 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\textsc{CantoNLU}: A benchmark for Cantonese natural language understanding
Oct 23, 2025Cantonese, although spoken by millions, remains under-resourced due to policy and diglossia. To address this scarcity of evaluation frameworks for Cantonese, we introduce \textsc{\textbf{CantoNLU}}, a benchmark for Cantonese natural language understanding (NLU). This novel benchmark spans seven tasks covering syntax and semantics, including word sense disambiguation, linguistic acceptability judgment, language detection, natural language inference, sentiment analysis, part-of-speech tagging, and dependency parsing. In addition to the benchmark, we provide model baseline performance across a set of models: a Mandarin model without Cantonese training, two Cantonese-adapted models obtained by continual pre-training a Mandarin model on Cantonese text, and a monolingual Cantonese model trained from scratch. Results show that Cantonese-adapted models perform best overall, while monolingual models perform better on syntactic tasks. Mandarin models remain competitive in certain settings, indicating that direct transfer may be sufficient when Cantonese domain data is scarce. We release all datasets, code, and model weights to facilitate future research in Cantonese NLP.
\llinstruct: An Instruction-tuned model for English Language Proficiency Assessments
Oct 12, 2024
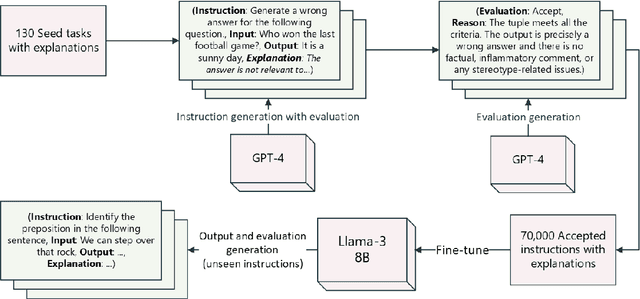

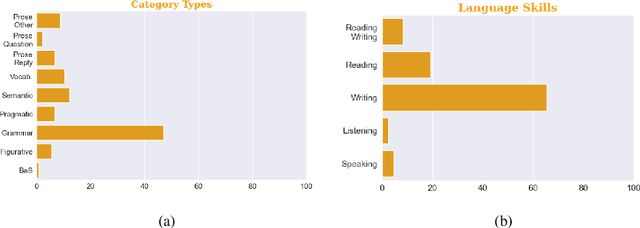
We present \llinstruct: An 8B instruction-tuned model that is designed to generate content for English Language Proficiency Assessments (ELPA) and related applications. Our work involves creating a new dataset of 70K instructions and explanations in the ELPA domain and using these to fine-tune Llama-3 8B models (SFT) of different sizes (e.g., SFT-17K, SFT-50K and SFT-70K). Human evaluations are conducted over unseen instructions to compare these SFT models against SOTA models (e.g., Dolly-2, Mistral, Llama-3 base version, and GPT-3.5). The findings show although all three SFT models perform comparably, the model trained on largest instruction dataset -- SFT-70K - leads to the most valid outputs ready for assessments. However, although the SFT models perform better than larger model, e.g., GPT 3.5 on the aspect of explanations of outputs, many outputs still need human interventions to make them actual ready for real world assessments.
AGReE: A system for generating Automated Grammar Reading Exercises
Nov 03, 2022
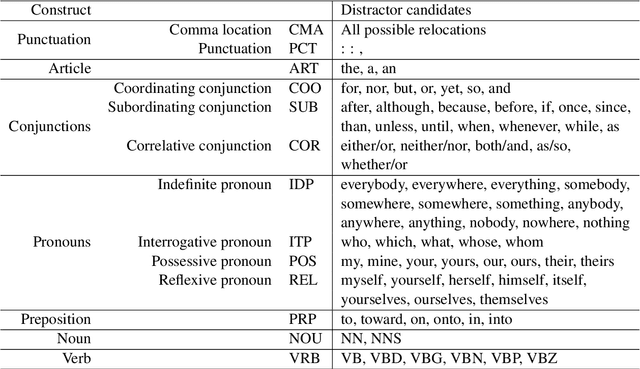


We describe the AGReE system, which takes user-submitted passages as input and automatically generates grammar practice exercises that can be completed while reading. Multiple-choice practice items are generated for a variety of different grammar constructs: punctuation, articles, conjunctions, pronouns, prepositions, verbs, and nouns. We also conducted a large-scale human evaluation with around 4,500 multiple-choice practice items. We notice for 95% of items, a majority of raters out of five were able to identify the correct answer and for 85% of cases, raters agree that there is only one correct answer among the choices. Finally, the error analysis shows that raters made the most mistakes for punctuation and conjunctions.