 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Unsupervised Identification of Selected SNPs between Adapted Populations on Pool-seq Data
Paper and Code
Dec 28, 2020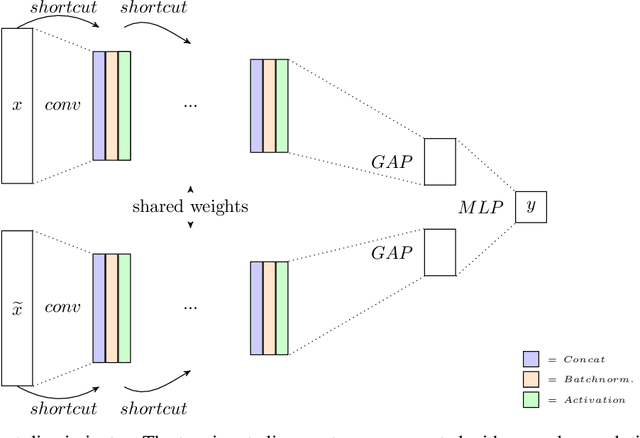
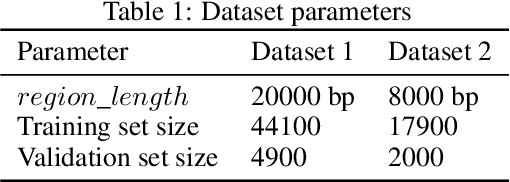
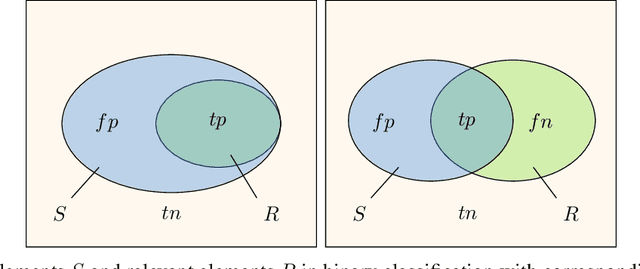
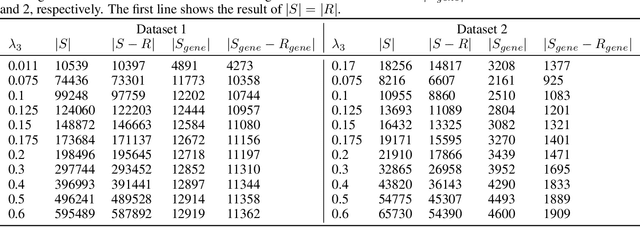
The exploration of selected single nucleotide polymorphisms (SNPs) to identify genetic diversity between different sequencing population pools (Pool-seq) is a fundamental task in genetic research. As underlying sequence reads and their alignment are error-prone and univariate statistical solutions only take individual positions of the genome into account, the identification of selected SNPs remains a challenging process. Deep learning models like convolutional neural networks (CNNs) are able to consider large input areas in their decisions. We suggest an unsupervised pipeline to be independent of a rarely known ground truth. We train a supervised discriminator CNN to distinguish alignments from different populations and utilize the model for unsupervised SNP calling by applying explainable artificial intelligence methods. Our proposed multivariate method is based on two main assumptions: We assume (i) that instances having a high predictive certainty of being distinguishable are likely to contain genetic variants, and (ii) that selected SNPs are located at regions with input features having the highest influence on the model's decision process. We directly compare our method with statistical results on two different Pool-seq datasets and show that our solution is able to extend statistical results.