 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEELECTION at SemEval-2017 Task 10: Ensemble of nEural Learners for kEyphrase ClassificaTION
Apr 10, 2017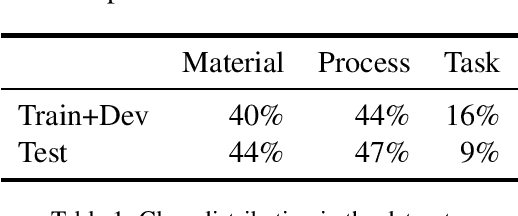
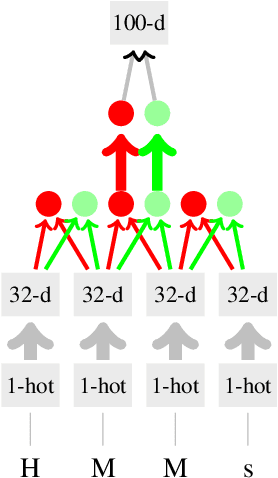
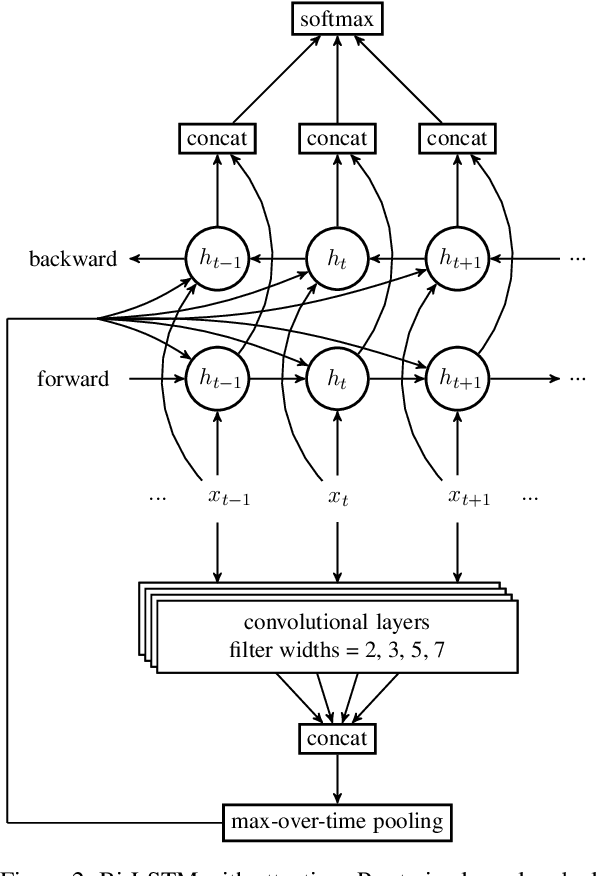
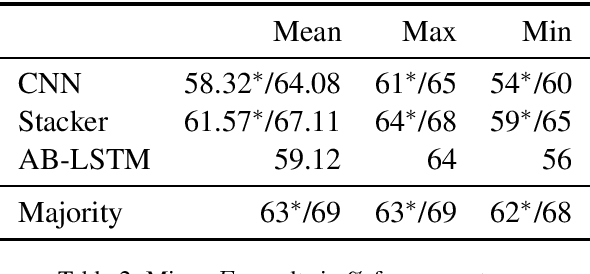
This paper describes our approach to the SemEval 2017 Task 10: "Extracting Keyphrases and Relations from Scientific Publications", specifically to Subtask (B): "Classification of identified keyphrases". We explored three different deep learning approaches: a character-level convolutional neural network (CNN), a stacked learner with an MLP meta-classifier, and an attention based Bi-LSTM. From these approaches, we created an ensemble of differently hyper-parameterized systems, achieving a micro-F1-score of 0.63 on the test data. Our approach ranks 2nd (score of 1st placed system: 0.64) out of four according to this official score. However, we erroneously trained 2 out of 3 neural nets (the stacker and the CNN) on only roughly 15% of the full data, namely, the original development set. When trained on the full data (training+development), our ensemble has a micro-F1-score of 0.69. Our code is available from https://github.com/UKPLab/semeval2017-scienceie.
Graph-Based Semi-Supervised Conditional Random Fields For Spoken Language Understanding Using Unaligned Data
Jan 30, 2017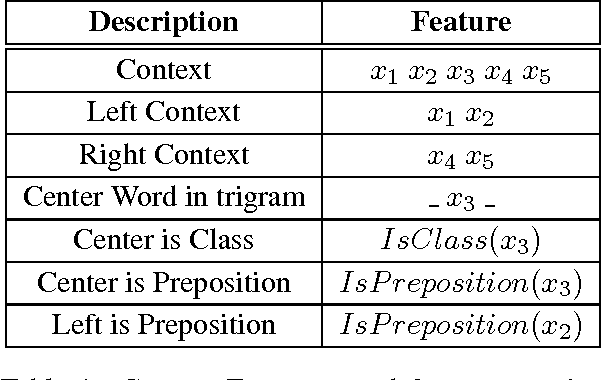
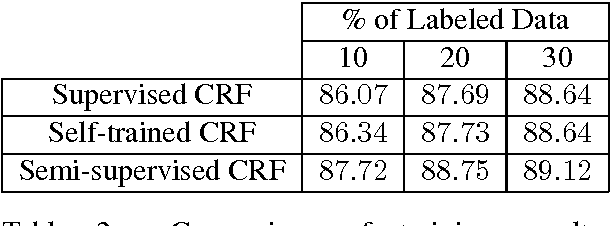
We experiment graph-based Semi-Supervised Learning (SSL) of Conditional Random Fields (CRF) for the application of Spoken Language Understanding (SLU) on unaligned data. The aligned labels for examples are obtained using IBM Model. We adapt a baseline semi-supervised CRF by defining new feature set and altering the label propagation algorithm. Our results demonstrate that our proposed approach significantly improves the performance of the supervised model by utilizing the knowledge gained from the graph.