 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIFFVSGG: Diffusion-Driven Online Video Scene Graph Generation
Mar 18, 2025Top-leading solutions for Video Scene Graph Generation (VSGG) typically adopt an offline pipeline. Though demonstrating promising performance, they remain unable to handle real-time video streams and consume large GPU memory. Moreover, these approaches fall short in temporal reasoning, merely aggregating frame-level predictions over a temporal context. In response, we introduce DIFFVSGG, an online VSGG solution that frames this task as an iterative scene graph update problem. Drawing inspiration from Latent Diffusion Models (LDMs) which generate images via denoising a latent feature embedding, we unify the decoding of object classification, bounding box regression, and graph generation three tasks using one shared feature embedding. Then, given an embedding containing unified features of object pairs, we conduct a step-wise Denoising on it within LDMs, so as to deliver a clean embedding which clearly indicates the relationships between objects. This embedding then serves as the input to task-specific heads for object classification, scene graph generation, etc. DIFFVSGG further facilitates continuous temporal reasoning, where predictions for subsequent frames leverage results of past frames as the conditional inputs of LDMs, to guide the reverse diffusion process for current frames. Extensive experiments on three setups of Action Genome demonstrate the superiority of DIFFVSGG.
TGP: Two-modal occupancy prediction with 3D Gaussian and sparse points for 3D Environment Awareness
Mar 13, 20253D semantic occupancy has rapidly become a research focus in the fields of robotics and autonomous driving environment perception due to its ability to provide more realistic geometric perception and its closer integration with downstream tasks. By performing occupancy prediction of the 3D space in the environment, the ability and robustness of scene understanding can be effectively improved. However, existing occupancy prediction tasks are primarily modeled using voxel or point cloud-based approaches: voxel-based network structures often suffer from the loss of spatial information due to the voxelization process, while point cloud-based methods, although better at retaining spatial location information, face limitations in representing volumetric structural details. To address this issue, we propose a dual-modal prediction method based on 3D Gaussian sets and sparse points, which balances both spatial location and volumetric structural information, achieving higher accuracy in semantic occupancy prediction. Specifically, our method adopts a Transformer-based architecture, taking 3D Gaussian sets, sparse points, and queries as inputs. Through the multi-layer structure of the Transformer, the enhanced queries and 3D Gaussian sets jointly contribute to the semantic occupancy prediction, and an adaptive fusion mechanism integrates the semantic outputs of both modalities to generate the final prediction results. Additionally, to further improve accuracy, we dynamically refine the point cloud at each layer, allowing for more precise location information during occupancy prediction. We conducted experiments on the Occ3DnuScenes dataset, and the experimental results demonstrate superior performance of the proposed method on IoU based metrics.
UAHOI: Uncertainty-aware Robust Interaction Learning for HOI Detection
Aug 14, 2024
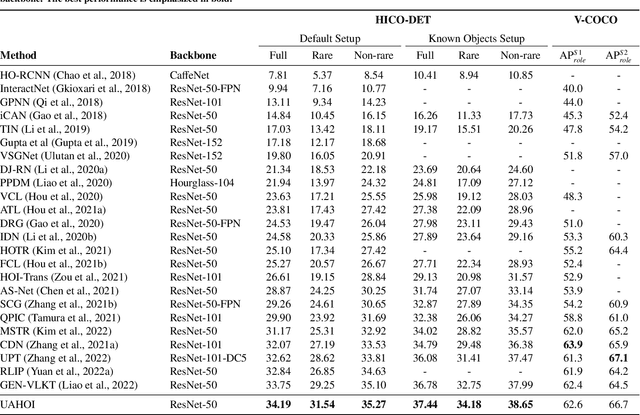
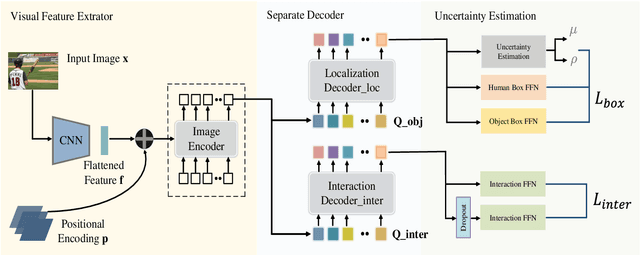
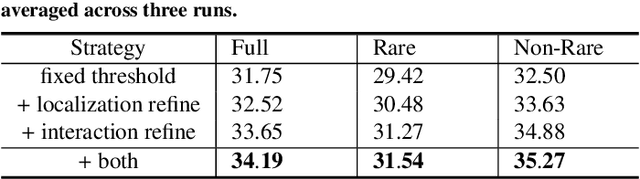
This paper focuses on Human-Object Interaction (HOI) detection, addressing the challenge of identifying and understanding the interactions between humans and objects within a given image or video frame. Spearheaded by Detection Transformer (DETR), recent developments lead to significant improvements by replacing traditional region proposals by a set of learnable queries. However, despite the powerful representation capabilities provided by Transformers, existing Human-Object Interaction (HOI) detection methods still yield low confidence levels when dealing with complex interactions and are prone to overlooking interactive actions. To address these issues, we propose a novel approach \textsc{UAHOI}, Uncertainty-aware Robust Human-Object Interaction Learning that explicitly estimates prediction uncertainty during the training process to refine both detection and interaction predictions. Our model not only predicts the HOI triplets but also quantifies the uncertainty of these predictions. Specifically, we model this uncertainty through the variance of predictions and incorporate it into the optimization objective, allowing the model to adaptively adjust its confidence threshold based on prediction variance. This integration helps in mitigating the adverse effects of incorrect or ambiguous predictions that are common in traditional methods without any hand-designed components, serving as an automatic confidence threshold. Our method is flexible to existing HOI detection methods and demonstrates improved accuracy. We evaluate \textsc{UAHOI} on two standard benchmarks in the field: V-COCO and HICO-DET, which represent challenging scenarios for HOI detection. Through extensive experiments, we demonstrate that \textsc{UAHOI} achieves significant improvements over existing state-of-the-art methods, enhancing both the accuracy and robustness of HOI detection.
PiPa++: Towards Unification of Domain Adaptive Semantic Segmentation via Self-supervised Learning
Jul 24, 2024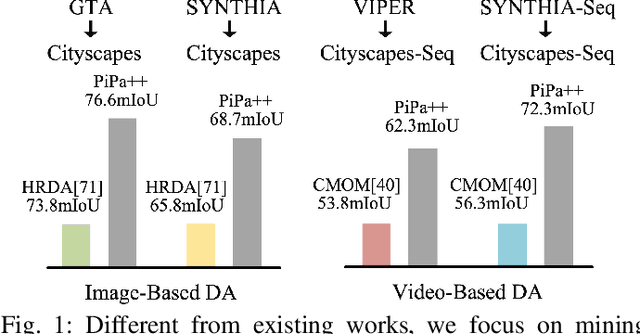
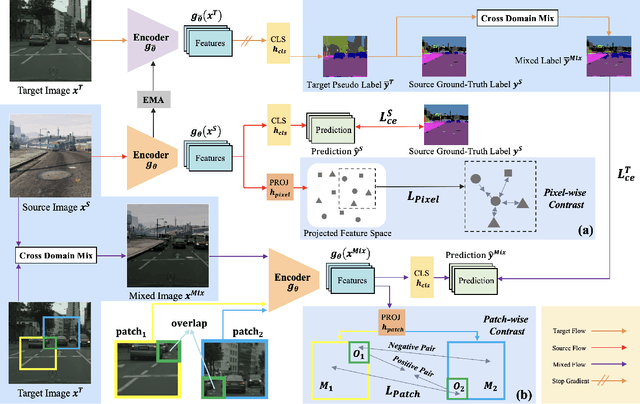
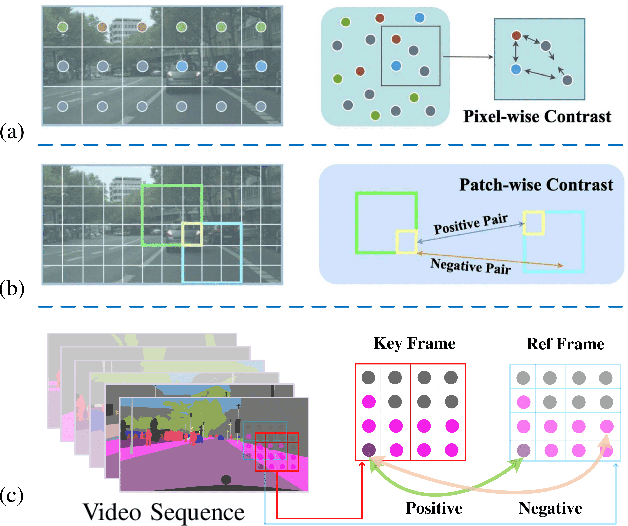
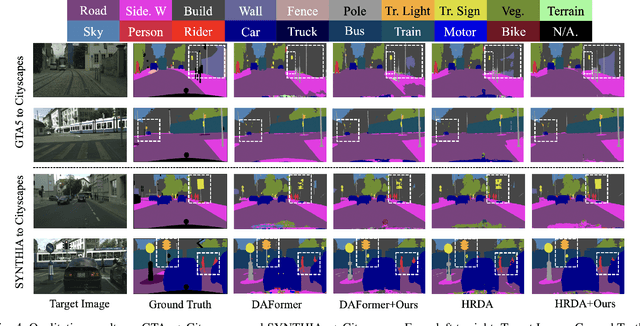
Unsupervised domain adaptive segmentation aims to improve the segmentation accuracy of models on target domains without relying on labeled data from those domains. This approach is crucial when labeled target domain data is scarce or unavailable. It seeks to align the feature representations of the source domain (where labeled data is available) and the target domain (where only unlabeled data is present), thus enabling the model to generalize well to the target domain. Current image- and video-level domain adaptation have been addressed using different and specialized frameworks, training strategies and optimizations despite their underlying connections. In this paper, we propose a unified framework PiPa++, which leverages the core idea of ``comparing'' to (1) explicitly encourage learning of discriminative pixel-wise features with intraclass compactness and inter-class separability, (2) promote the robust feature learning of the identical patch against different contexts or fluctuations, and (3) enable the learning of temporal continuity under dynamic environments. With the designed task-smart contrastive sampling strategy, PiPa++ enables the mining of more informative training samples according to the task demand. Extensive experiments demonstrate the effectiveness of our method on both image-level and video-level domain adaption benchmarks. Moreover, the proposed method is compatible with other UDA approaches to further improve the performance without introducing extra parameters.
General and Task-Oriented Video Segmentation
Jul 09, 2024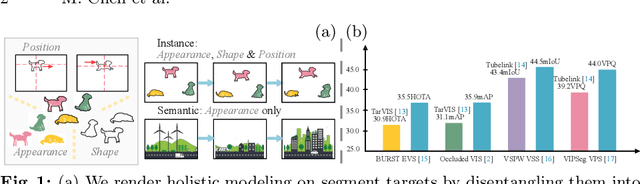
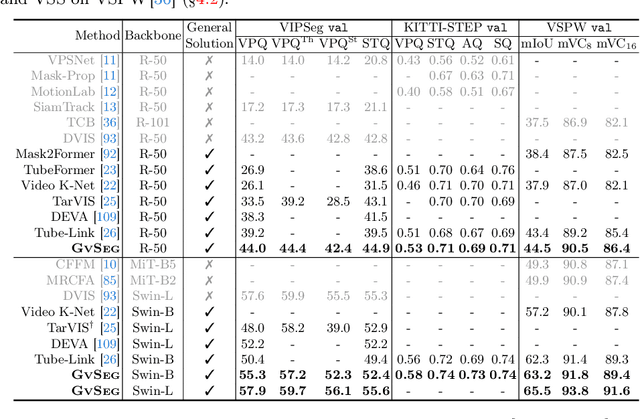
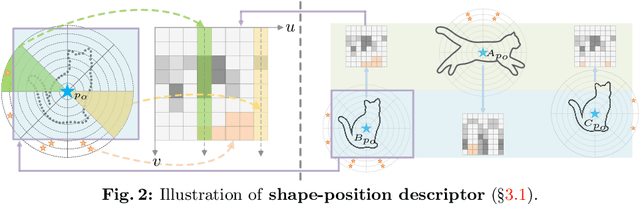
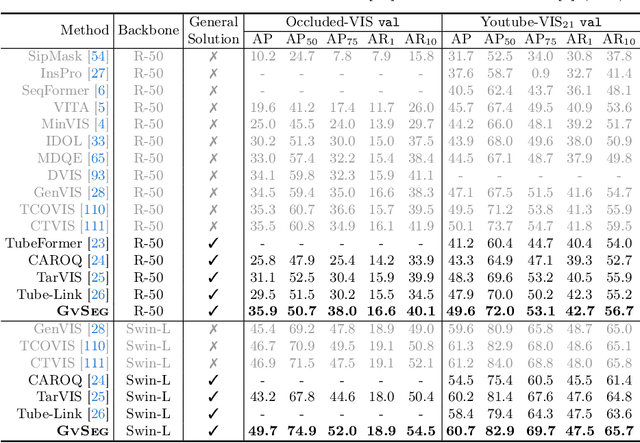
We present GvSeg, a general video segmentation framework for addressing four different video segmentation tasks (i.e., instance, semantic, panoptic, and exemplar-guided) while maintaining an identical architectural design. Currently, there is a trend towards developing general video segmentation solutions that can be applied across multiple tasks. This streamlines research endeavors and simplifies deployment. However, such a highly homogenized framework in current design, where each element maintains uniformity, could overlook the inherent diversity among different tasks and lead to suboptimal performance. To tackle this, GvSeg: i) provides a holistic disentanglement and modeling for segment targets, thoroughly examining them from the perspective of appearance, position, and shape, and on this basis, ii) reformulates the query initialization, matching and sampling strategies in alignment with the task-specific requirement. These architecture-agnostic innovations empower GvSeg to effectively address each unique task by accommodating the specific properties that characterize them. Extensive experiments on seven gold-standard benchmark datasets demonstrate that GvSeg surpasses all existing specialized/general solutions by a significant margin on four different video segmentation tasks.
Transferring to Real-World Layouts: A Depth-aware Framework for Scene Adaptation
Nov 21, 2023



Scene segmentation via unsupervised domain adaptation (UDA) enables the transfer of knowledge acquired from source synthetic data to real-world target data, which largely reduces the need for manual pixel-level annotations in the target domain. To facilitate domain-invariant feature learning, existing methods typically mix data from both the source domain and target domain by simply copying and pasting the pixels. Such vanilla methods are usually sub-optimal since they do not take into account how well the mixed layouts correspond to real-world scenarios. Real-world scenarios are with an inherent layout. We observe that semantic categories, such as sidewalks, buildings, and sky, display relatively consistent depth distributions, and could be clearly distinguished in a depth map. Based on such observation, we propose a depth-aware framework to explicitly leverage depth estimation to mix the categories and facilitate the two complementary tasks, i.e., segmentation and depth learning in an end-to-end manner. In particular, the framework contains a Depth-guided Contextual Filter (DCF) forndata augmentation and a cross-task encoder for contextual learning. DCF simulates the real-world layouts, while the cross-task encoder further adaptively fuses the complementing features between two tasks. Besides, it is worth noting that several public datasets do not provide depth annotation. Therefore, we leverage the off-the-shelf depth estimation network to generate the pseudo depth. Extensive experiments show that our proposed methods, even with pseudo depth, achieve competitive performance on two widely-used bench-marks, i.e. 77.7 mIoU on GTA to Cityscapes and 69.3 mIoU on Synthia to Cityscapes.
PiPa: Pixel- and Patch-wise Self-supervised Learning for Domain Adaptative Semantic Segmentation
Nov 14, 2022Unsupervised Domain Adaptation (UDA) aims to enhance the generalization of the learned model to other domains. The domain-invariant knowledge is transferred from the model trained on labeled source domain, e.g., video game, to unlabeled target domains, e.g., real-world scenarios, saving annotation expenses. Existing UDA methods for semantic segmentation usually focus on minimizing the inter-domain discrepancy of various levels, e.g., pixels, features, and predictions, for extracting domain-invariant knowledge. However, the primary intra-domain knowledge, such as context correlation inside an image, remains underexplored. In an attempt to fill this gap, we propose a unified pixel- and patch-wise self-supervised learning framework, called PiPa, for domain adaptive semantic segmentation that facilitates intra-image pixel-wise correlations and patch-wise semantic consistency against different contexts. The proposed framework exploits the inherent structures of intra-domain images, which: (1) explicitly encourages learning the discriminative pixel-wise features with intra-class compactness and inter-class separability, and (2) motivates the robust feature learning of the identical patch against different contexts or fluctuations. Extensive experiments verify the effectiveness of the proposed method, which obtains competitive accuracy on the two widely-used UDA benchmarks, i.e., 75.6 mIoU on GTA to Cityscapes and 68.2 mIoU on Synthia to Cityscapes. Moreover, our method is compatible with other UDA approaches to further improve the performance without introducing extra parameters.