 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Precision Graph Neural Quantization for Low Bit Large Language Models
Jan 30, 2025
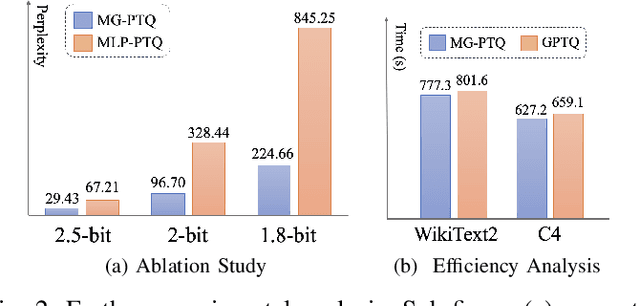

Post-Training Quantization (PTQ) is pivotal for deploying large language models (LLMs) within resource-limited settings by significantly reducing resource demands. However, existing PTQ strategies underperform at low bit levels < 3 bits due to the significant difference between the quantized and original weights. To enhance the quantization performance at low bit widths, we introduce a Mixed-precision Graph Neural PTQ (MG-PTQ) approach, employing a graph neural network (GNN) module to capture dependencies among weights and adaptively assign quantization bit-widths. Through the information propagation of the GNN module, our method more effectively captures dependencies among target weights, leading to a more accurate assessment of weight importance and optimized allocation of quantization strategies. Extensive experiments on the WikiText2 and C4 datasets demonstrate that our MG-PTQ method outperforms previous state-of-the-art PTQ method GPTQ, setting new benchmarks for quantization performance under low-bit conditions.
A Compressive Memory-based Retrieval Approach for Event Argument Extraction
Sep 14, 2024



Recent works have demonstrated the effectiveness of retrieval augmentation in the Event Argument Extraction (EAE) task. However, existing retrieval-based EAE methods have two main limitations: (1) input length constraints and (2) the gap between the retriever and the inference model. These issues limit the diversity and quality of the retrieved information. In this paper, we propose a Compressive Memory-based Retrieval (CMR) mechanism for EAE, which addresses the two limitations mentioned above. Our compressive memory, designed as a dynamic matrix that effectively caches retrieved information and supports continuous updates, overcomes the limitations of the input length. Additionally, after pre-loading all candidate demonstrations into the compressive memory, the model further retrieves and filters relevant information from memory based on the input query, bridging the gap between the retriever and the inference model. Extensive experiments show that our method achieves new state-of-the-art performance on three public datasets (RAMS, WikiEvents, ACE05), significantly outperforming existing retrieval-based EAE methods.
Beyond Single-Event Extraction: Towards Efficient Document-Level Multi-Event Argument Extraction
May 03, 2024



Recent mainstream event argument extraction methods process each event in isolation, resulting in inefficient inference and ignoring the correlations among multiple events. To address these limitations, here we propose a multiple-event argument extraction model DEEIA (Dependency-guided Encoding and Event-specific Information Aggregation), capable of extracting arguments from all events within a document simultaneouslyThe proposed DEEIA model employs a multi-event prompt mechanism, comprising DE and EIA modules. The DE module is designed to improve the correlation between prompts and their corresponding event contexts, whereas the EIA module provides event-specific information to improve contextual understanding. Extensive experiments show that our method achieves new state-of-the-art performance on four public datasets (RAMS, WikiEvents, MLEE, and ACE05), while significantly saving the inference time compared to the baselines. Further analyses demonstrate the effectiveness of the proposed modules.
MLPs Compass: What is learned when MLPs are combined with PLMs?
Jan 03, 2024
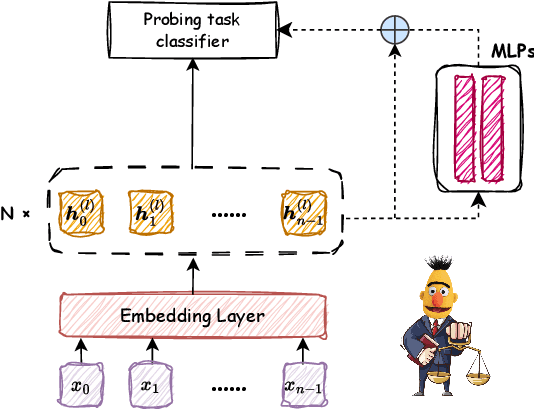
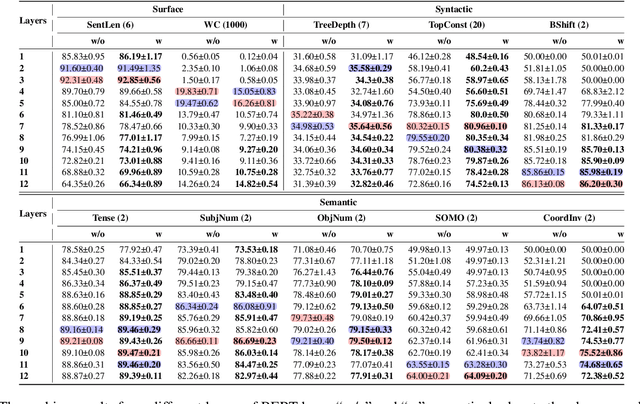
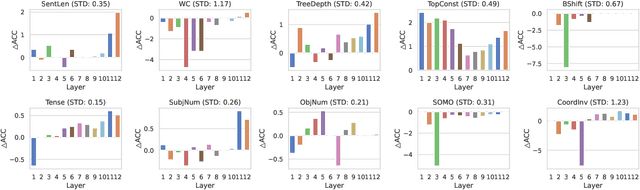
While Transformer-based pre-trained language models and their variants exhibit strong semantic representation capabilities, the question of comprehending the information gain derived from the additional components of PLMs remains an open question in this field. Motivated by recent efforts that prove Multilayer-Perceptrons (MLPs) modules achieving robust structural capture capabilities, even outperforming Graph Neural Networks (GNNs), this paper aims to quantify whether simple MLPs can further enhance the already potent ability of PLMs to capture linguistic information. Specifically, we design a simple yet effective probing framework containing MLPs components based on BERT structure and conduct extensive experiments encompassing 10 probing tasks spanning three distinct linguistic levels. The experimental results demonstrate that MLPs can indeed enhance the comprehension of linguistic structure by PLMs. Our research provides interpretable and valuable insights into crafting variations of PLMs utilizing MLPs for tasks that emphasize diverse linguistic structures.
Enhancing Document-level Event Argument Extraction with Contextual Clues and Role Relevance
Oct 20, 2023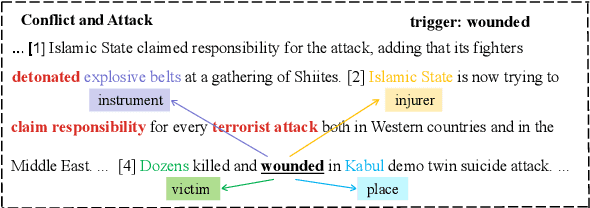
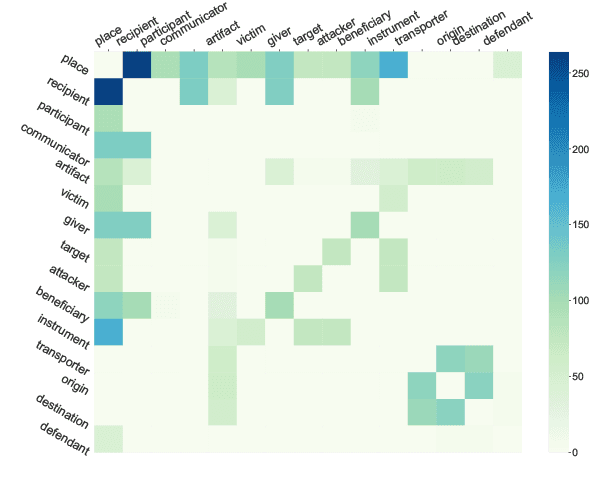
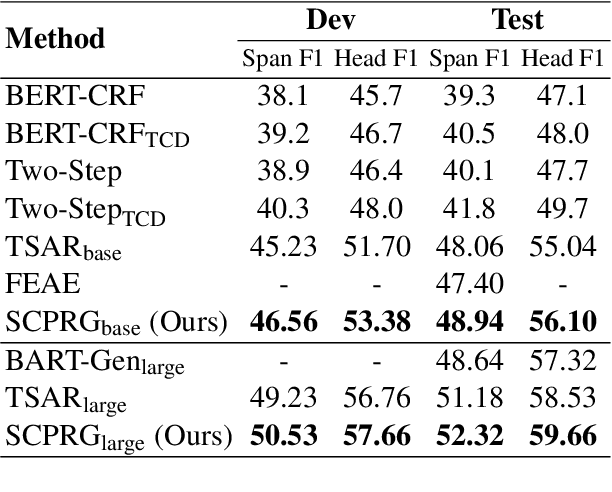
Document-level event argument extraction poses new challenges of long input and cross-sentence inference compared to its sentence-level counterpart. However, most prior works focus on capturing the relations between candidate arguments and the event trigger in each event, ignoring two crucial points: a) non-argument contextual clue information; b) the relevance among argument roles. In this paper, we propose a SCPRG (Span-trigger-based Contextual Pooling and latent Role Guidance) model, which contains two novel and effective modules for the above problem. The Span-Trigger-based Contextual Pooling(STCP) adaptively selects and aggregates the information of non-argument clue words based on the context attention weights of specific argument-trigger pairs from pre-trained model. The Role-based Latent Information Guidance (RLIG) module constructs latent role representations, makes them interact through role-interactive encoding to capture semantic relevance, and merges them into candidate arguments. Both STCP and RLIG introduce no more than 1% new parameters compared with the base model and can be easily applied to other event extraction models, which are compact and transplantable. Experiments on two public datasets show that our SCPRG outperforms previous state-of-the-art methods, with 1.13 F1 and 2.64 F1 improvements on RAMS and WikiEvents respectively. Further analyses illustrate the interpretability of our model.
Revisiting Graph Meaning Representations through Decoupling Contextual Representation Learning and Structural Information Propagation
Oct 15, 2023In the field of natural language understanding, the intersection of neural models and graph meaning representations (GMRs) remains a compelling area of research. Despite the growing interest, a critical gap persists in understanding the exact influence of GMRs, particularly concerning relation extraction tasks. Addressing this, we introduce DAGNN-plus, a simple and parameter-efficient neural architecture designed to decouple contextual representation learning from structural information propagation. Coupled with various sequence encoders and GMRs, this architecture provides a foundation for systematic experimentation on two English and two Chinese datasets. Our empirical analysis utilizes four different graph formalisms and nine parsers. The results yield a nuanced understanding of GMRs, showing improvements in three out of the four datasets, particularly favoring English over Chinese due to highly accurate parsers. Interestingly, GMRs appear less effective in literary-domain datasets compared to general-domain datasets. These findings lay the groundwork for better-informed design of GMRs and parsers to improve relation classification, which is expected to tangibly impact the future trajectory of natural language understanding research.
CARLG: Leveraging Contextual Clues and Role Correlations for Improving Document-level Event Argument Extraction
Oct 08, 2023
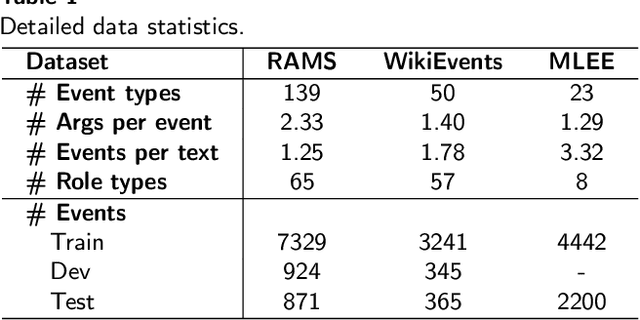
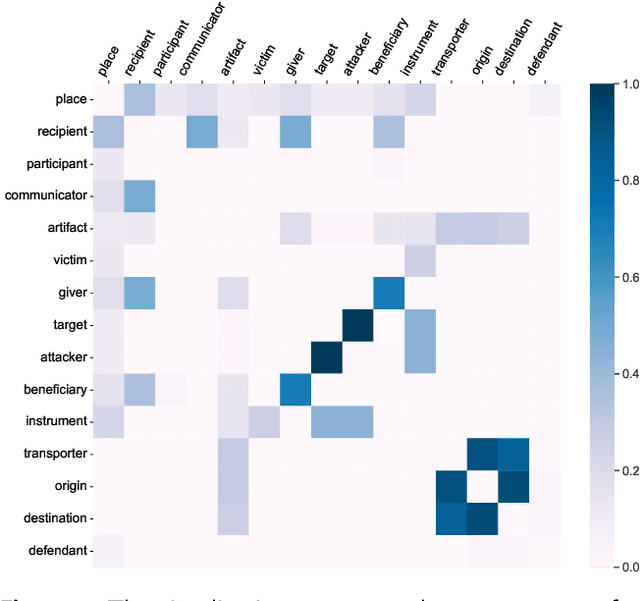
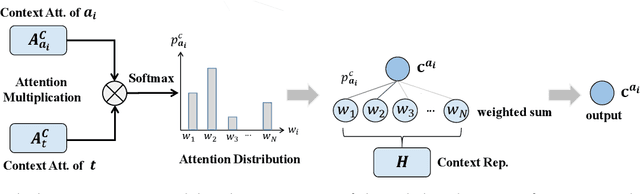
Document-level event argument extraction (EAE) is a crucial but challenging subtask in information extraction. Most existing approaches focus on the interaction between arguments and event triggers, ignoring two critical points: the information of contextual clues and the semantic correlations among argument roles. In this paper, we propose the CARLG model, which consists of two modules: Contextual Clues Aggregation (CCA) and Role-based Latent Information Guidance (RLIG), effectively leveraging contextual clues and role correlations for improving document-level EAE. The CCA module adaptively captures and integrates contextual clues by utilizing context attention weights from a pre-trained encoder. The RLIG module captures semantic correlations through role-interactive encoding and provides valuable information guidance with latent role representation. Notably, our CCA and RLIG modules are compact, transplantable and efficient, which introduce no more than 1% new parameters and can be easily equipped on other span-base methods with significant performance boost. Extensive experiments on the RAMS, WikiEvents, and MLEE datasets demonstrate the superiority of the proposed CARLG model. It outperforms previous state-of-the-art approaches by 1.26 F1, 1.22 F1, and 1.98 F1, respectively, while reducing the inference time by 31%. Furthermore, we provide detailed experimental analyses based on the performance gains and illustrate the interpretability of our model.
A Dual-Perception Graph Neural Network with Multi-hop Graph Generator
Oct 22, 2021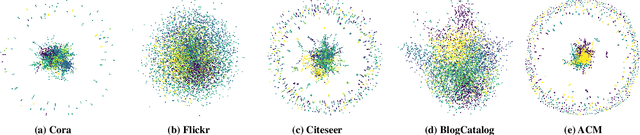
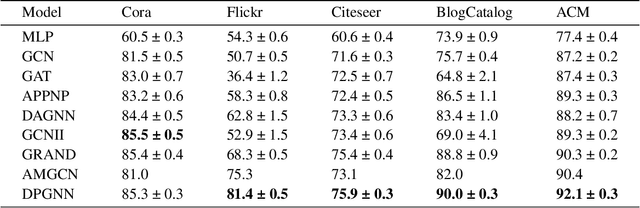
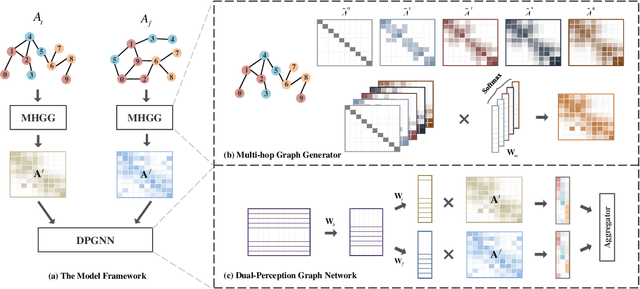
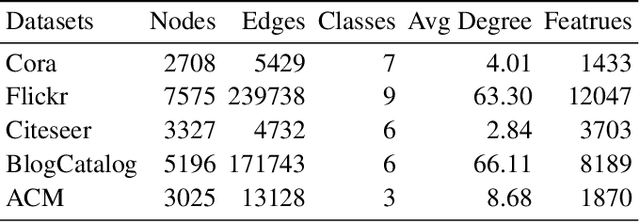
Graph neural networks (GNNs) have drawn increasing attention in recent years and achieved remarkable performance in many graph-based tasks, especially in semi-supervised learning on graphs. However, most existing GNNs excessively rely on topological structures and aggregate multi-hop neighborhood information by simply stacking network layers, which may introduce superfluous noise information, limit the expressive power of GNNs and lead to the over-smoothing problem ultimately. In light of this, we propose a novel Dual-Perception Graph Neural Network (DPGNN) to address these issues. In DPGNN, we utilize node features to construct a feature graph, and perform node representations learning based on the original topology graph and the constructed feature graph simultaneously, which conduce to capture the structural neighborhood information and the feature-related information. Furthermore, we design a Multi-Hop Graph Generator (MHGG), which applies a node-to-hop attention mechanism to aggregate node-specific multi-hop neighborhood information adaptively. Finally, we apply self-ensembling to form a consistent prediction for unlabeled node representations. Experimental results on five datasets with different topological structures demonstrate that our proposed DPGNN outperforms all the latest state-of-the-art models on all datasets, which proves the superiority and versatility of our model. The source code of our model is available at https://github.com.