 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOFAI-UKP at HAHA@IberLEF2019: Predicting the Humorousness of Tweets Using Gaussian Process Preference Learning
Aug 03, 2020
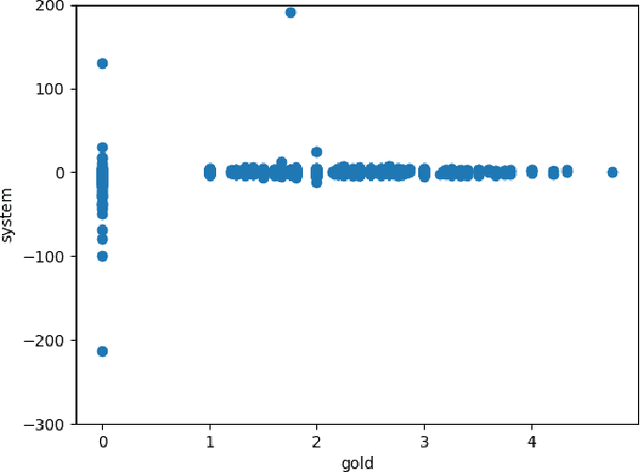
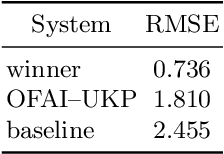
Most humour processing systems to date make at best discrete, coarse-grained distinctions between the comical and the conventional, yet such notions are better conceptualized as a broad spectrum. In this paper, we present a probabilistic approach, a variant of Gaussian process preference learning (GPPL), that learns to rank and rate the humorousness of short texts by exploiting human preference judgments and automatically sourced linguistic annotations. We apply our system, which had previously shown good performance on English-language one-liners annotated with pairwise humorousness annotations, to the Spanish-language data set of the HAHA@IberLEF2019 evaluation campaign. We report system performance for the campaign's two subtasks, humour detection and funniness score prediction, and discuss some issues arising from the conversion between the numeric scores used in the HAHA@IberLEF2019 data and the pairwise judgment annotations required for our method.
* 11 pages, 1 figure
EELECTION at SemEval-2017 Task 10: Ensemble of nEural Learners for kEyphrase ClassificaTION
Apr 10, 2017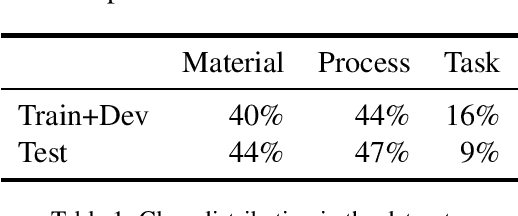
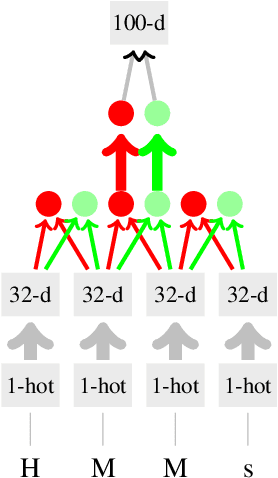
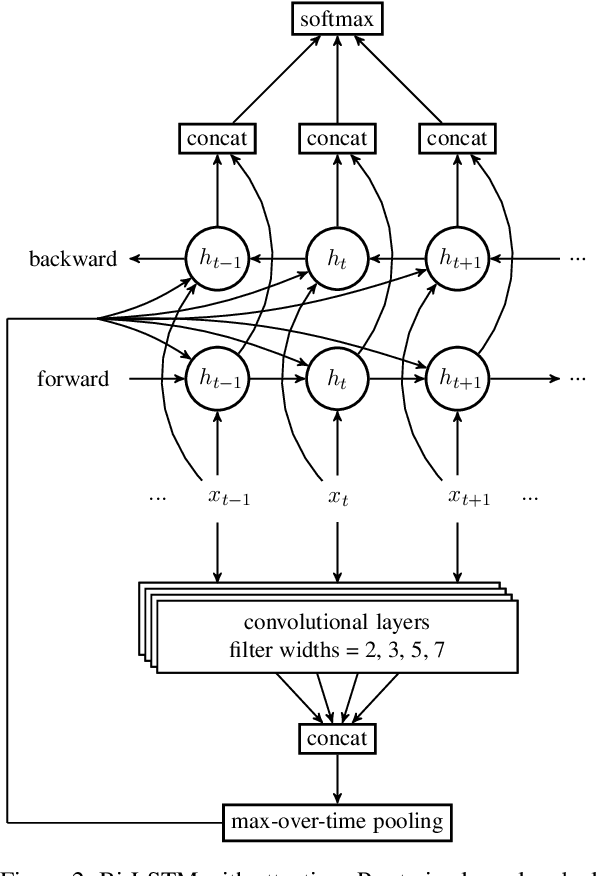
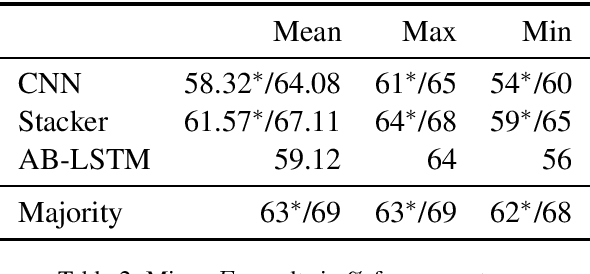
This paper describes our approach to the SemEval 2017 Task 10: "Extracting Keyphrases and Relations from Scientific Publications", specifically to Subtask (B): "Classification of identified keyphrases". We explored three different deep learning approaches: a character-level convolutional neural network (CNN), a stacked learner with an MLP meta-classifier, and an attention based Bi-LSTM. From these approaches, we created an ensemble of differently hyper-parameterized systems, achieving a micro-F1-score of 0.63 on the test data. Our approach ranks 2nd (score of 1st placed system: 0.64) out of four according to this official score. However, we erroneously trained 2 out of 3 neural nets (the stacker and the CNN) on only roughly 15% of the full data, namely, the original development set. When trained on the full data (training+development), our ensemble has a micro-F1-score of 0.69. Our code is available from https://github.com/UKPLab/semeval2017-scienceie.
Still not there? Comparing Traditional Sequence-to-Sequence Models to Encoder-Decoder Neural Networks on Monotone String Translation Tasks
Oct 26, 2016
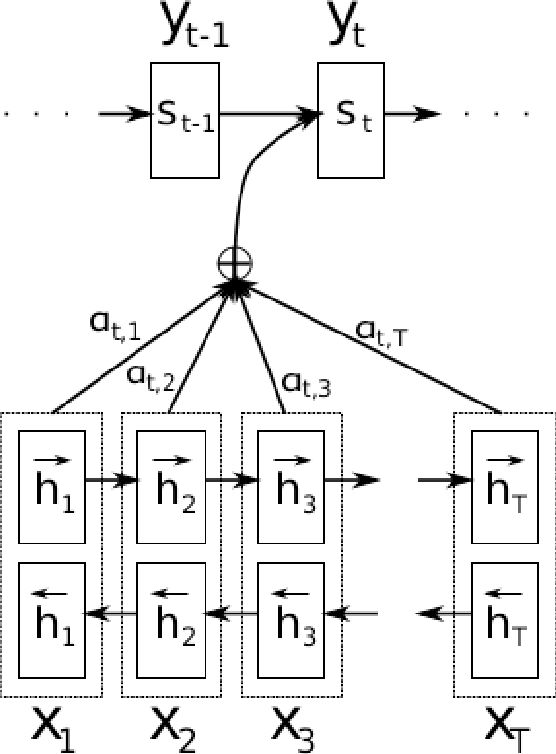
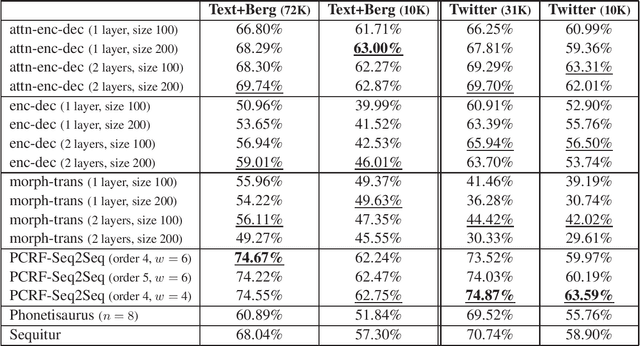
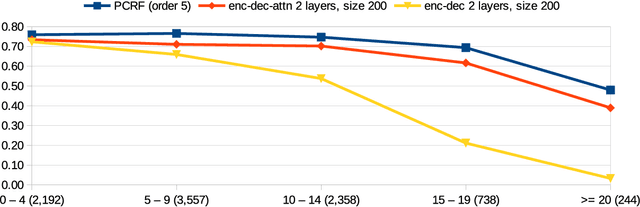
We analyze the performance of encoder-decoder neural models and compare them with well-known established methods. The latter represent different classes of traditional approaches that are applied to the monotone sequence-to-sequence tasks OCR post-correction, spelling correction, grapheme-to-phoneme conversion, and lemmatization. Such tasks are of practical relevance for various higher-level research fields including digital humanities, automatic text correction, and speech recognition. We investigate how well generic deep-learning approaches adapt to these tasks, and how they perform in comparison with established and more specialized methods, including our own adaptation of pruned CRFs.