 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying Bias in Machine-generated Text Detection
Dec 10, 2025The meteoric rise in text generation capability has been accompanied by parallel growth in interest in machine-generated text detection: the capability to identify whether a given text was generated using a model or written by a person. While detection models show strong performance, they have the capacity to cause significant negative impacts. We explore potential biases in English machine-generated text detection systems. We curate a dataset of student essays and assess 16 different detection systems for bias across four attributes: gender, race/ethnicity, English-language learner (ELL) status, and economic status. We evaluate these attributes using regression-based models to determine the significance and power of the effects, as well as performing subgroup analysis. We find that while biases are generally inconsistent across systems, there are several key issues: several models tend to classify disadvantaged groups as machine-generated, ELL essays are more likely to be classified as machine-generated, economically disadvantaged students' essays are less likely to be classified as machine-generated, and non-White ELL essays are disproportionately classified as machine-generated relative to their White counterparts. Finally, we perform human annotation and find that while humans perform generally poorly at the detection task, they show no significant biases on the studied attributes.
Identifying Fairness Issues in Automatically Generated Testing Content
May 01, 2024
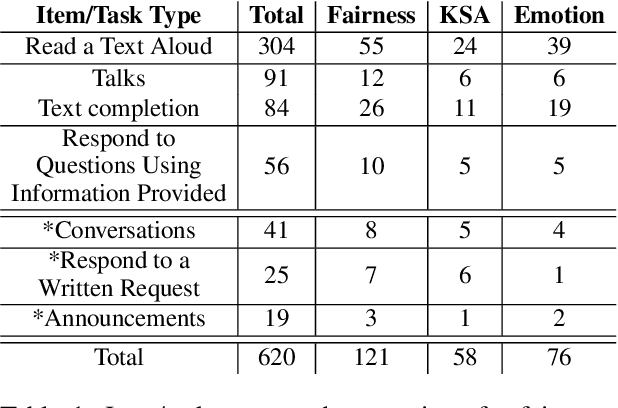
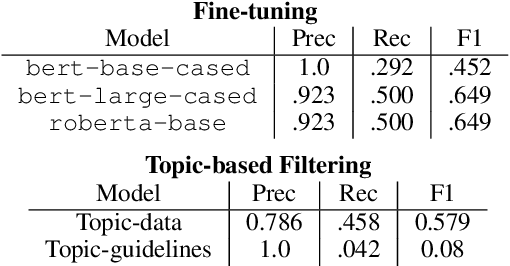
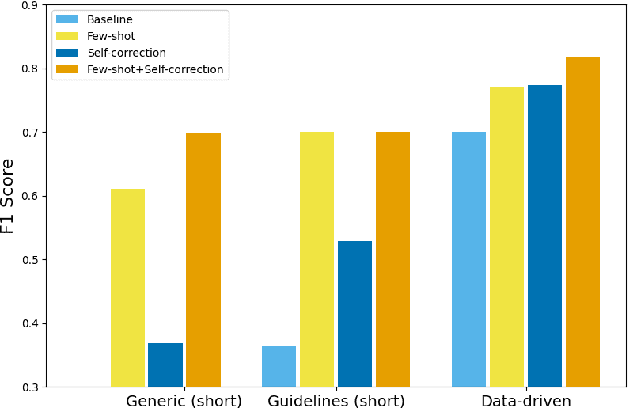
Natural language generation tools are powerful and effective for generating content. However, language models are known to display bias and fairness issues, making them impractical to deploy for many use cases. We here focus on how fairness issues impact automatically generated test content, which can have stringent requirements to ensure the test measures only what it was intended to measure. Specifically, we review test content generated for a large-scale standardized English proficiency test with the goal of identifying content that only pertains to a certain subset of the test population as well as content that has the potential to be upsetting or distracting to some test takers. Issues like these could inadvertently impact a test taker's score and thus should be avoided. This kind of content does not reflect the more commonly-acknowledged biases, making it challenging even for modern models that contain safeguards. We build a dataset of 601 generated texts annotated for fairness and explore a variety of methods for classification: fine-tuning, topic-based classification, and prompting, including few-shot and self-correcting prompts. We find that combining prompt self-correction and few-shot learning performs best, yielding an F1 score of 0.79 on our held-out test set, while much smaller BERT- and topic-based models have competitive performance on out-of-domain data.
Lessons Learned from a Citizen Science Project for Natural Language Processing
Apr 25, 2023



Many Natural Language Processing (NLP) systems use annotated corpora for training and evaluation. However, labeled data is often costly to obtain and scaling annotation projects is difficult, which is why annotation tasks are often outsourced to paid crowdworkers. Citizen Science is an alternative to crowdsourcing that is relatively unexplored in the context of NLP. To investigate whether and how well Citizen Science can be applied in this setting, we conduct an exploratory study into engaging different groups of volunteers in Citizen Science for NLP by re-annotating parts of a pre-existing crowdsourced dataset. Our results show that this can yield high-quality annotations and attract motivated volunteers, but also requires considering factors such as scalability, participation over time, and legal and ethical issues. We summarize lessons learned in the form of guidelines and provide our code and data to aid future work on Citizen Science.
Controlled Language Generation for Language Learning Items
Nov 28, 2022
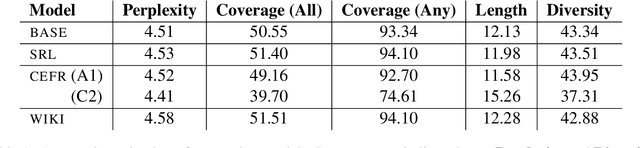


This work aims to employ natural language generation (NLG) to rapidly generate items for English language learning applications: this requires both language models capable of generating fluent, high-quality English, and to control the output of the generation to match the requirements of the relevant items. We experiment with deep pretrained models for this task, developing novel methods for controlling items for factors relevant in language learning: diverse sentences for different proficiency levels and argument structure to test grammar. Human evaluation demonstrates high grammatically scores for all models (3.4 and above out of 4), and higher length (24%) and complexity (9%) over the baseline for the advanced proficiency model. Our results show that we can achieve strong performance while adding additional control to ensure diverse, tailored content for individual users.
Metaphor Generation with Conceptual Mappings
Jun 02, 2021

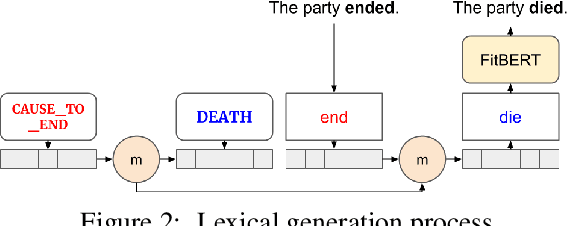
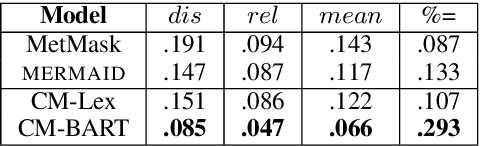
Generating metaphors is a difficult task as it requires understanding nuanced relationships between abstract concepts. In this paper, we aim to generate a metaphoric sentence given a literal expression by replacing relevant verbs. Guided by conceptual metaphor theory, we propose to control the generation process by encoding conceptual mappings between cognitive domains to generate meaningful metaphoric expressions. To achieve this, we develop two methods: 1) using FrameNet-based embeddings to learn mappings between domains and applying them at the lexical level (CM-Lex), and 2) deriving source/target pairs to train a controlled seq-to-seq generation model (CM-BART). We assess our methods through automatic and human evaluation for basic metaphoricity and conceptual metaphor presence. We show that the unsupervised CM-Lex model is competitive with recent deep learning metaphor generation systems, and CM-BART outperforms all other models both in automatic and human evaluations.
Combating Temporal Drift in Crisis with Adapted Embeddings
Apr 17, 2021

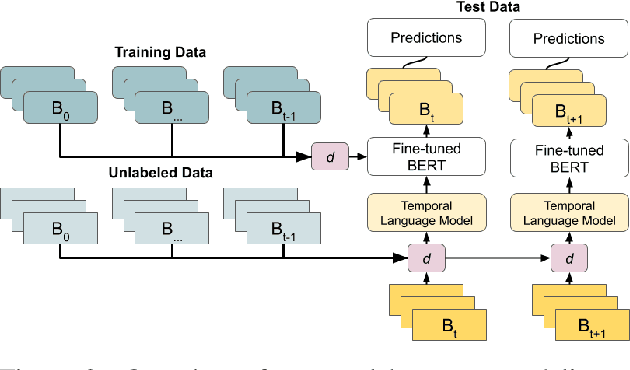

Language usage changes over time, and this can impact the effectiveness of NLP systems. This work investigates methods for adapting to changing discourse during crisis events. We explore social media data during crisis, for which effective, time-sensitive methods are necessary. We experiment with two separate methods to accommodate changing data: temporal pretraining, which uses unlabeled data for the target time periods to train better language models, and a model of embedding shift based on tools for analyzing semantic change. This shift allows us to counteract temporal drift by normalizing incoming data based on observed patterns of language change. Simulating scenarios in which we lack access to incoming labeled data, we demonstrate the effectiveness of these methods for a wide variety of crises, showing we can improve performance by up to 8.0 F1 score for relevance classification across datasets.
Ranking Creative Language Characteristics in Small Data Scenarios
Oct 23, 2020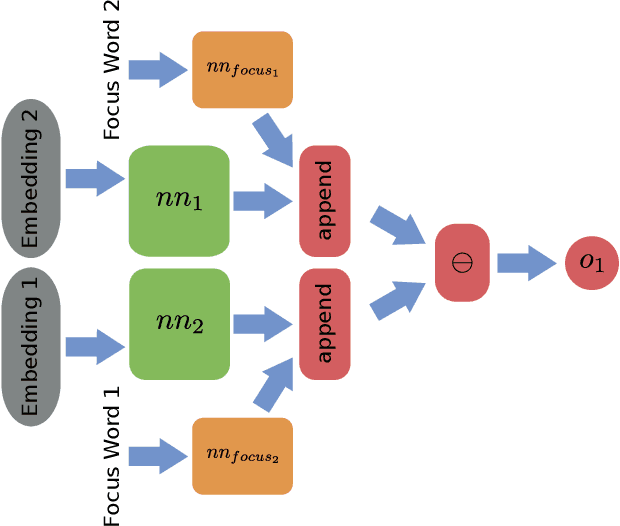
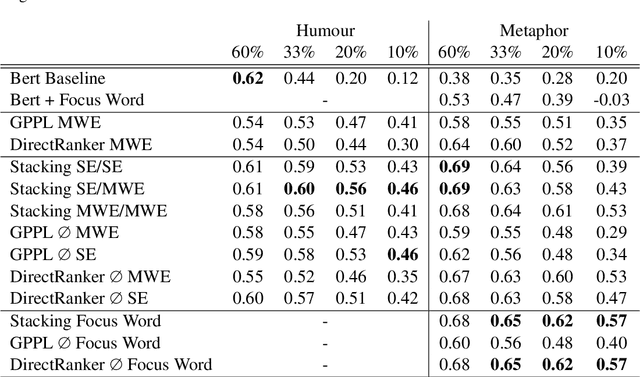
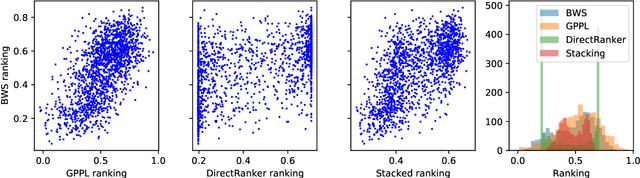
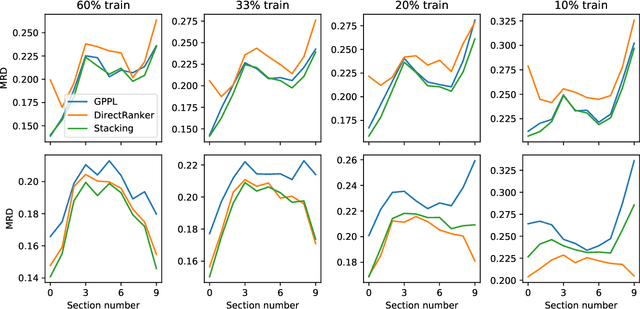
The ability to rank creative natural language provides an important general tool for downstream language understanding and generation. However, current deep ranking models require substantial amounts of labeled data that are difficult and expensive to obtain for different domains, languages and creative characteristics. A recent neural approach, the DirectRanker, promises to reduce the amount of training data needed but its application to text isn't fully explored. We therefore adapt the DirectRanker to provide a new deep model for ranking creative language with small data. We compare DirectRanker with a Bayesian approach, Gaussian process preference learning (GPPL), which has previously been shown to work well with sparse data. Our experiments with sparse training data show that while the performance of standard neural ranking approaches collapses with small training datasets, DirectRanker remains effective. We find that combining DirectRanker with GPPL increases performance across different settings by leveraging the complementary benefits of both models. Our combined approach outperforms the previous state-of-the-art on humor and metaphor novelty tasks, increasing Spearman's $\rho$ by 14% and 16% on average.
Metaphoric Paraphrase Generation
Feb 28, 2020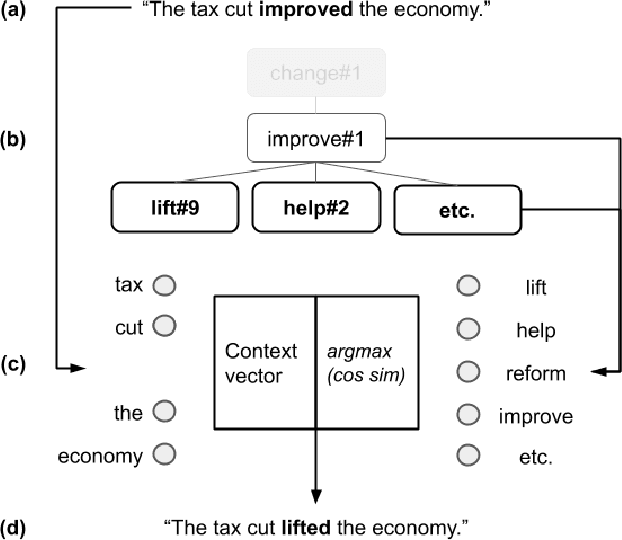
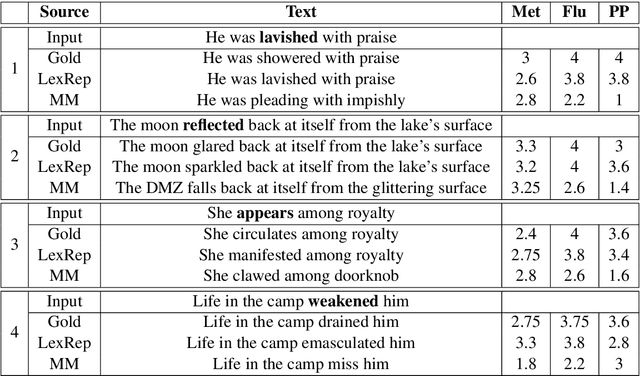
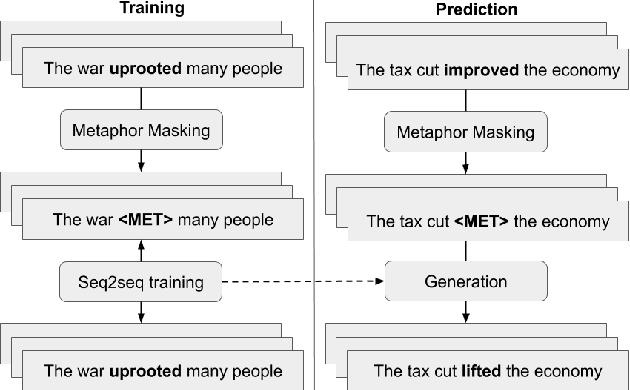
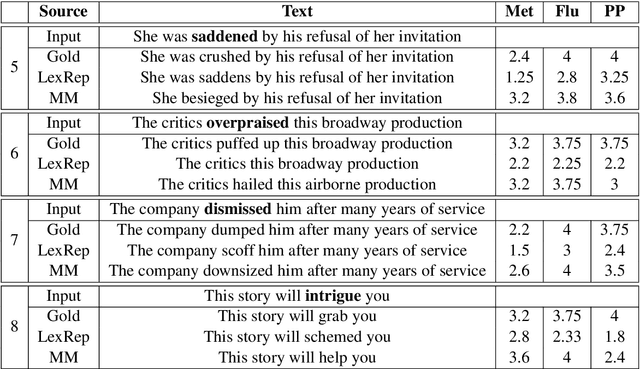
This work describes the task of metaphoric paraphrase generation, in which we are given a literal sentence and are charged with generating a metaphoric paraphrase. We propose two different models for this task: a lexical replacement baseline and a novel sequence to sequence model, 'metaphor masking', that generates free metaphoric paraphrases. We use crowdsourcing to evaluate our results, as well as developing an automatic metric for evaluating metaphoric paraphrases. We show that while the lexical replacement baseline is capable of producing accurate paraphrases, they often lack metaphoricity, while our metaphor masking model excels in generating metaphoric sentences while performing nearly as well with regard to fluency and paraphrase quality.