Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStill not there? Comparing Traditional Sequence-to-Sequence Models to Encoder-Decoder Neural Networks on Monotone String Translation Tasks
Paper and Code

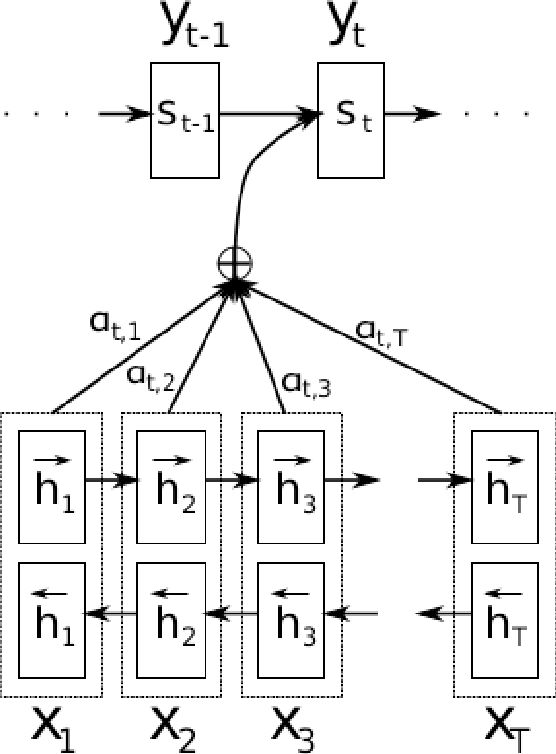
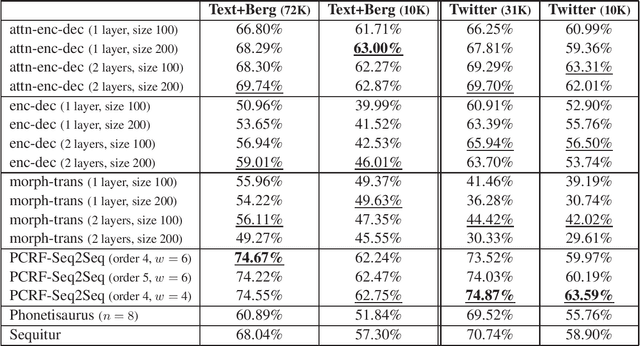
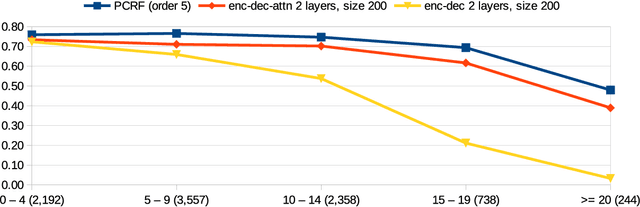
We analyze the performance of encoder-decoder neural models and compare them with well-known established methods. The latter represent different classes of traditional approaches that are applied to the monotone sequence-to-sequence tasks OCR post-correction, spelling correction, grapheme-to-phoneme conversion, and lemmatization. Such tasks are of practical relevance for various higher-level research fields including digital humanities, automatic text correction, and speech recognition. We investigate how well generic deep-learning approaches adapt to these tasks, and how they perform in comparison with established and more specialized methods, including our own adaptation of pruned CRFs.
* Accepted for publication at COLING 2016. See also:
https://www.ukp.tu-darmstadt.de/publications/details/?no_cache=1&tx_bibtex_pi1%5Bpub_id%5D=TUD-CS-2016-1450
Version 2: corrected spelling of third author
View paper on