 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\llinstruct: An Instruction-tuned model for English Language Proficiency Assessments
Paper and Code

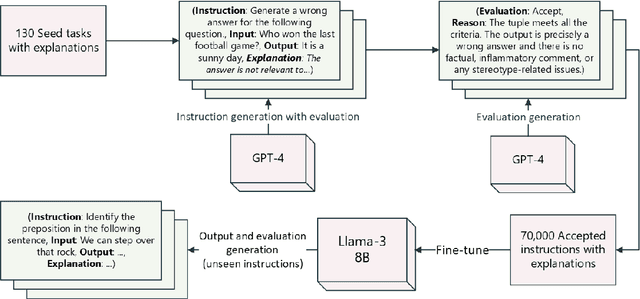

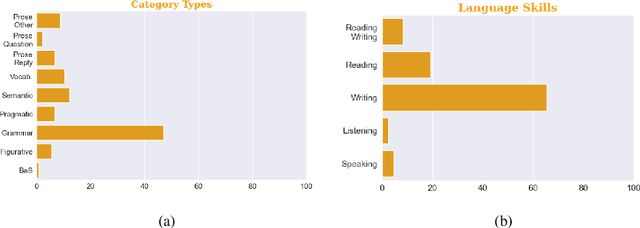
We present \llinstruct: An 8B instruction-tuned model that is designed to generate content for English Language Proficiency Assessments (ELPA) and related applications. Our work involves creating a new dataset of 70K instructions and explanations in the ELPA domain and using these to fine-tune Llama-3 8B models (SFT) of different sizes (e.g., SFT-17K, SFT-50K and SFT-70K). Human evaluations are conducted over unseen instructions to compare these SFT models against SOTA models (e.g., Dolly-2, Mistral, Llama-3 base version, and GPT-3.5). The findings show although all three SFT models perform comparably, the model trained on largest instruction dataset -- SFT-70K - leads to the most valid outputs ready for assessments. However, although the SFT models perform better than larger model, e.g., GPT 3.5 on the aspect of explanations of outputs, many outputs still need human interventions to make them actual ready for real world assessments.