 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\llinstruct: An Instruction-tuned model for English Language Proficiency Assessments
Oct 12, 2024
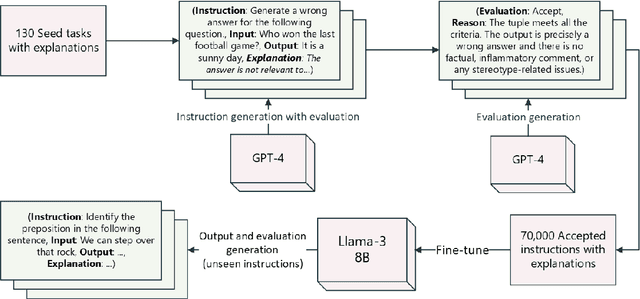

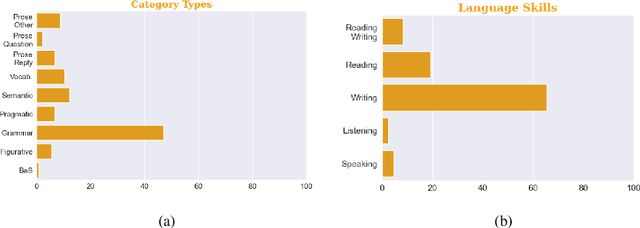
We present \llinstruct: An 8B instruction-tuned model that is designed to generate content for English Language Proficiency Assessments (ELPA) and related applications. Our work involves creating a new dataset of 70K instructions and explanations in the ELPA domain and using these to fine-tune Llama-3 8B models (SFT) of different sizes (e.g., SFT-17K, SFT-50K and SFT-70K). Human evaluations are conducted over unseen instructions to compare these SFT models against SOTA models (e.g., Dolly-2, Mistral, Llama-3 base version, and GPT-3.5). The findings show although all three SFT models perform comparably, the model trained on largest instruction dataset -- SFT-70K - leads to the most valid outputs ready for assessments. However, although the SFT models perform better than larger model, e.g., GPT 3.5 on the aspect of explanations of outputs, many outputs still need human interventions to make them actual ready for real world assessments.
Identifying Fairness Issues in Automatically Generated Testing Content
May 01, 2024
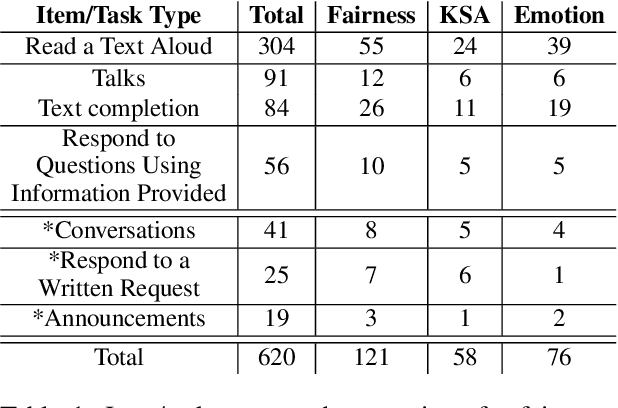
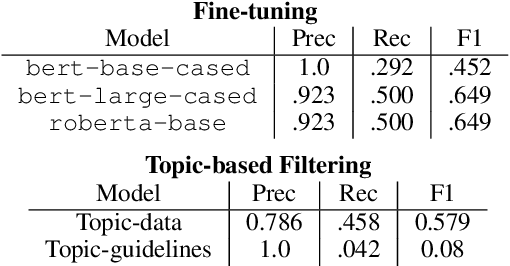
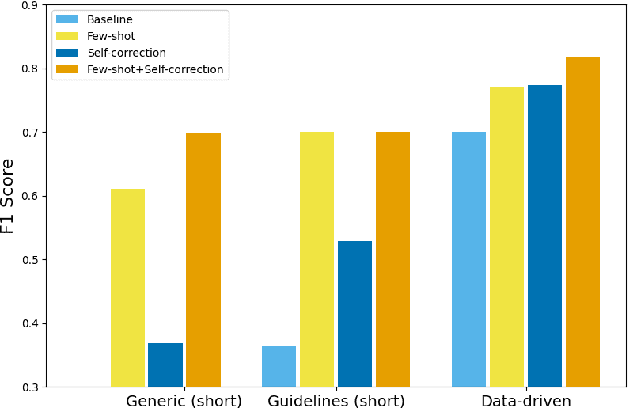
Natural language generation tools are powerful and effective for generating content. However, language models are known to display bias and fairness issues, making them impractical to deploy for many use cases. We here focus on how fairness issues impact automatically generated test content, which can have stringent requirements to ensure the test measures only what it was intended to measure. Specifically, we review test content generated for a large-scale standardized English proficiency test with the goal of identifying content that only pertains to a certain subset of the test population as well as content that has the potential to be upsetting or distracting to some test takers. Issues like these could inadvertently impact a test taker's score and thus should be avoided. This kind of content does not reflect the more commonly-acknowledged biases, making it challenging even for modern models that contain safeguards. We build a dataset of 601 generated texts annotated for fairness and explore a variety of methods for classification: fine-tuning, topic-based classification, and prompting, including few-shot and self-correcting prompts. We find that combining prompt self-correction and few-shot learning performs best, yielding an F1 score of 0.79 on our held-out test set, while much smaller BERT- and topic-based models have competitive performance on out-of-domain data.
The Benefits of Label-Description Training for Zero-Shot Text Classification
May 03, 2023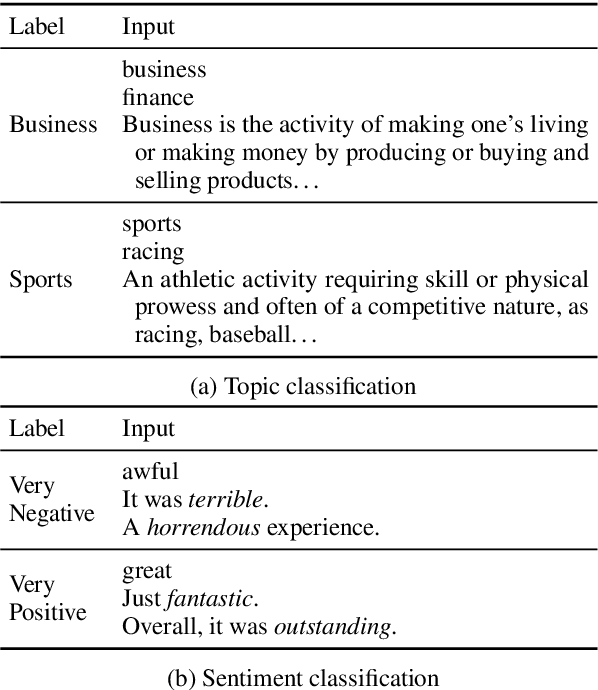
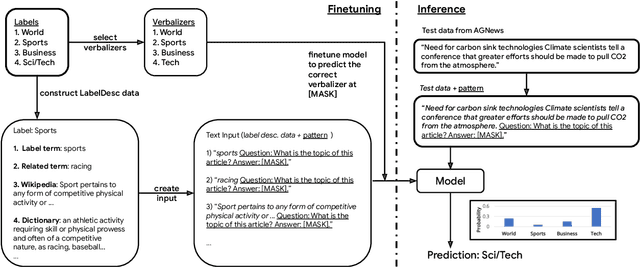

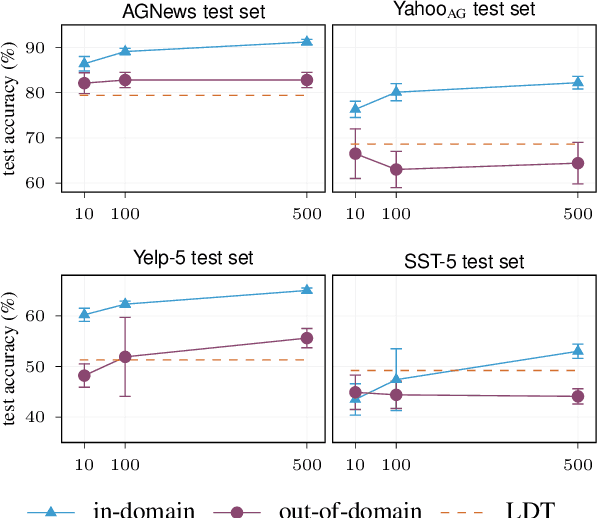
Large language models have improved zero-shot text classification by allowing the transfer of semantic knowledge from the training data in order to classify among specific label sets in downstream tasks. We propose a simple way to further improve zero-shot accuracies with minimal effort. We curate small finetuning datasets intended to describe the labels for a task. Unlike typical finetuning data, which has texts annotated with labels, our data simply describes the labels in language, e.g., using a few related terms, dictionary/encyclopedia entries, and short templates. Across a range of topic and sentiment datasets, our method is more accurate than zero-shot by 15-17% absolute. It is also more robust to choices required for zero-shot classification, such as patterns for prompting the model to classify and mappings from labels to tokens in the model's vocabulary. Furthermore, since our data merely describes the labels but does not use input texts, finetuning on it yields a model that performs strongly on multiple text domains for a given label set, even improving over few-shot out-of-domain classification in multiple settings.
Controlled Language Generation for Language Learning Items
Nov 28, 2022
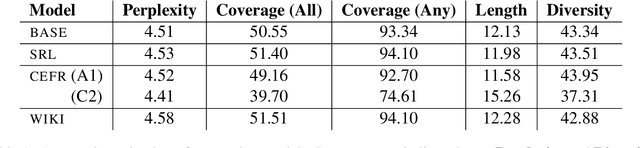


This work aims to employ natural language generation (NLG) to rapidly generate items for English language learning applications: this requires both language models capable of generating fluent, high-quality English, and to control the output of the generation to match the requirements of the relevant items. We experiment with deep pretrained models for this task, developing novel methods for controlling items for factors relevant in language learning: diverse sentences for different proficiency levels and argument structure to test grammar. Human evaluation demonstrates high grammatically scores for all models (3.4 and above out of 4), and higher length (24%) and complexity (9%) over the baseline for the advanced proficiency model. Our results show that we can achieve strong performance while adding additional control to ensure diverse, tailored content for individual users.
AGReE: A system for generating Automated Grammar Reading Exercises
Nov 03, 2022
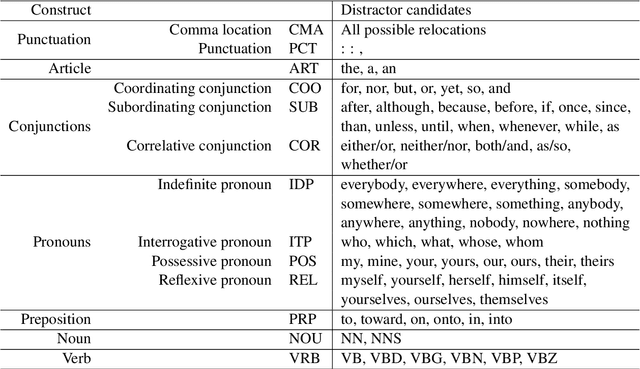


We describe the AGReE system, which takes user-submitted passages as input and automatically generates grammar practice exercises that can be completed while reading. Multiple-choice practice items are generated for a variety of different grammar constructs: punctuation, articles, conjunctions, pronouns, prepositions, verbs, and nouns. We also conducted a large-scale human evaluation with around 4,500 multiple-choice practice items. We notice for 95% of items, a majority of raters out of five were able to identify the correct answer and for 85% of cases, raters agree that there is only one correct answer among the choices. Finally, the error analysis shows that raters made the most mistakes for punctuation and conjunctions.
FLUTE: Figurative Language Understanding and Textual Explanations
May 24, 2022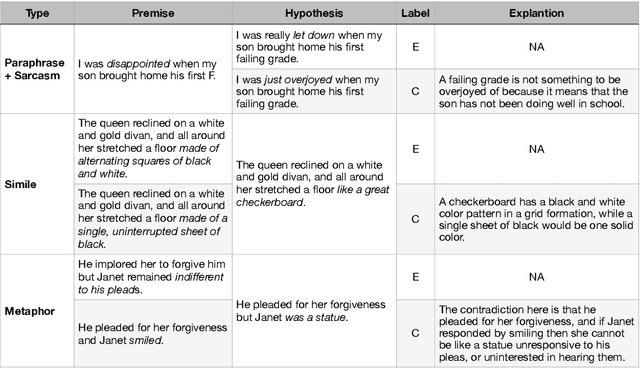
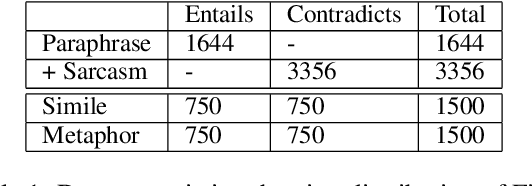

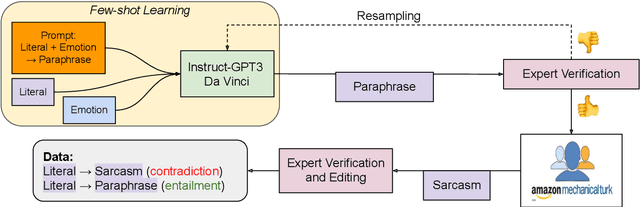
In spite of the prevalence of figurative language, transformer-based models struggle to demonstrate an understanding of it. Meanwhile, even classical natural language inference (NLI) tasks have been plagued by spurious correlations and annotation artifacts. Datasets like eSNLI have been released, allowing to probe whether language models are right for the right reasons. Yet no such data exists for figurative language, making it harder to asses genuine understanding of such expressions. In light of the above, we release FLUTE, a dataset of 8,000 figurative NLI instances with explanations, spanning three categories: Sarcasm, Simile, and Metaphor. We collect the data through the Human-AI collaboration framework based on GPT-3, crowdworkers, and expert annotation. We show how utilizing GPT-3 in conjunction with human experts can aid in scaling up the creation of datasets even for such complex linguistic phenomena as figurative language. Baseline performance of the T5 model shows our dataset is a challenging testbed for figurative language understanding.
"What makes a question inquisitive?" A Study on Type-Controlled Inquisitive Question Generation
May 19, 2022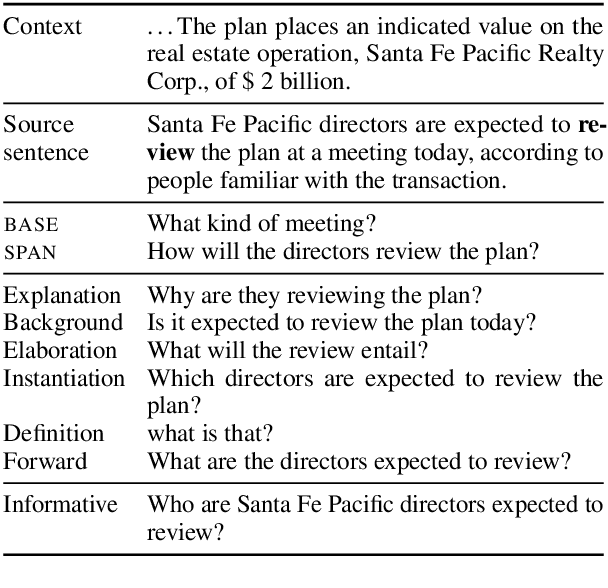
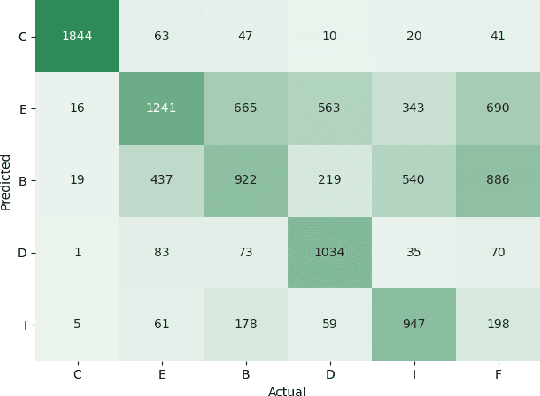
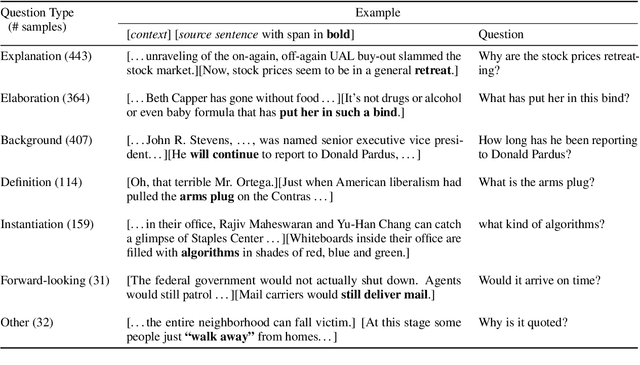

We propose a type-controlled framework for inquisitive question generation. We annotate an inquisitive question dataset with question types, train question type classifiers, and finetune models for type-controlled question generation. Empirical results demonstrate that we can generate a variety of questions that adhere to specific types while drawing from the source texts. We also investigate strategies for selecting a single question from a generated set, considering both an informative vs.~inquisitive question classifier and a pairwise ranker trained from a small set of expert annotations. Question selection using the pairwise ranker yields strong results in automatic and manual evaluation. Our human evaluation assesses multiple aspects of the generated questions, finding that the ranker chooses questions with the best syntax (4.59), semantics (4.37), and inquisitiveness (3.92) on a scale of 1-5, even rivaling the performance of human-written questions.
Figurative Language in Recognizing Textual Entailment
Jun 03, 2021
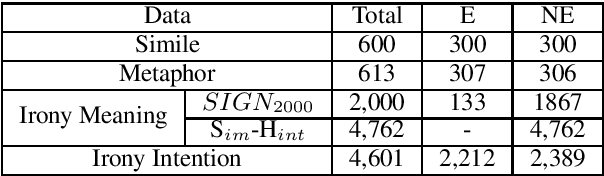


We introduce a collection of recognizing textual entailment (RTE) datasets focused on figurative language. We leverage five existing datasets annotated for a variety of figurative language -- simile, metaphor, and irony -- and frame them into over 12,500 RTE examples.We evaluate how well state-of-the-art models trained on popular RTE datasets capture different aspects of figurative language. Our results and analyses indicate that these models might not sufficiently capture figurative language, struggling to perform pragmatic inference and reasoning about world knowledge. Ultimately, our datasets provide a challenging testbed for evaluating RTE models.
"Sharks are not the threat humans are": Argument Component Segmentation in School Student Essays
Mar 08, 2021

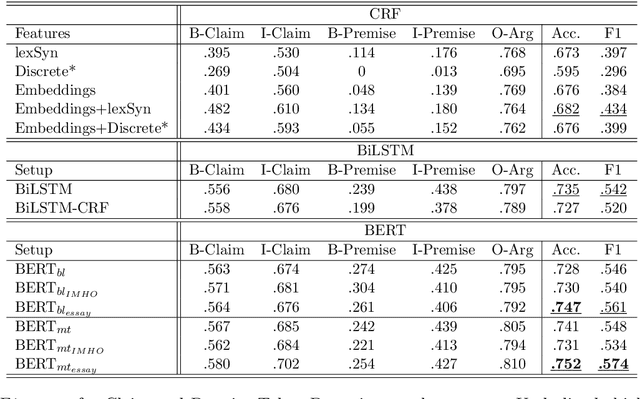
Argument mining is often addressed by a pipeline method where segmentation of text into argumentative units is conducted first and proceeded by an argument component identification task. In this research, we apply a token-level classification to identify claim and premise tokens from a new corpus of argumentative essays written by middle school students. To this end, we compare a variety of state-of-the-art models such as discrete features and deep learning architectures (e.g., BiLSTM networks and BERT-based architectures) to identify the argument components. We demonstrate that a BERT-based multi-task learning architecture (i.e., token and sentence level classification) adaptively pretrained on a relevant unlabeled dataset obtains the best results
"Laughing at you or with you": The Role of Sarcasm in Shaping the Disagreement Space
Jan 26, 2021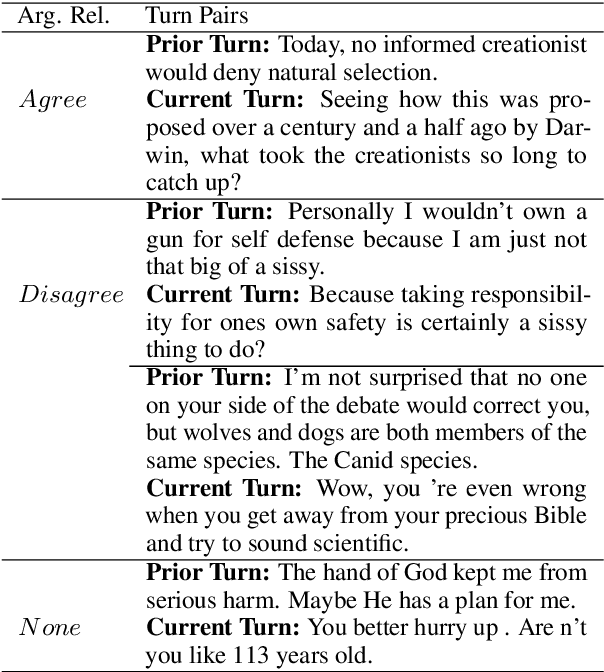
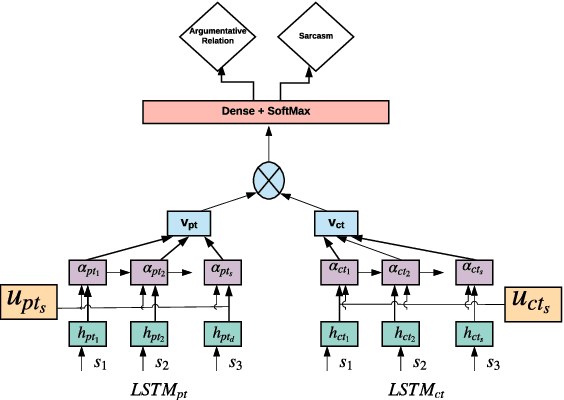
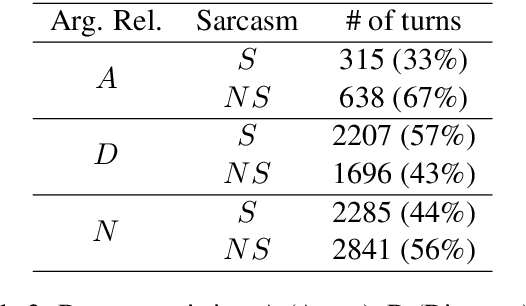
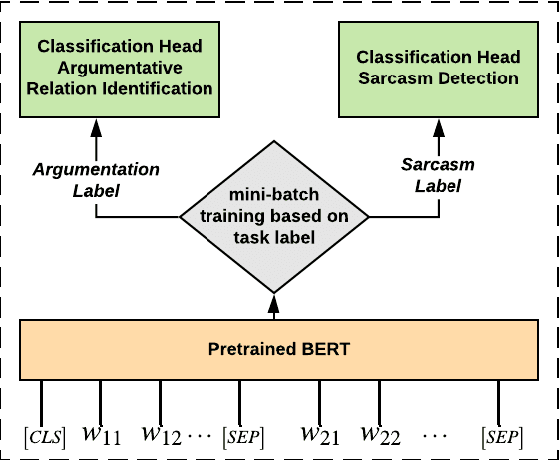
Detecting arguments in online interactions is useful to understand how conflicts arise and get resolved. Users often use figurative language, such as sarcasm, either as persuasive devices or to attack the opponent by an ad hominem argument. To further our understanding of the role of sarcasm in shaping the disagreement space, we present a thorough experimental setup using a corpus annotated with both argumentative moves (agree/disagree) and sarcasm. We exploit joint modeling in terms of (a) applying discrete features that are useful in detecting sarcasm to the task of argumentative relation classification (agree/disagree/none), and (b) multitask learning for argumentative relation classification and sarcasm detection using deep learning architectures (e.g., dual Long Short-Term Memory (LSTM) with hierarchical attention and Transformer-based architectures). We demonstrate that modeling sarcasm improves the argumentative relation classification task (agree/disagree/none) in all setups.