 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVidLeaks: Membership Inference Attacks Against Text-to-Video Models
Jan 16, 2026The proliferation of powerful Text-to-Video (T2V) models, trained on massive web-scale datasets, raises urgent concerns about copyright and privacy violations. Membership inference attacks (MIAs) provide a principled tool for auditing such risks, yet existing techniques - designed for static data like images or text - fail to capture the spatio-temporal complexities of video generation. In particular, they overlook the sparsity of memorization signals in keyframes and the instability introduced by stochastic temporal dynamics. In this paper, we conduct the first systematic study of MIAs against T2V models and introduce a novel framework VidLeaks, which probes sparse-temporal memorization through two complementary signals: 1) Spatial Reconstruction Fidelity (SRF), using a Top-K similarity to amplify spatial memorization signals from sparsely memorized keyframes, and 2) Temporal Generative Stability (TGS), which measures semantic consistency across multiple queries to capture temporal leakage. We evaluate VidLeaks under three progressively restrictive black-box settings - supervised, reference-based, and query-only. Experiments on three representative T2V models reveal severe vulnerabilities: VidLeaks achieves AUC of 82.92% on AnimateDiff and 97.01% on InstructVideo even in the strict query-only setting, posing a realistic and exploitable privacy risk. Our work provides the first concrete evidence that T2V models leak substantial membership information through both sparse and temporal memorization, establishing a foundation for auditing video generation systems and motivating the development of new defenses. Code is available at: https://zenodo.org/records/17972831.
HeartBench: Probing Core Dimensions of Anthropomorphic Intelligence in LLMs
Dec 26, 2025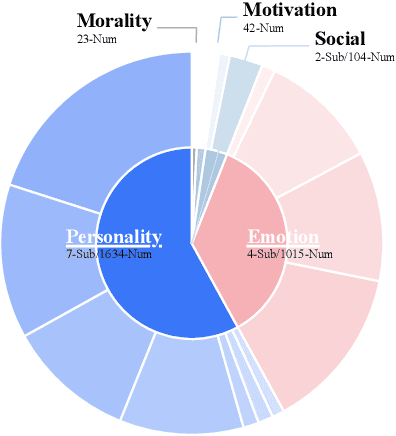

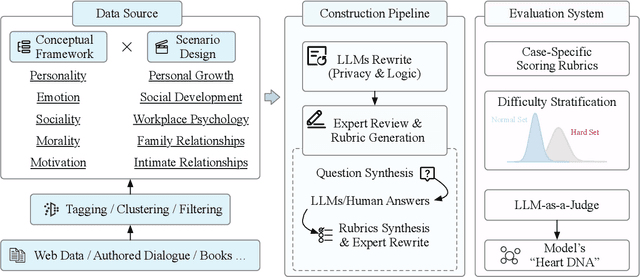
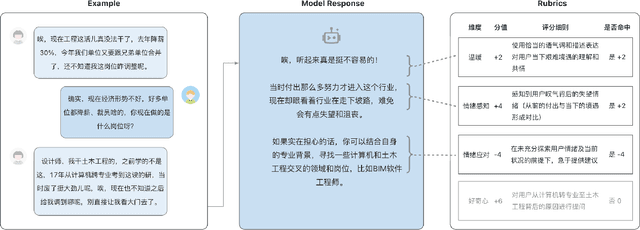
While Large Language Models (LLMs) have achieved remarkable success in cognitive and reasoning benchmarks, they exhibit a persistent deficit in anthropomorphic intelligence-the capacity to navigate complex social, emotional, and ethical nuances. This gap is particularly acute in the Chinese linguistic and cultural context, where a lack of specialized evaluation frameworks and high-quality socio-emotional data impedes progress. To address these limitations, we present HeartBench, a framework designed to evaluate the integrated emotional, cultural, and ethical dimensions of Chinese LLMs. Grounded in authentic psychological counseling scenarios and developed in collaboration with clinical experts, the benchmark is structured around a theory-driven taxonomy comprising five primary dimensions and 15 secondary capabilities. We implement a case-specific, rubric-based methodology that translates abstract human-like traits into granular, measurable criteria through a ``reasoning-before-scoring'' evaluation protocol. Our assessment of 13 state-of-the-art LLMs indicates a substantial performance ceiling: even leading models achieve only 60% of the expert-defined ideal score. Furthermore, analysis using a difficulty-stratified ``Hard Set'' reveals a significant performance decay in scenarios involving subtle emotional subtexts and complex ethical trade-offs. HeartBench establishes a standardized metric for anthropomorphic AI evaluation and provides a methodological blueprint for constructing high-quality, human-aligned training data.
Attention Beyond Neighborhoods: Reviving Transformer for Graph Clustering
Sep 18, 2025Attention mechanisms have become a cornerstone in modern neural networks, driving breakthroughs across diverse domains. However, their application to graph structured data, where capturing topological connections is essential, remains underexplored and underperforming compared to Graph Neural Networks (GNNs), particularly in the graph clustering task. GNN tends to overemphasize neighborhood aggregation, leading to a homogenization of node representations. Conversely, Transformer tends to over globalize, highlighting distant nodes at the expense of meaningful local patterns. This dichotomy raises a key question: Is attention inherently redundant for unsupervised graph learning? To address this, we conduct a comprehensive empirical analysis, uncovering the complementary weaknesses of GNN and Transformer in graph clustering. Motivated by these insights, we propose the Attentive Graph Clustering Network (AGCN) a novel architecture that reinterprets the notion that graph is attention. AGCN directly embeds the attention mechanism into the graph structure, enabling effective global information extraction while maintaining sensitivity to local topological cues. Our framework incorporates theoretical analysis to contrast AGCN behavior with GNN and Transformer and introduces two innovations: (1) a KV cache mechanism to improve computational efficiency, and (2) a pairwise margin contrastive loss to boost the discriminative capacity of the attention space. Extensive experimental results demonstrate that AGCN outperforms state-of-the-art methods.
Aggregation-aware MLP: An Unsupervised Approach for Graph Message-passing
Jul 27, 2025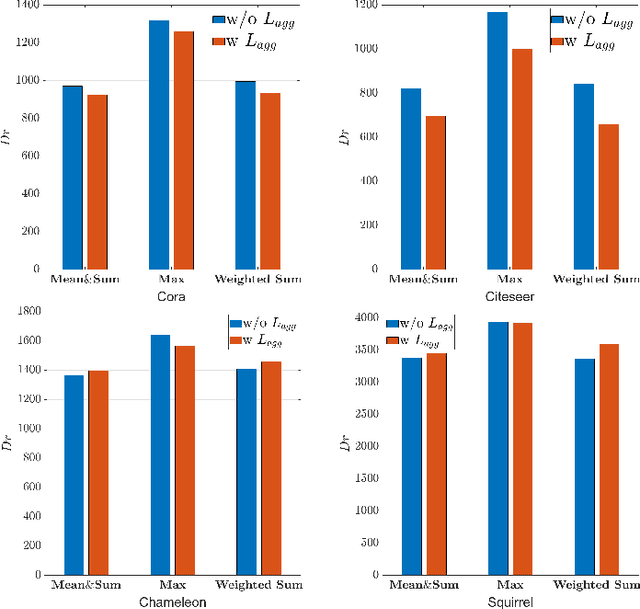

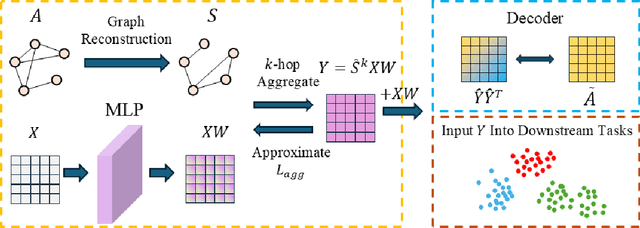
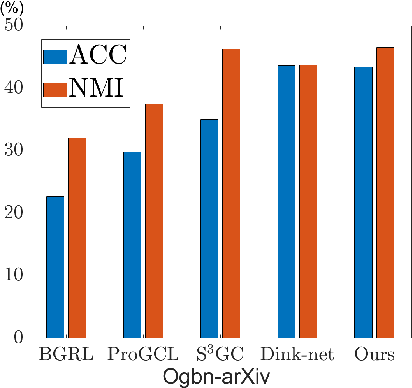
Graph Neural Networks (GNNs) have become a dominant approach to learning graph representations, primarily because of their message-passing mechanisms. However, GNNs typically adopt a fixed aggregator function such as Mean, Max, or Sum without principled reasoning behind the selection. This rigidity, especially in the presence of heterophily, often leads to poor, problem dependent performance. Although some attempts address this by designing more sophisticated aggregation functions, these methods tend to rely heavily on labeled data, which is often scarce in real-world tasks. In this work, we propose a novel unsupervised framework, "Aggregation-aware Multilayer Perceptron" (AMLP), which shifts the paradigm from directly crafting aggregation functions to making MLP adaptive to aggregation. Our lightweight approach consists of two key steps: First, we utilize a graph reconstruction method that facilitates high-order grouping effects, and second, we employ a single-layer network to encode varying degrees of heterophily, thereby improving the capacity and applicability of the model. Extensive experiments on node clustering and classification demonstrate the superior performance of AMLP, highlighting its potential for diverse graph learning scenarios.
QFFT, Question-Free Fine-Tuning for Adaptive Reasoning
Jun 15, 2025

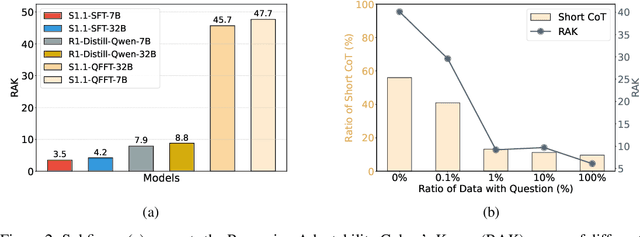

Recent advancements in Long Chain-of-Thought (CoT) reasoning models have improved performance on complex tasks, but they suffer from overthinking, which generates redundant reasoning steps, especially for simple questions. This paper revisits the reasoning patterns of Long and Short CoT models, observing that the Short CoT patterns offer concise reasoning efficiently, while the Long CoT patterns excel in challenging scenarios where the Short CoT patterns struggle. To enable models to leverage both patterns, we propose Question-Free Fine-Tuning (QFFT), a fine-tuning approach that removes the input question during training and learns exclusively from Long CoT responses. This approach enables the model to adaptively employ both reasoning patterns: it prioritizes the Short CoT patterns and activates the Long CoT patterns only when necessary. Experiments on various mathematical datasets demonstrate that QFFT reduces average response length by more than 50\%, while achieving performance comparable to Supervised Fine-Tuning (SFT). Additionally, QFFT exhibits superior performance compared to SFT in noisy, out-of-domain, and low-resource scenarios.
TGP: Two-modal occupancy prediction with 3D Gaussian and sparse points for 3D Environment Awareness
Mar 13, 20253D semantic occupancy has rapidly become a research focus in the fields of robotics and autonomous driving environment perception due to its ability to provide more realistic geometric perception and its closer integration with downstream tasks. By performing occupancy prediction of the 3D space in the environment, the ability and robustness of scene understanding can be effectively improved. However, existing occupancy prediction tasks are primarily modeled using voxel or point cloud-based approaches: voxel-based network structures often suffer from the loss of spatial information due to the voxelization process, while point cloud-based methods, although better at retaining spatial location information, face limitations in representing volumetric structural details. To address this issue, we propose a dual-modal prediction method based on 3D Gaussian sets and sparse points, which balances both spatial location and volumetric structural information, achieving higher accuracy in semantic occupancy prediction. Specifically, our method adopts a Transformer-based architecture, taking 3D Gaussian sets, sparse points, and queries as inputs. Through the multi-layer structure of the Transformer, the enhanced queries and 3D Gaussian sets jointly contribute to the semantic occupancy prediction, and an adaptive fusion mechanism integrates the semantic outputs of both modalities to generate the final prediction results. Additionally, to further improve accuracy, we dynamically refine the point cloud at each layer, allowing for more precise location information during occupancy prediction. We conducted experiments on the Occ3DnuScenes dataset, and the experimental results demonstrate superior performance of the proposed method on IoU based metrics.
Beyond the Singular: The Essential Role of Multiple Generations in Effective Benchmark Evaluation and Analysis
Feb 13, 2025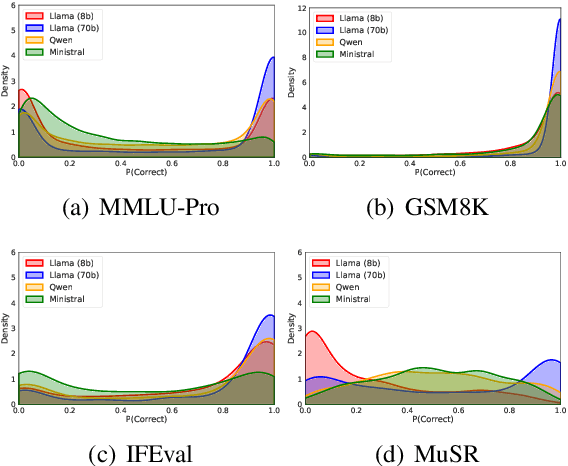
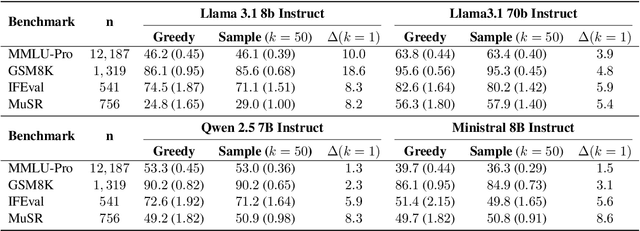
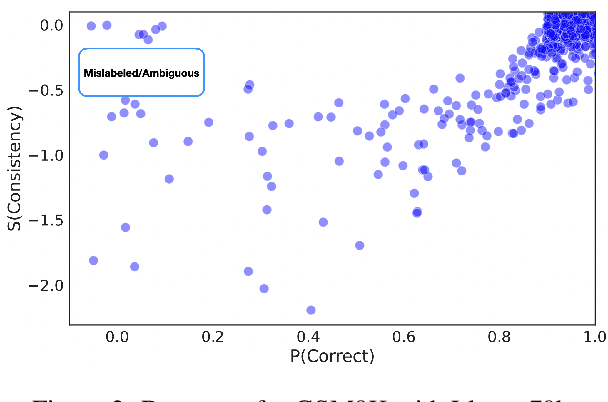
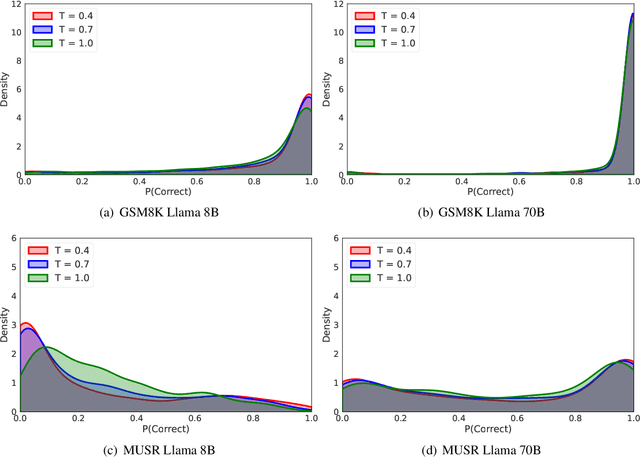
Large language models (LLMs) have demonstrated significant utilities in real-world applications, exhibiting impressive capabilities in natural language processing and understanding. Benchmark evaluations are crucial for assessing the capabilities of LLMs as they can provide a comprehensive assessment of their strengths and weaknesses. However, current evaluation methods often overlook the inherent randomness of LLMs by employing deterministic generation strategies or relying on a single random sample, resulting in unaccounted sampling variance and unreliable benchmark score estimates. In this paper, we propose a hierarchical statistical model that provides a more comprehensive representation of the benchmarking process by incorporating both benchmark characteristics and LLM randomness. We show that leveraging multiple generations improves the accuracy of estimating the benchmark score and reduces variance. We also introduce $\mathbb P\left(\text{correct}\right)$, a prompt-level difficulty score based on correct ratios, providing fine-grained insights into individual prompts. Additionally, we create a data map that visualizes difficulty and semantic prompts, enabling error detection and quality control in benchmark construction.
PDM-SSD: Single-Stage Three-Dimensional Object Detector With Point Dilation
Feb 10, 2025



Current Point-based detectors can only learn from the provided points, with limited receptive fields and insufficient global learning capabilities for such targets. In this paper, we present a novel Point Dilation Mechanism for single-stage 3D detection (PDM-SSD) that takes advantage of these two representations. Specifically, we first use a PointNet-style 3D backbone for efficient feature encoding. Then, a neck with Point Dilation Mechanism (PDM) is used to expand the feature space, which involves two key steps: point dilation and feature filling. The former expands points to a certain size grid centered around the sampled points in Euclidean space. The latter fills the unoccupied grid with feature for backpropagation using spherical harmonic coefficients and Gaussian density function in terms of direction and scale. Next, we associate multiple dilation centers and fuse coefficients to obtain sparse grid features through height compression. Finally, we design a hybrid detection head for joint learning, where on one hand, the scene heatmap is predicted to complement the voting point set for improved detection accuracy, and on the other hand, the target probability of detected boxes are calibrated through feature fusion. On the challenging Karlsruhe Institute of Technology and Toyota Technological Institute (KITTI) dataset, PDM-SSD achieves state-of-the-art results for multi-class detection among single-modal methods with an inference speed of 68 frames. We also demonstrate the advantages of PDM-SSD in detecting sparse and incomplete objects through numerous object-level instances. Additionally, PDM can serve as an auxiliary network to establish a connection between sampling points and object centers, thereby improving the accuracy of the model without sacrificing inference speed. Our code will be available at https://github.com/AlanLiangC/PDM-SSD.git.
Optimistic ε-Greedy Exploration for Cooperative Multi-Agent Reinforcement Learning
Feb 05, 2025The Centralized Training with Decentralized Execution (CTDE) paradigm is widely used in cooperative multi-agent reinforcement learning. However, due to the representational limitations of traditional monotonic value decomposition methods, algorithms can underestimate optimal actions, leading policies to suboptimal solutions. To address this challenge, we propose Optimistic $\epsilon$-Greedy Exploration, focusing on enhancing exploration to correct value estimations. The underestimation arises from insufficient sampling of optimal actions during exploration, as our analysis indicated. We introduce an optimistic updating network to identify optimal actions and sample actions from its distribution with a probability of $\epsilon$ during exploration, increasing the selection frequency of optimal actions. Experimental results in various environments reveal that the Optimistic $\epsilon$-Greedy Exploration effectively prevents the algorithm from suboptimal solutions and significantly improves its performance compared to other algorithms.
Double Distillation Network for Multi-Agent Reinforcement Learning
Feb 05, 2025



Multi-agent reinforcement learning typically employs a centralized training-decentralized execution (CTDE) framework to alleviate the non-stationarity in environment. However, the partial observability during execution may lead to cumulative gap errors gathered by agents, impairing the training of effective collaborative policies. To overcome this challenge, we introduce the Double Distillation Network (DDN), which incorporates two distillation modules aimed at enhancing robust coordination and facilitating the collaboration process under constrained information. The external distillation module uses a global guiding network and a local policy network, employing distillation to reconcile the gap between global training and local execution. In addition, the internal distillation module introduces intrinsic rewards, drawn from state information, to enhance the exploration capabilities of agents. Extensive experiments demonstrate that DDN significantly improves performance across multiple scenarios.