 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeaching Language Models to Check Grounded Claim Factuality with Human Test-Taking Strategies
May 28, 2026Grounded claim factuality checking is important for large language model (LLM) applications such as retrieval-augmented generation, as it helps users assess the correctness of generated outputs. Existing metrics using entailment classifiers require dataset-specific threshold tuning, while LLM-based approaches often use direct prompting, which underutilises the reasoning capabilities of LLMs. We address this by formulating grounded claim factuality checking as a true/false reading comprehension task and prompting LLMs with explicit test-taking strategies for efficient reasoning. Our method reduces token usage by over 80% compared to unguided open-ended reasoning, and achieves competitive performance to more expensive alternatives across two factuality benchmarks, setting a new state of the art on one. To further reduce inference cost, we train small language models (SLMs) to replace LLMs in the checking pipeline. Using supervised fine-tuning (SFT) and a self-revision mechanism, the SLMs learn to improve their factuality judgements. Experimental results show that the resulting SLMs perform on par with strong baselines, combining low inference costs with generating supporting rationales to support interpretability. Code and datasets will be released upon acceptance.
Optimising Factual Consistency in Summarisation via Preference Learning from Multiple Imperfect Metrics
May 26, 2026Reinforcement learning with evaluation metrics as rewards is widely used to enhance specific capabilities of language models. However, for tasks such as factually consistent summarisation, existing metrics remain underdeveloped, limiting their effectiveness as signals for shaping model behaviour.While individual factuality metrics are unreliable, their combination can more effectively capture diverse factual errors. We leverage this insight to introduce an automated training pipeline that improves factual consistency in summaries by aggregating scores from different weak metrics. Our approach avoids the need for complex reward shaping by mapping scores to preferences and filtering out cases with high disagreement between metrics. For each source document, we generate lexically similar summary pairs by varying decoding strategies, enabling the model to learn from factual differences caused by subtle lexical differences. This approach constructs a high-quality preference dataset using only source documents.Experiments demonstrate consistent factuality gains across models, ranging from early encoder-decoder architectures to modern large language models, with smaller models reaching comparable factuality to larger ones.
Self-Supervised Animal Identification for Long Videos
Jan 14, 2026Identifying individual animals in long-duration videos is essential for behavioral ecology, wildlife monitoring, and livestock management. Traditional methods require extensive manual annotation, while existing self-supervised approaches are computationally demanding and ill-suited for long sequences due to memory constraints and temporal error propagation. We introduce a highly efficient, self-supervised method that reframes animal identification as a global clustering task rather than a sequential tracking problem. Our approach assumes a known, fixed number of individuals within a single video -- a common scenario in practice -- and requires only bounding box detections and the total count. By sampling pairs of frames, using a frozen pre-trained backbone, and employing a self-bootstrapping mechanism with the Hungarian algorithm for in-batch pseudo-label assignment, our method learns discriminative features without identity labels. We adapt a Binary Cross Entropy loss from vision-language models, enabling state-of-the-art accuracy ($>$97\%) while consuming less than 1 GB of GPU memory per batch -- an order of magnitude less than standard contrastive methods. Evaluated on challenging real-world datasets (3D-POP pigeons and 8-calves feeding videos), our framework matches or surpasses supervised baselines trained on over 1,000 labeled frames, effectively removing the manual annotation bottleneck. This work enables practical, high-accuracy animal identification on consumer-grade hardware, with broad applicability in resource-constrained research settings. All code written for this paper are \href{https://huggingface.co/datasets/tonyFang04/8-calves}{here}.
Clinically-aligned Multi-modal Chest X-ray Classification
Nov 12, 2025Radiology is essential to modern healthcare, yet rising demand and staffing shortages continue to pose major challenges. Recent advances in artificial intelligence have the potential to support radiologists and help address these challenges. Given its widespread use and clinical importance, chest X-ray classification is well suited to augment radiologists' workflows. However, most existing approaches rely solely on single-view, image-level inputs, ignoring the structured clinical information and multi-image studies available at the time of reporting. In this work, we introduce CaMCheX, a multimodal transformer-based framework that aligns multi-view chest X-ray studies with structured clinical data to better reflect how clinicians make diagnostic decisions. Our architecture employs view-specific ConvNeXt encoders for frontal and lateral chest radiographs, whose features are fused with clinical indications, history, and vital signs using a transformer fusion module. This design enables the model to generate context-aware representations that mirror reasoning in clinical practice. Our results exceed the state of the art for both the original MIMIC-CXR dataset and the more recent CXR-LT benchmarks, highlighting the value of clinically grounded multimodal alignment for advancing chest X-ray classification.
How well can LLMs Grade Essays in Arabic?
Jan 27, 2025This research assesses the effectiveness of state-of-the-art large language models (LLMs), including ChatGPT, Llama, Aya, Jais, and ACEGPT, in the task of Arabic automated essay scoring (AES) using the AR-AES dataset. It explores various evaluation methodologies, including zero-shot, few-shot in-context learning, and fine-tuning, and examines the influence of instruction-following capabilities through the inclusion of marking guidelines within the prompts. A mixed-language prompting strategy, integrating English prompts with Arabic content, was implemented to improve model comprehension and performance. Among the models tested, ACEGPT demonstrated the strongest performance across the dataset, achieving a Quadratic Weighted Kappa (QWK) of 0.67, but was outperformed by a smaller BERT-based model with a QWK of 0.88. The study identifies challenges faced by LLMs in processing Arabic, including tokenization complexities and higher computational demands. Performance variation across different courses underscores the need for adaptive models capable of handling diverse assessment formats and highlights the positive impact of effective prompt engineering on improving LLM outputs. To the best of our knowledge, this study is the first to empirically evaluate the performance of multiple generative Large Language Models (LLMs) on Arabic essays using authentic student data.
Out-of-Distribution Detection with Attention Head Masking for Multimodal Document Classification
Aug 20, 2024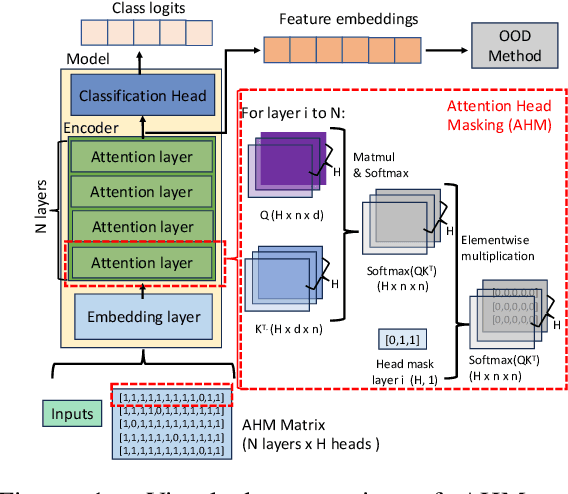
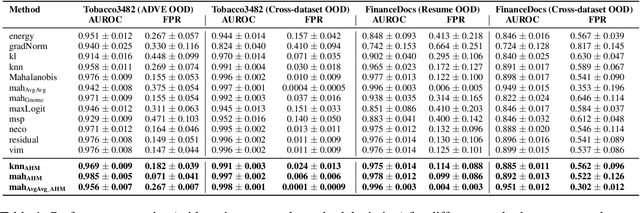

Detecting out-of-distribution (OOD) data is crucial in machine learning applications to mitigate the risk of model overconfidence, thereby enhancing the reliability and safety of deployed systems. The majority of existing OOD detection methods predominantly address uni-modal inputs, such as images or texts. In the context of multi-modal documents, there is a notable lack of extensive research on the performance of these methods, which have primarily been developed with a focus on computer vision tasks. We propose a novel methodology termed as attention head masking (AHM) for multi-modal OOD tasks in document classification systems. Our empirical results demonstrate that the proposed AHM method outperforms all state-of-the-art approaches and significantly decreases the false positive rate (FPR) compared to existing solutions up to 7.5\%. This methodology generalizes well to multi-modal data, such as documents, where visual and textual information are modeled under the same Transformer architecture. To address the scarcity of high-quality publicly available document datasets and encourage further research on OOD detection for documents, we introduce FinanceDocs, a new document AI dataset. Our code and dataset are publicly available.
Automated essay scoring in Arabic: a dataset and analysis of a BERT-based system
Jul 15, 2024Automated Essay Scoring (AES) holds significant promise in the field of education, helping educators to mark larger volumes of essays and provide timely feedback. However, Arabic AES research has been limited by the lack of publicly available essay data. This study introduces AR-AES, an Arabic AES benchmark dataset comprising 2046 undergraduate essays, including gender information, scores, and transparent rubric-based evaluation guidelines, providing comprehensive insights into the scoring process. These essays come from four diverse courses, covering both traditional and online exams. Additionally, we pioneer the use of AraBERT for AES, exploring its performance on different question types. We find encouraging results, particularly for Environmental Chemistry and source-dependent essay questions. For the first time, we examine the scale of errors made by a BERT-based AES system, observing that 96.15 percent of the errors are within one point of the first human marker's prediction, on a scale of one to five, with 79.49 percent of predictions matching exactly. In contrast, additional human markers did not exceed 30 percent exact matches with the first marker, with 62.9 percent within one mark. These findings highlight the subjectivity inherent in essay grading, and underscore the potential for current AES technology to assist human markers to grade consistently across large classes.
Automated Radiology Report Generation: A Review of Recent Advances
May 17, 2024Increasing demands on medical imaging departments are taking a toll on the radiologist's ability to deliver timely and accurate reports. Recent technological advances in artificial intelligence have demonstrated great potential for automatic radiology report generation (ARRG), sparking an explosion of research. This survey paper conducts a methodological review of contemporary ARRG approaches by way of (i) assessing datasets based on characteristics, such as availability, size, and adoption rate, (ii) examining deep learning training methods, such as contrastive learning and reinforcement learning, (iii) exploring state-of-the-art model architectures, including variations of CNN and transformer models, (iv) outlining techniques integrating clinical knowledge through multimodal inputs and knowledge graphs, and (v) scrutinising current model evaluation techniques, including commonly applied NLP metrics and qualitative clinical reviews. Furthermore, the quantitative results of the reviewed models are analysed, where the top performing models are examined to seek further insights. Finally, potential new directions are highlighted, with the adoption of additional datasets from other radiological modalities and improved evaluation methods predicted as important areas of future development.
Interactively Learning to Summarise Timelines by Reinforcement Learning
Nov 14, 2022



Timeline summarisation (TLS) aims to create a time-ordered summary list concisely describing a series of events with corresponding dates. This differs from general summarisation tasks because it requires the method to capture temporal information besides the main idea of the input documents. This paper proposes a TLS system which can interactively learn from the user's feedback via reinforcement learning and generate timelines satisfying the user's interests. We define a compound reward function that can update automatically according to the received feedback through interaction with the user. The system utilises the reward function to fine-tune an abstractive summarisation model via reinforcement learning to guarantee topical coherence, factual consistency and linguistic fluency of the generated summaries. The proposed system avoids the need of preference feedback from individual users. The experiments show that our system outperforms the baseline on the benchmark TLS dataset and can generate accurate and timeline precises that better satisfy real users.
Ranking Scientific Papers Using Preference Learning
Sep 02, 2021
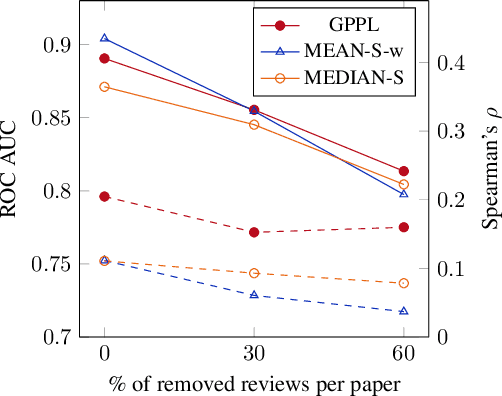
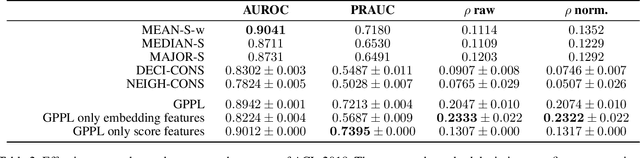
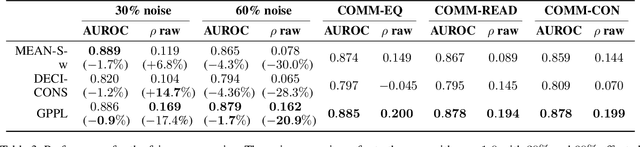
Peer review is the main quality control mechanism in academia. Quality of scientific work has many dimensions; coupled with the subjective nature of the reviewing task, this makes final decision making based on the reviews and scores therein very difficult and time-consuming. To assist with this important task, we cast it as a paper ranking problem based on peer review texts and reviewer scores. We introduce a novel, multi-faceted generic evaluation framework for making final decisions based on peer reviews that takes into account effectiveness, efficiency and fairness of the evaluated system. We propose a novel approach to paper ranking based on Gaussian Process Preference Learning (GPPL) and evaluate it on peer review data from the ACL-2018 conference. Our experiments demonstrate the superiority of our GPPL-based approach over prior work, while highlighting the importance of using both texts and review scores for paper ranking during peer review aggregation.