 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Fairness Issues in Automatically Generated Testing Content
May 01, 2024
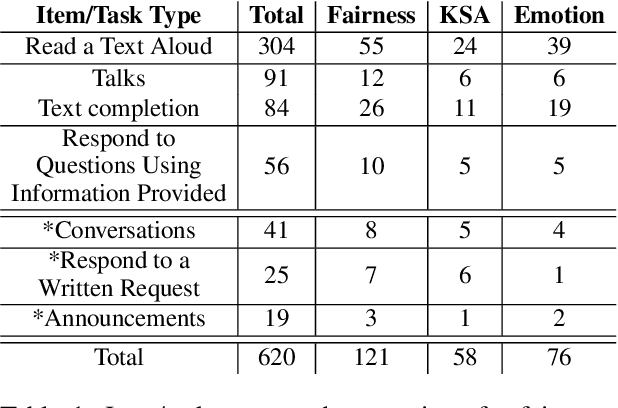
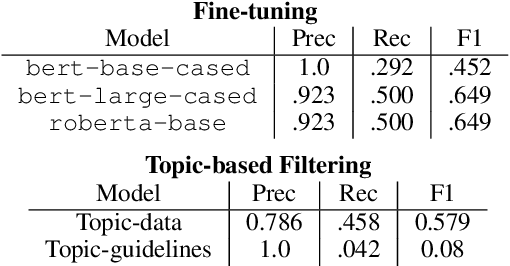
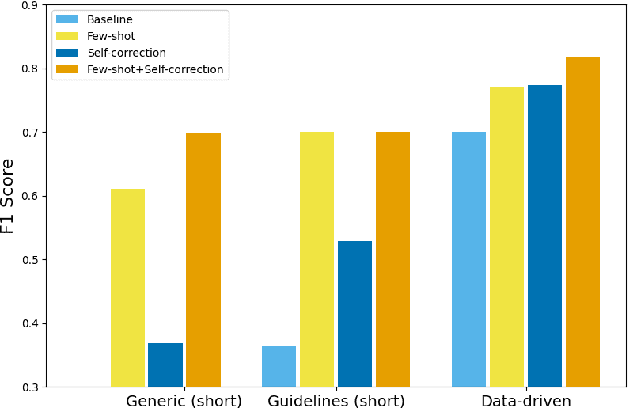
Natural language generation tools are powerful and effective for generating content. However, language models are known to display bias and fairness issues, making them impractical to deploy for many use cases. We here focus on how fairness issues impact automatically generated test content, which can have stringent requirements to ensure the test measures only what it was intended to measure. Specifically, we review test content generated for a large-scale standardized English proficiency test with the goal of identifying content that only pertains to a certain subset of the test population as well as content that has the potential to be upsetting or distracting to some test takers. Issues like these could inadvertently impact a test taker's score and thus should be avoided. This kind of content does not reflect the more commonly-acknowledged biases, making it challenging even for modern models that contain safeguards. We build a dataset of 601 generated texts annotated for fairness and explore a variety of methods for classification: fine-tuning, topic-based classification, and prompting, including few-shot and self-correcting prompts. We find that combining prompt self-correction and few-shot learning performs best, yielding an F1 score of 0.79 on our held-out test set, while much smaller BERT- and topic-based models have competitive performance on out-of-domain data.
AGReE: A system for generating Automated Grammar Reading Exercises
Nov 03, 2022
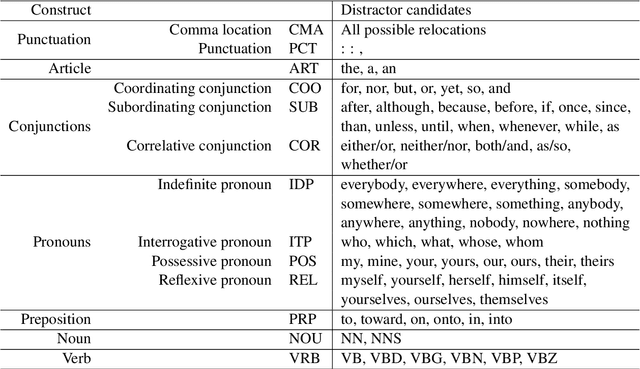


We describe the AGReE system, which takes user-submitted passages as input and automatically generates grammar practice exercises that can be completed while reading. Multiple-choice practice items are generated for a variety of different grammar constructs: punctuation, articles, conjunctions, pronouns, prepositions, verbs, and nouns. We also conducted a large-scale human evaluation with around 4,500 multiple-choice practice items. We notice for 95% of items, a majority of raters out of five were able to identify the correct answer and for 85% of cases, raters agree that there is only one correct answer among the choices. Finally, the error analysis shows that raters made the most mistakes for punctuation and conjunctions.
Two-Level Transformer and Auxiliary Coherence Modeling for Improved Text Segmentation
Jan 03, 2020



Breaking down the structure of long texts into semantically coherent segments makes the texts more readable and supports downstream applications like summarization and retrieval. Starting from an apparent link between text coherence and segmentation, we introduce a novel supervised model for text segmentation with simple but explicit coherence modeling. Our model -- a neural architecture consisting of two hierarchically connected Transformer networks -- is a multi-task learning model that couples the sentence-level segmentation objective with the coherence objective that differentiates correct sequences of sentences from corrupt ones. The proposed model, dubbed Coherence-Aware Text Segmentation (CATS), yields state-of-the-art segmentation performance on a collection of benchmark datasets. Furthermore, by coupling CATS with cross-lingual word embeddings, we demonstrate its effectiveness in zero-shot language transfer: it can successfully segment texts in languages unseen in training.