 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransforming Science with Large Language Models: A Survey on AI-assisted Scientific Discovery, Experimentation, Content Generation, and Evaluation
Feb 07, 2025
With the advent of large multimodal language models, science is now at a threshold of an AI-based technological transformation. Recently, a plethora of new AI models and tools has been proposed, promising to empower researchers and academics worldwide to conduct their research more effectively and efficiently. This includes all aspects of the research cycle, especially (1) searching for relevant literature; (2) generating research ideas and conducting experimentation; generating (3) text-based and (4) multimodal content (e.g., scientific figures and diagrams); and (5) AI-based automatic peer review. In this survey, we provide an in-depth overview over these exciting recent developments, which promise to fundamentally alter the scientific research process for good. Our survey covers the five aspects outlined above, indicating relevant datasets, methods and results (including evaluation) as well as limitations and scope for future research. Ethical concerns regarding shortcomings of these tools and potential for misuse (fake science, plagiarism, harms to research integrity) take a particularly prominent place in our discussion. We hope that our survey will not only become a reference guide for newcomers to the field but also a catalyst for new AI-based initiatives in the area of "AI4Science".
OFAI-UKP at HAHA@IberLEF2019: Predicting the Humorousness of Tweets Using Gaussian Process Preference Learning
Aug 03, 2020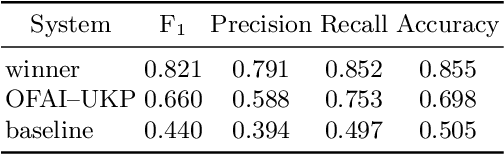
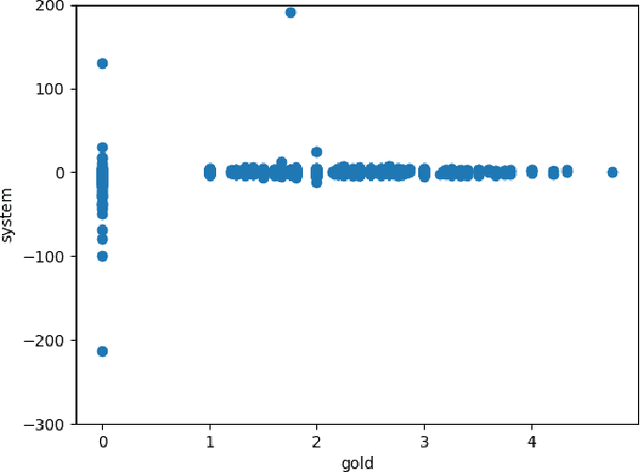
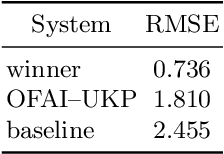
Most humour processing systems to date make at best discrete, coarse-grained distinctions between the comical and the conventional, yet such notions are better conceptualized as a broad spectrum. In this paper, we present a probabilistic approach, a variant of Gaussian process preference learning (GPPL), that learns to rank and rate the humorousness of short texts by exploiting human preference judgments and automatically sourced linguistic annotations. We apply our system, which had previously shown good performance on English-language one-liners annotated with pairwise humorousness annotations, to the Spanish-language data set of the HAHA@IberLEF2019 evaluation campaign. We report system performance for the campaign's two subtasks, humour detection and funniness score prediction, and discuss some issues arising from the conversion between the numeric scores used in the HAHA@IberLEF2019 data and the pairwise judgment annotations required for our method.
* 11 pages, 1 figure
Cross-topic Argument Mining from Heterogeneous Sources Using Attention-based Neural Networks
Feb 15, 2018
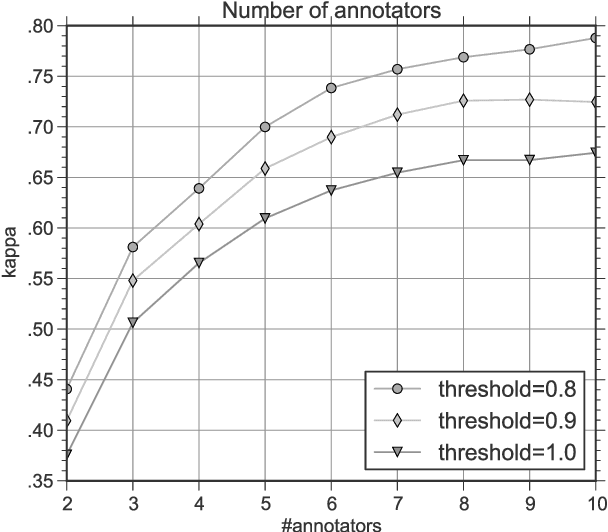
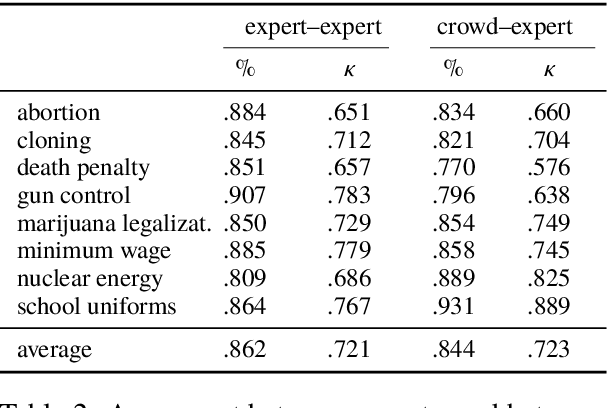
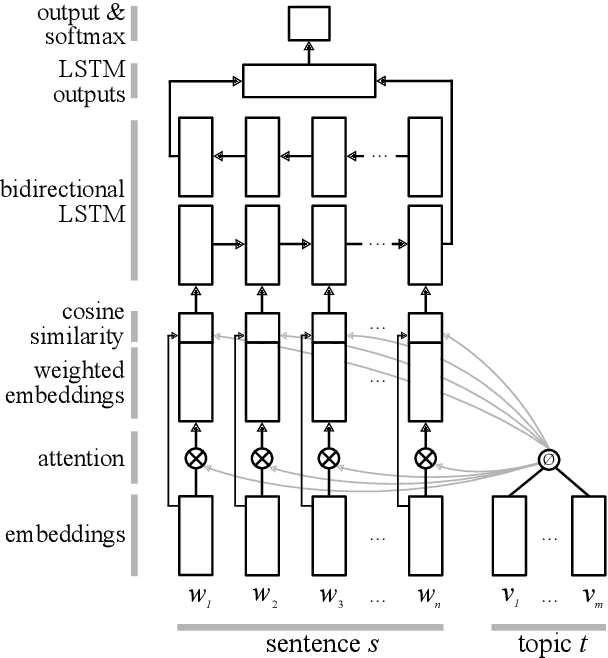
Argument mining is a core technology for automating argument search in large document collections. Despite its usefulness for this task, most current approaches to argument mining are designed for use only with specific text types and fall short when applied to heterogeneous texts. In this paper, we propose a new sentential annotation scheme that is reliably applicable by crowd workers to arbitrary Web texts. We source annotations for over 25,000 instances covering eight controversial topics. The results of cross-topic experiments show that our attention-based neural network generalizes best to unseen topics and outperforms vanilla BiLSTM models by 6% in accuracy and 11% in F-score.