 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrankenMotion: Part-level Human Motion Generation and Composition
Jan 15, 2026Human motion generation from text prompts has made remarkable progress in recent years. However, existing methods primarily rely on either sequence-level or action-level descriptions due to the absence of fine-grained, part-level motion annotations. This limits their controllability over individual body parts. In this work, we construct a high-quality motion dataset with atomic, temporally-aware part-level text annotations, leveraging the reasoning capabilities of large language models (LLMs). Unlike prior datasets that either provide synchronized part captions with fixed time segments or rely solely on global sequence labels, our dataset captures asynchronous and semantically distinct part movements at fine temporal resolution. Based on this dataset, we introduce a diffusion-based part-aware motion generation framework, namely FrankenMotion, where each body part is guided by its own temporally-structured textual prompt. This is, to our knowledge, the first work to provide atomic, temporally-aware part-level motion annotations and have a model that allows motion generation with both spatial (body part) and temporal (atomic action) control. Experiments demonstrate that FrankenMotion outperforms all previous baseline models adapted and retrained for our setting, and our model can compose motions unseen during training. Our code and dataset will be publicly available upon publication.
Beyond Demographics: Enhancing Cultural Value Survey Simulation with Multi-Stage Personality-Driven Cognitive Reasoning
Aug 25, 2025



Introducing MARK, the Multi-stAge Reasoning frameworK for cultural value survey response simulation, designed to enhance the accuracy, steerability, and interpretability of large language models in this task. The system is inspired by the type dynamics theory in the MBTI psychological framework for personality research. It effectively predicts and utilizes human demographic information for simulation: life-situational stress analysis, group-level personality prediction, and self-weighted cognitive imitation. Experiments on the World Values Survey show that MARK outperforms existing baselines by 10% accuracy and reduces the divergence between model predictions and human preferences. This highlights the potential of our framework to improve zero-shot personalization and help social scientists interpret model predictions.
MDPO: Overcoming the Training-Inference Divide of Masked Diffusion Language Models
Aug 18, 2025Diffusion language models, as a promising alternative to traditional autoregressive (AR) models, enable faster generation and richer conditioning on bidirectional context. However, they suffer from a key discrepancy between training and inference: during inference, MDLMs progressively reveal the structure of the generated sequence by producing fewer and fewer masked tokens, whereas this structure is ignored in training as tokens are masked at random. Although this discrepancy between training and inference can lead to suboptimal performance, it has been largely overlooked by previous works, leaving closing this gap between the two stages an open problem. To address this, we frame the problem of learning effective denoising trajectories as a sequential decision-making problem and use the resulting framework to apply reinforcement learning. We propose a novel Masked Diffusion Policy Optimization (MDPO) to exploit the Markov property diffusion possesses and explicitly train the model under the same progressive refining schedule used at inference. MDPO matches the performance of the previous state-of-the-art (SOTA) method with 60x fewer gradient updates, while achieving average improvements of 9.6% on MATH500 and 54.2% on Countdown over SOTA when trained within the same number of weight updates. Additionally, we improve the remasking strategy of MDLMs as a plug-in inference replacement to overcome the limitation that the model cannot refine tokens flexibly. This simple yet effective training-free strategy, what we refer to as RCR, consistently improves performance and yields additional gains when combined with MDPO. Our findings establish great potential for investigating the discrepancy between pre-training and inference of MDLMs. Code: https://github.com/autonomousvision/mdpo. Project Page: https://cli212.github.io/MDPO/.
QuaDMix: Quality-Diversity Balanced Data Selection for Efficient LLM Pretraining
Apr 23, 2025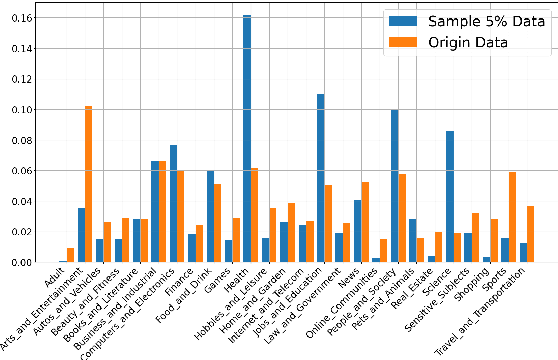
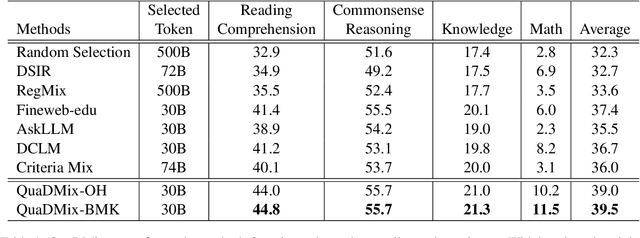
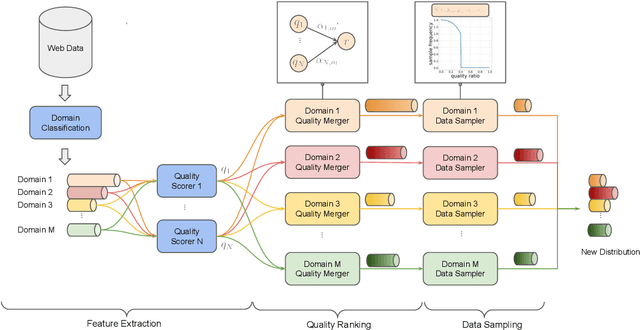

Quality and diversity are two critical metrics for the training data of large language models (LLMs), positively impacting performance. Existing studies often optimize these metrics separately, typically by first applying quality filtering and then adjusting data proportions. However, these approaches overlook the inherent trade-off between quality and diversity, necessitating their joint consideration. Given a fixed training quota, it is essential to evaluate both the quality of each data point and its complementary effect on the overall dataset. In this paper, we introduce a unified data selection framework called QuaDMix, which automatically optimizes the data distribution for LLM pretraining while balancing both quality and diversity. Specifically, we first propose multiple criteria to measure data quality and employ domain classification to distinguish data points, thereby measuring overall diversity. QuaDMix then employs a unified parameterized data sampling function that determines the sampling probability of each data point based on these quality and diversity related labels. To accelerate the search for the optimal parameters involved in the QuaDMix framework, we conduct simulated experiments on smaller models and use LightGBM for parameters searching, inspired by the RegMix method. Our experiments across diverse models and datasets demonstrate that QuaDMix achieves an average performance improvement of 7.2% across multiple benchmarks. These results outperform the independent strategies for quality and diversity, highlighting the necessity and ability to balance data quality and diversity.
Scholar Inbox: Personalized Paper Recommendations for Scientists
Apr 11, 2025
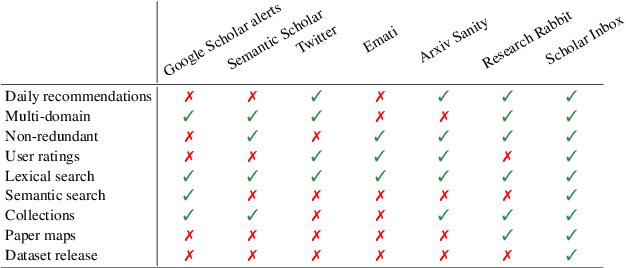

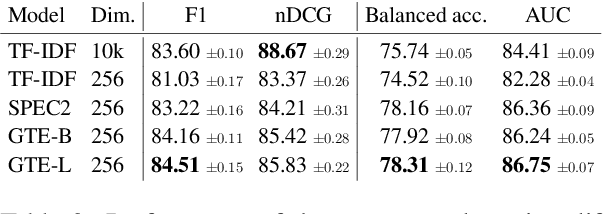
Scholar Inbox is a new open-access platform designed to address the challenges researchers face in staying current with the rapidly expanding volume of scientific literature. We provide personalized recommendations, continuous updates from open-access archives (arXiv, bioRxiv, etc.), visual paper summaries, semantic search, and a range of tools to streamline research workflows and promote open research access. The platform's personalized recommendation system is trained on user ratings, ensuring that recommendations are tailored to individual researchers' interests. To further enhance the user experience, Scholar Inbox also offers a map of science that provides an overview of research across domains, enabling users to easily explore specific topics. We use this map to address the cold start problem common in recommender systems, as well as an active learning strategy that iteratively prompts users to rate a selection of papers, allowing the system to learn user preferences quickly. We evaluate the quality of our recommendation system on a novel dataset of 800k user ratings, which we make publicly available, as well as via an extensive user study. https://www.scholar-inbox.com/
Specializing Large Language Models to Simulate Survey Response Distributions for Global Populations
Feb 10, 2025Large-scale surveys are essential tools for informing social science research and policy, but running surveys is costly and time-intensive. If we could accurately simulate group-level survey results, this would therefore be very valuable to social science research. Prior work has explored the use of large language models (LLMs) for simulating human behaviors, mostly through prompting. In this paper, we are the first to specialize LLMs for the task of simulating survey response distributions. As a testbed, we use country-level results from two global cultural surveys. We devise a fine-tuning method based on first-token probabilities to minimize divergence between predicted and actual response distributions for a given question. Then, we show that this method substantially outperforms other methods and zero-shot classifiers, even on unseen questions, countries, and a completely unseen survey. While even our best models struggle with the task, especially on unseen questions, our results demonstrate the benefits of specialization for simulation, which may accelerate progress towards sufficiently accurate simulation in the future.
Transforming Science with Large Language Models: A Survey on AI-assisted Scientific Discovery, Experimentation, Content Generation, and Evaluation
Feb 07, 2025
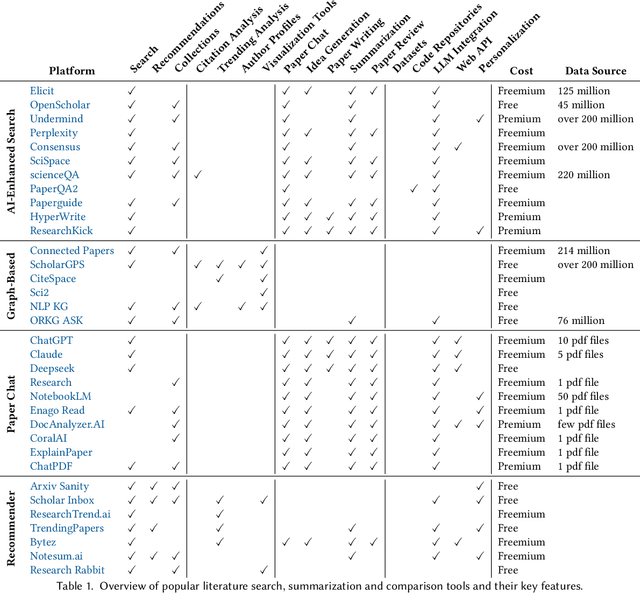
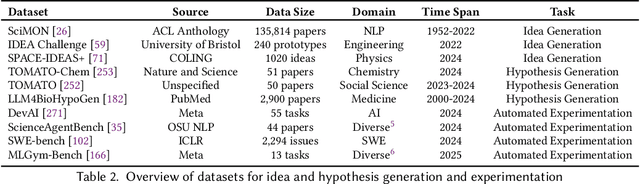
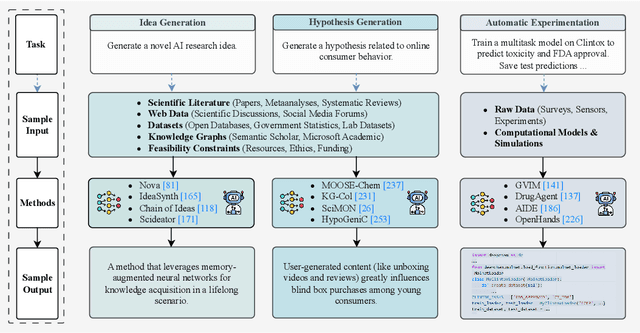
With the advent of large multimodal language models, science is now at a threshold of an AI-based technological transformation. Recently, a plethora of new AI models and tools has been proposed, promising to empower researchers and academics worldwide to conduct their research more effectively and efficiently. This includes all aspects of the research cycle, especially (1) searching for relevant literature; (2) generating research ideas and conducting experimentation; generating (3) text-based and (4) multimodal content (e.g., scientific figures and diagrams); and (5) AI-based automatic peer review. In this survey, we provide an in-depth overview over these exciting recent developments, which promise to fundamentally alter the scientific research process for good. Our survey covers the five aspects outlined above, indicating relevant datasets, methods and results (including evaluation) as well as limitations and scope for future research. Ethical concerns regarding shortcomings of these tools and potential for misuse (fake science, plagiarism, harms to research integrity) take a particularly prominent place in our discussion. We hope that our survey will not only become a reference guide for newcomers to the field but also a catalyst for new AI-based initiatives in the area of "AI4Science".
Vote&Mix: Plug-and-Play Token Reduction for Efficient Vision Transformer
Aug 30, 2024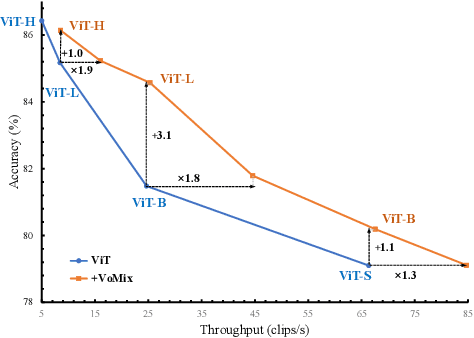
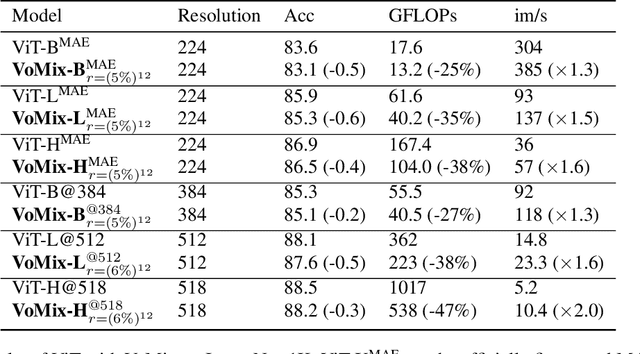
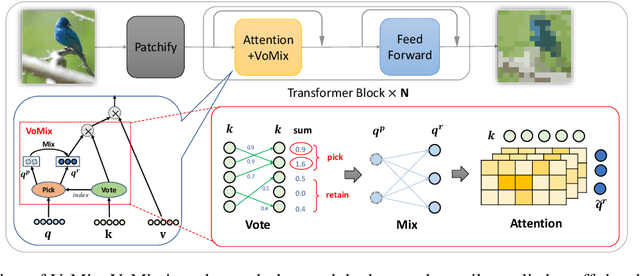
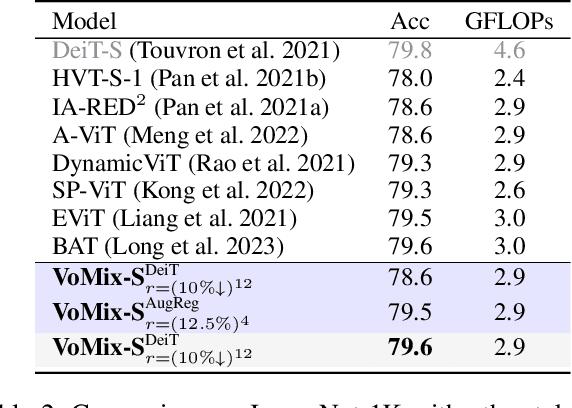
Despite the remarkable success of Vision Transformers (ViTs) in various visual tasks, they are often hindered by substantial computational cost. In this work, we introduce Vote\&Mix (\textbf{VoMix}), a plug-and-play and parameter-free token reduction method, which can be readily applied to off-the-shelf ViT models \textit{without any training}. VoMix tackles the computational redundancy of ViTs by identifying tokens with high homogeneity through a layer-wise token similarity voting mechanism. Subsequently, the selected tokens are mixed into the retained set, thereby preserving visual information. Experiments demonstrate VoMix significantly improves the speed-accuracy tradeoff of ViTs on both images and videos. Without any training, VoMix achieves a 2$\times$ increase in throughput of existing ViT-H on ImageNet-1K and a 2.4$\times$ increase in throughput of existing ViT-L on Kinetics-400 video dataset, with a mere 0.3\% drop in top-1 accuracy.
Vision-Language Models under Cultural and Inclusive Considerations
Jul 08, 2024



Large vision-language models (VLMs) can assist visually impaired people by describing images from their daily lives. Current evaluation datasets may not reflect diverse cultural user backgrounds or the situational context of this use case. To address this problem, we create a survey to determine caption preferences and propose a culture-centric evaluation benchmark by filtering VizWiz, an existing dataset with images taken by people who are blind. We then evaluate several VLMs, investigating their reliability as visual assistants in a culturally diverse setting. While our results for state-of-the-art models are promising, we identify challenges such as hallucination and misalignment of automatic evaluation metrics with human judgment. We make our survey, data, code, and model outputs publicly available.
Rethinking the Effectiveness of Graph Classification Datasets in Benchmarks for Assessing GNNs
Jul 06, 2024Graph classification benchmarks, vital for assessing and developing graph neural networks (GNNs), have recently been scrutinized, as simple methods like MLPs have demonstrated comparable performance. This leads to an important question: Do these benchmarks effectively distinguish the advancements of GNNs over other methodologies? If so, how do we quantitatively measure this effectiveness? In response, we first propose an empirical protocol based on a fair benchmarking framework to investigate the performance discrepancy between simple methods and GNNs. We further propose a novel metric to quantify the dataset effectiveness by considering both dataset complexity and model performance. To the best of our knowledge, our work is the first to thoroughly study and provide an explicit definition for dataset effectiveness in the graph learning area. Through testing across 16 real-world datasets, we found our metric to align with existing studies and intuitive assumptions. Finally, we explore the causes behind the low effectiveness of certain datasets by investigating the correlation between intrinsic graph properties and class labels, and we developed a novel technique supporting the correlation-controllable synthetic dataset generation. Our findings shed light on the current understanding of benchmark datasets, and our new platform could fuel the future evolution of graph classification benchmarks.