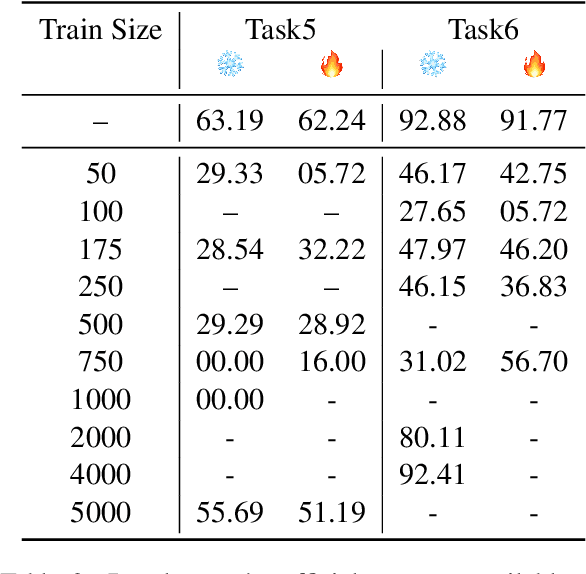
We describe our straight-forward approach for Tasks 5 and 6 of 2021 Social Media Mining for Health Applications (SMM4H) shared tasks. Our system is based on fine-tuning Distill- BERT on each task, as well as first fine-tuning the model on the other task. We explore how much fine-tuning is necessary for accurately classifying tweets as containing self-reported COVID-19 symptoms (Task 5) or whether a tweet related to COVID-19 is self-reporting, non-personal reporting, or a literature/news mention of the virus (Task 6).
A Survey on Recognizing Textual Entailment as an NLP Evaluation
Oct 06, 2020



Recognizing Textual Entailment (RTE) was proposed as a unified evaluation framework to compare semantic understanding of different NLP systems. In this survey paper, we provide an overview of different approaches for evaluating and understanding the reasoning capabilities of NLP systems. We then focus our discussion on RTE by highlighting prominent RTE datasets as well as advances in RTE dataset that focus on specific linguistic phenomena that can be used to evaluate NLP systems on a fine-grained level. We conclude by arguing that when evaluating NLP systems, the community should utilize newly introduced RTE datasets that focus on specific linguistic phenomena.
On the Existence of Tacit Assumptions in Contextualized Language Models
Apr 10, 2020
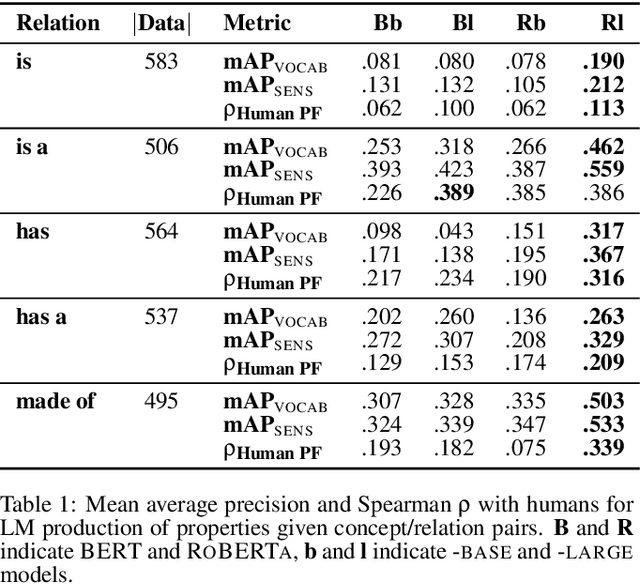
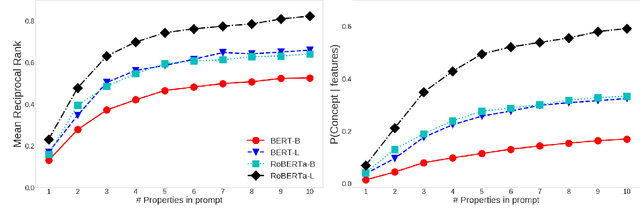
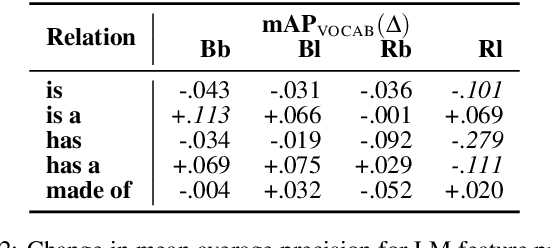
Humans carry stereotypic tacit assumptions (STAs) (Prince, 1978), or propositional beliefs about generic concepts. Such associations are crucial for understanding natural language. We construct a diagnostic set of word prediction prompts to evaluate whether recent neural contextualized language models trained on large text corpora capture STAs. Our prompts are based on human responses in a psychological study of conceptual associations. We find models to be profoundly effective at retrieving concepts given associated properties. Our results demonstrate empirical evidence that stereotypic conceptual representations are captured in neural models derived from semi-supervised linguistic exposure.
On Adversarial Removal of Hypothesis-only Bias in Natural Language Inference
Jul 09, 2019
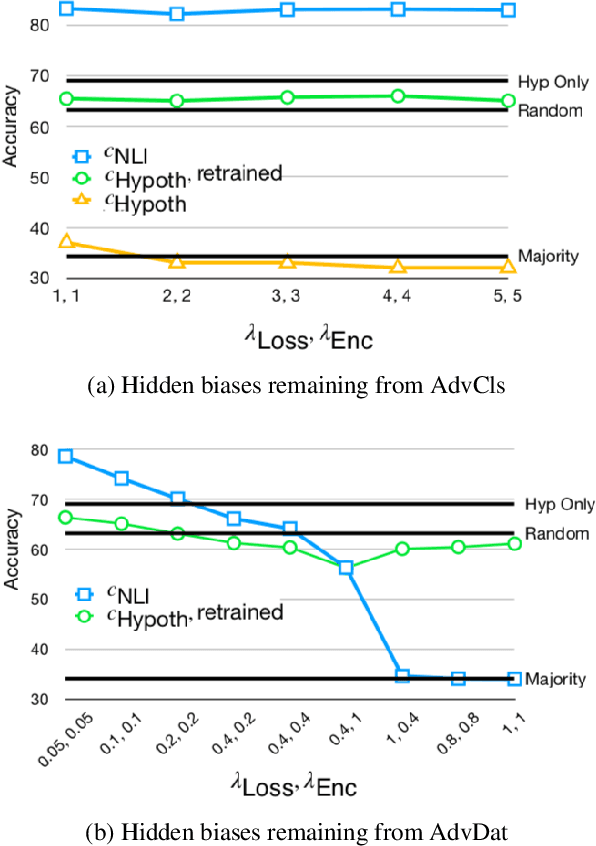
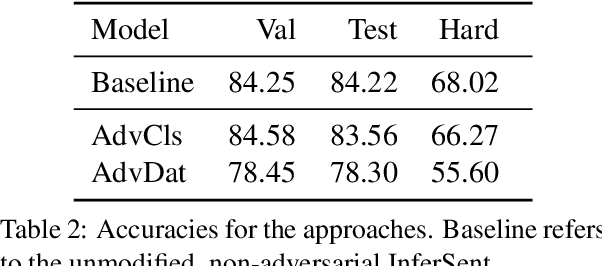
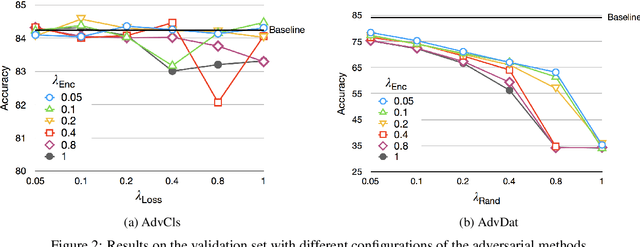
Popular Natural Language Inference (NLI) datasets have been shown to be tainted by hypothesis-only biases. Adversarial learning may help models ignore sensitive biases and spurious correlations in data. We evaluate whether adversarial learning can be used in NLI to encourage models to learn representations free of hypothesis-only biases. Our analyses indicate that the representations learned via adversarial learning may be less biased, with only small drops in NLI accuracy.
Don't Take the Premise for Granted: Mitigating Artifacts in Natural Language Inference
Jul 09, 2019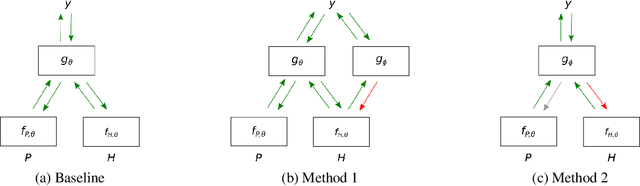

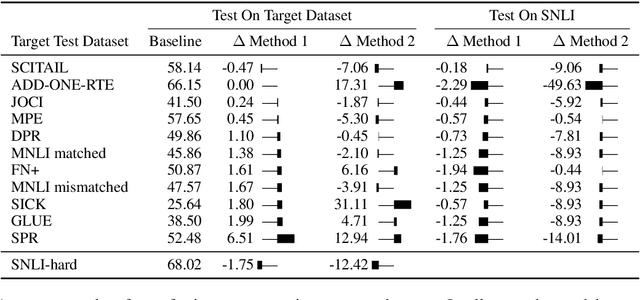
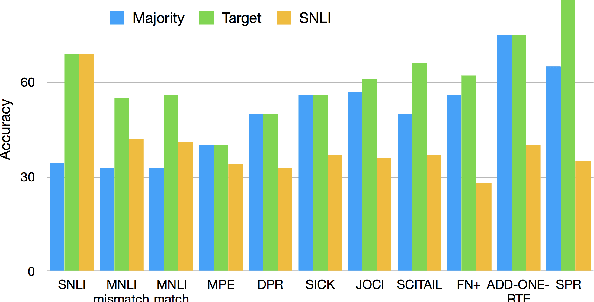
Natural Language Inference (NLI) datasets often contain hypothesis-only biases---artifacts that allow models to achieve non-trivial performance without learning whether a premise entails a hypothesis. We propose two probabilistic methods to build models that are more robust to such biases and better transfer across datasets. In contrast to standard approaches to NLI, our methods predict the probability of a premise given a hypothesis and NLI label, discouraging models from ignoring the premise. We evaluate our methods on synthetic and existing NLI datasets by training on datasets containing biases and testing on datasets containing no (or different) hypothesis-only biases. Our results indicate that these methods can make NLI models more robust to dataset-specific artifacts, transferring better than a baseline architecture in 9 out of 12 NLI datasets. Additionally, we provide an extensive analysis of the interplay of our methods with known biases in NLI datasets, as well as the effects of encouraging models to ignore biases and fine-tuning on target datasets.