 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Generative Models of Evolution: SNP-level Population Adaptation by Genomic Linkage Incorporation
Jul 28, 2025The investigation of allele frequency trajectories in populations evolving under controlled environmental pressures has become a popular approach to study evolutionary processes on the molecular level. Statistical models based on well-defined evolutionary concepts can be used to validate different hypotheses about empirical observations. Despite their popularity, classic statistical models like the Wright-Fisher model suffer from simplified assumptions such as the independence of selected loci along a chromosome and uncertainty about the parameters. Deep generative neural networks offer a powerful alternative known for the integration of multivariate dependencies and noise reduction. Due to their high data demands and challenging interpretability they have, so far, not been widely considered in the area of population genomics. To address the challenges in the area of Evolve and Resequencing experiments (E&R) based on pooled sequencing (Pool-Seq) data, we introduce a deep generative neural network that aims to model a concept of evolution based on empirical observations over time. The proposed model estimates the distribution of allele frequency trajectories by embedding the observations from single nucleotide polymorphisms (SNPs) with information from neighboring loci. Evaluation on simulated E&R experiments demonstrates the model's ability to capture the distribution of allele frequency trajectories and illustrates the representational power of deep generative models on the example of linkage disequilibrium (LD) estimation. Inspecting the internally learned representations enables estimating pairwise LD, which is typically inaccessible in Pool-Seq data. Our model provides competitive LD estimation in Pool-Seq data high degree of LD when compared to existing methods.
Deep Unsupervised Identification of Selected SNPs between Adapted Populations on Pool-seq Data
Dec 28, 2020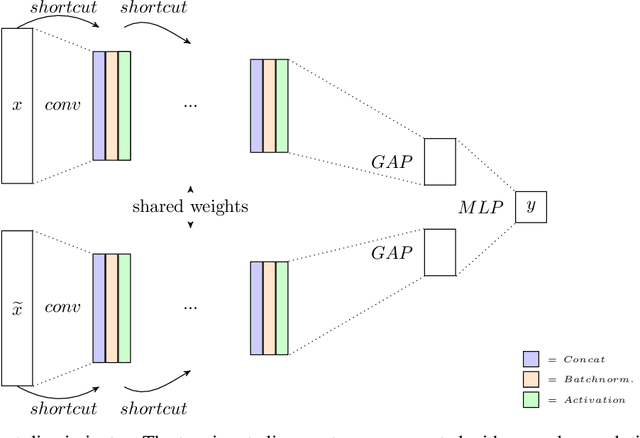
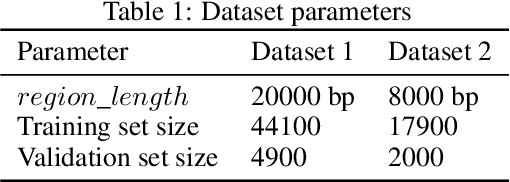
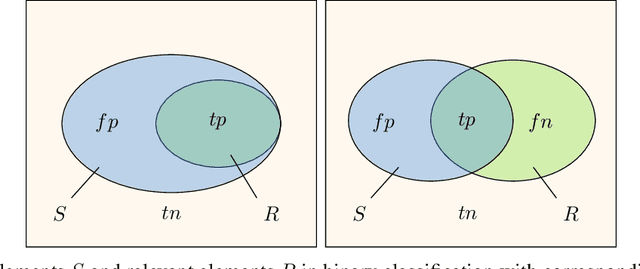
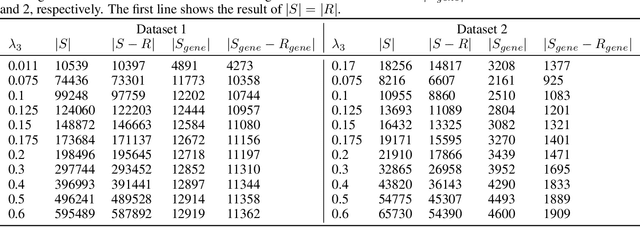
The exploration of selected single nucleotide polymorphisms (SNPs) to identify genetic diversity between different sequencing population pools (Pool-seq) is a fundamental task in genetic research. As underlying sequence reads and their alignment are error-prone and univariate statistical solutions only take individual positions of the genome into account, the identification of selected SNPs remains a challenging process. Deep learning models like convolutional neural networks (CNNs) are able to consider large input areas in their decisions. We suggest an unsupervised pipeline to be independent of a rarely known ground truth. We train a supervised discriminator CNN to distinguish alignments from different populations and utilize the model for unsupervised SNP calling by applying explainable artificial intelligence methods. Our proposed multivariate method is based on two main assumptions: We assume (i) that instances having a high predictive certainty of being distinguishable are likely to contain genetic variants, and (ii) that selected SNPs are located at regions with input features having the highest influence on the model's decision process. We directly compare our method with statistical results on two different Pool-seq datasets and show that our solution is able to extend statistical results.
Ranking Creative Language Characteristics in Small Data Scenarios
Oct 23, 2020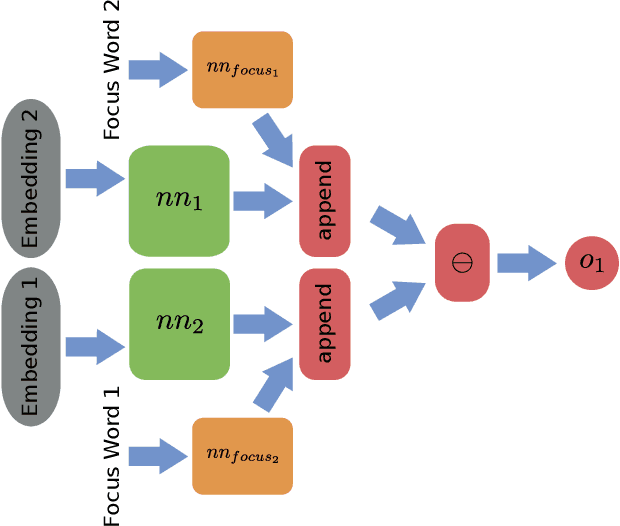
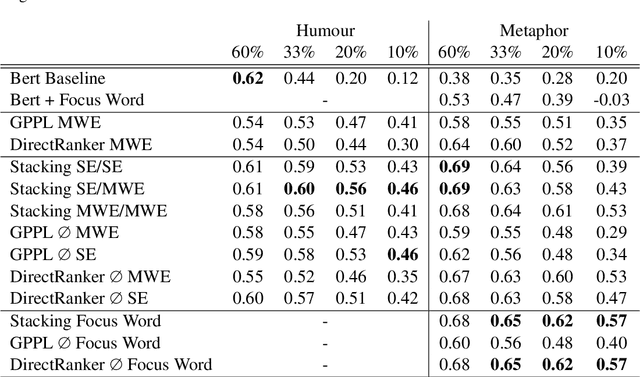
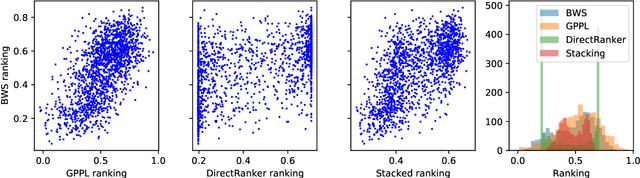
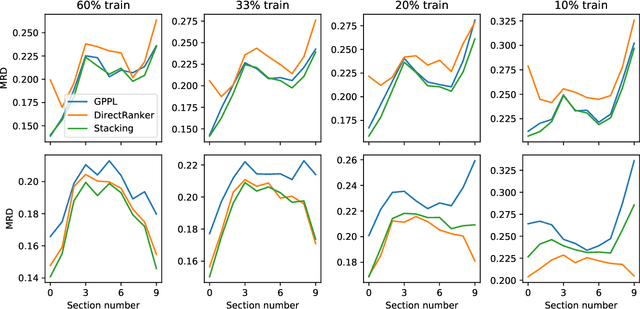
The ability to rank creative natural language provides an important general tool for downstream language understanding and generation. However, current deep ranking models require substantial amounts of labeled data that are difficult and expensive to obtain for different domains, languages and creative characteristics. A recent neural approach, the DirectRanker, promises to reduce the amount of training data needed but its application to text isn't fully explored. We therefore adapt the DirectRanker to provide a new deep model for ranking creative language with small data. We compare DirectRanker with a Bayesian approach, Gaussian process preference learning (GPPL), which has previously been shown to work well with sparse data. Our experiments with sparse training data show that while the performance of standard neural ranking approaches collapses with small training datasets, DirectRanker remains effective. We find that combining DirectRanker with GPPL increases performance across different settings by leveraging the complementary benefits of both models. Our combined approach outperforms the previous state-of-the-art on humor and metaphor novelty tasks, increasing Spearman's $\rho$ by 14% and 16% on average.