 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecLoR: Spectral Lookahead Rectification for Motion-Coherent Text-to-Video Generation
Jun 10, 2026Flow Matching has enabled robust text-to-video generation via latent ODE sampling. However, velocity approximation and numerical discretization errors inevitably accumulate, causing sampling trajectories to drift. Consequently, generated videos often suffer from severe spatiotemporal inconsistencies. Nevertheless, directly correcting these drifted, noisy latents is challenging: (i) timestep-dependent noise obscures reliable structural cues; (ii) spatial interventions risk disrupting intricate local geometry while incurring heavy computational costs. To address this, we propose Spectral Lookahead Rectification (SpecLoR), a plug-and-play inference method that bypasses noise via lookahead prediction, and circumvents spatiotemporal entanglement by shifting corrections to the frequency domain, where universal statistical priors of natural videos are readily available. First, during early sampling stages, SpecLoR looks ahead to estimate the clean latent $z_{t,0}$ and computes its 3D spatiotemporal spectrum. Next, SpecLoR rectifies the amplitude spectrum to match the prior, leaving the phase intact. Finally, the corrected state is re-noised to resume ODE integration. Experiments on Wan2.2 demonstrate that SpecLoR significantly reduces physical artifacts and enhances motion coherence across multiple benchmarks with minimal computational overhead (4 additional NFEs).
UniGeo: Unifying Geometric Guidance for Camera-Controllable Image Editing via Video Models
Apr 19, 2026Camera-controllable image editing aims to synthesize novel views of a given scene under varying camera poses while strictly preserving cross-view geometric consistency. However, existing methods typically rely on fragmented geometric guidance, such as only injecting point clouds at the representation level despite models containing multiple levels, and are mainly based on image diffusion models that operate on discrete view mappings. These two limitations jointly lead to geometric drift and structural degradation under continuous camera motion. We observe that while leveraging video models provides continuous viewpoint priors for camera-controllable image editing, they still struggle to form stable geometric understanding if geometric guidance remains fragmented. To systematically address this, we inject unified geometric guidance across three levels that jointly determine the generative output: representation, architecture, and loss function. To this end, we propose UniGeo, a novel camera-controllable editing framework. Specifically, at the representation level, UniGeo incorporates a frame-decoupled geometric reference injection mechanism to provide robust cross-view geometry context. At the architecture level, it introduces geometric anchor attention to align multi-view features. At the loss function level, it proposes a trajectory-endpoint geometric supervision strategy to explicitly reinforce the structural fidelity of target views. Comprehensive experiments across multiple public benchmarks, encompassing both extensive and limited camera motion settings, demonstrate that UniGeo significantly outperforms existing methods in both visual quality and geometric consistency.
Beyond Independent Genes: Learning Module-Inductive Representations for Gene Perturbation Prediction
Feb 03, 2026Predicting transcriptional responses to genetic perturbations is a central problem in functional genomics. In practice, perturbation responses are rarely gene-independent but instead manifest as coordinated, program-level transcriptional changes among functionally related genes. However, most existing methods do not explicitly model such coordination, due to gene-wise modeling paradigms and reliance on static biological priors that cannot capture dynamic program reorganization. To address these limitations, we propose scBIG, a module-inductive perturbation prediction framework that explicitly models coordinated gene programs. scBIG induces coherent gene programs from data via Gene-Relation Clustering, captures inter-program interactions through a Gene-Cluster-Aware Encoder, and preserves modular coordination using structure-aware alignment objectives. These structured representations are then modeled using conditional flow matching to enable flexible and generalizable perturbation prediction. Extensive experiments on multiple single-cell perturbation benchmarks show that scBIG consistently outperforms state-of-the-art methods, particularly on unseen and combinatorial perturbation settings, achieving an average improvement of 6.7% over the strongest baselines.
Moving Beyond Diffusion: Hierarchy-to-Hierarchy Autoregression for fMRI-to-Image Reconstruction
Oct 25, 2025Reconstructing visual stimuli from fMRI signals is a central challenge bridging machine learning and neuroscience. Recent diffusion-based methods typically map fMRI activity to a single high-level embedding, using it as fixed guidance throughout the entire generation process. However, this fixed guidance collapses hierarchical neural information and is misaligned with the stage-dependent demands of image reconstruction. In response, we propose MindHier, a coarse-to-fine fMRI-to-image reconstruction framework built on scale-wise autoregressive modeling. MindHier introduces three components: a Hierarchical fMRI Encoder to extract multi-level neural embeddings, a Hierarchy-to-Hierarchy Alignment scheme to enforce layer-wise correspondence with CLIP features, and a Scale-Aware Coarse-to-Fine Neural Guidance strategy to inject these embeddings into autoregression at matching scales. These designs make MindHier an efficient and cognitively-aligned alternative to diffusion-based methods by enabling a hierarchical reconstruction process that synthesizes global semantics before refining local details, akin to human visual perception. Extensive experiments on the NSD dataset show that MindHier achieves superior semantic fidelity, 4.67x faster inference, and more deterministic results than the diffusion-based baselines.
Dynamic Experts Search: Enhancing Reasoning in Mixture-of-Experts LLMs at Test Time
Sep 26, 2025
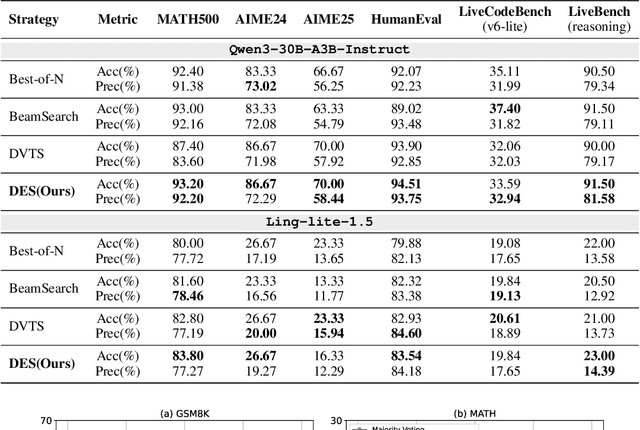


Test-Time Scaling (TTS) enhances the reasoning ability of large language models (LLMs) by allocating additional computation during inference. However, existing approaches primarily rely on output-level sampling while overlooking the role of model architecture. In mainstream Mixture-of-Experts (MoE) LLMs, we observe that varying the number of activated experts yields complementary solution sets with stable accuracy, revealing a new and underexplored source of diversity. Motivated by this observation, we propose Dynamic Experts Search (DES), a TTS strategy that elevates expert activation into a controllable dimension of the search space. DES integrates two key components: (1) Dynamic MoE, which enables direct control of expert counts during inference to generate diverse reasoning trajectories without additional cost; and (2) Expert Configuration Inheritance, which preserves consistent expert counts within a reasoning path while varying them across runs, thereby balancing stability and diversity throughout the search. Extensive experiments across MoE architectures, verifiers and reasoning benchmarks (i.e., math, code and knowledge) demonstrate that DES reliably outperforms TTS baselines, enhancing accuracy and stability without additional cost. These results highlight DES as a practical and scalable form of architecture-aware TTS, illustrating how structural flexibility in modern LLMs can advance reasoning.
Insert Anything: Image Insertion via In-Context Editing in DiT
Apr 21, 2025



This work presents Insert Anything, a unified framework for reference-based image insertion that seamlessly integrates objects from reference images into target scenes under flexible, user-specified control guidance. Instead of training separate models for individual tasks, our approach is trained once on our new AnyInsertion dataset--comprising 120K prompt-image pairs covering diverse tasks such as person, object, and garment insertion--and effortlessly generalizes to a wide range of insertion scenarios. Such a challenging setting requires capturing both identity features and fine-grained details, while allowing versatile local adaptations in style, color, and texture. To this end, we propose to leverage the multimodal attention of the Diffusion Transformer (DiT) to support both mask- and text-guided editing. Furthermore, we introduce an in-context editing mechanism that treats the reference image as contextual information, employing two prompting strategies to harmonize the inserted elements with the target scene while faithfully preserving their distinctive features. Extensive experiments on AnyInsertion, DreamBooth, and VTON-HD benchmarks demonstrate that our method consistently outperforms existing alternatives, underscoring its great potential in real-world applications such as creative content generation, virtual try-on, and scene composition.
TarPro: Targeted Protection against Malicious Image Editing
Mar 18, 2025The rapid advancement of image editing techniques has raised concerns about their misuse for generating Not-Safe-for-Work (NSFW) content. This necessitates a targeted protection mechanism that blocks malicious edits while preserving normal editability. However, existing protection methods fail to achieve this balance, as they indiscriminately disrupt all edits while still allowing some harmful content to be generated. To address this, we propose TarPro, a targeted protection framework that prevents malicious edits while maintaining benign modifications. TarPro achieves this through a semantic-aware constraint that only disrupts malicious content and a lightweight perturbation generator that produces a more stable, imperceptible, and robust perturbation for image protection. Extensive experiments demonstrate that TarPro surpasses existing methods, achieving a high protection efficacy while ensuring minimal impact on normal edits. Our results highlight TarPro as a practical solution for secure and controlled image editing.
BrainGuard: Privacy-Preserving Multisubject Image Reconstructions from Brain Activities
Jan 24, 2025



Reconstructing perceived images from human brain activity forms a crucial link between human and machine learning through Brain-Computer Interfaces. Early methods primarily focused on training separate models for each individual to account for individual variability in brain activity, overlooking valuable cross-subject commonalities. Recent advancements have explored multisubject methods, but these approaches face significant challenges, particularly in data privacy and effectively managing individual variability. To overcome these challenges, we introduce BrainGuard, a privacy-preserving collaborative training framework designed to enhance image reconstruction from multisubject fMRI data while safeguarding individual privacy. BrainGuard employs a collaborative global-local architecture where individual models are trained on each subject's local data and operate in conjunction with a shared global model that captures and leverages cross-subject patterns. This architecture eliminates the need to aggregate fMRI data across subjects, thereby ensuring privacy preservation. To tackle the complexity of fMRI data, BrainGuard integrates a hybrid synchronization strategy, enabling individual models to dynamically incorporate parameters from the global model. By establishing a secure and collaborative training environment, BrainGuard not only protects sensitive brain data but also improves the image reconstructions accuracy. Extensive experiments demonstrate that BrainGuard sets a new benchmark in both high-level and low-level metrics, advancing the state-of-the-art in brain decoding through its innovative design.
Autonomous LLM-Enhanced Adversarial Attack for Text-to-Motion
Aug 01, 2024



Human motion generation driven by deep generative models has enabled compelling applications, but the ability of text-to-motion (T2M) models to produce realistic motions from text prompts raises security concerns if exploited maliciously. Despite growing interest in T2M, few methods focus on safeguarding these models against adversarial attacks, with existing work on text-to-image models proving insufficient for the unique motion domain. In the paper, we propose ALERT-Motion, an autonomous framework leveraging large language models (LLMs) to craft targeted adversarial attacks against black-box T2M models. Unlike prior methods modifying prompts through predefined rules, ALERT-Motion uses LLMs' knowledge of human motion to autonomously generate subtle yet powerful adversarial text descriptions. It comprises two key modules: an adaptive dispatching module that constructs an LLM-based agent to iteratively refine and search for adversarial prompts; and a multimodal information contrastive module that extracts semantically relevant motion information to guide the agent's search. Through this LLM-driven approach, ALERT-Motion crafts adversarial prompts querying victim models to produce outputs closely matching targeted motions, while avoiding obvious perturbations. Evaluations across popular T2M models demonstrate ALERT-Motion's superiority over previous methods, achieving higher attack success rates with stealthier adversarial prompts. This pioneering work on T2M adversarial attacks highlights the urgency of developing defensive measures as motion generation technology advances, urging further research into safe and responsible deployment.
Shape2Scene: 3D Scene Representation Learning Through Pre-training on Shape Data
Jul 14, 2024



Current 3D self-supervised learning methods of 3D scenes face a data desert issue, resulting from the time-consuming and expensive collecting process of 3D scene data. Conversely, 3D shape datasets are easier to collect. Despite this, existing pre-training strategies on shape data offer limited potential for 3D scene understanding due to significant disparities in point quantities. To tackle these challenges, we propose Shape2Scene (S2S), a novel method that learns representations of large-scale 3D scenes from 3D shape data. We first design multiscale and high-resolution backbones for shape and scene level 3D tasks, i.e., MH-P (point-based) and MH-V (voxel-based). MH-P/V establishes direct paths to highresolution features that capture deep semantic information across multiple scales. This pivotal nature makes them suitable for a wide range of 3D downstream tasks that tightly rely on high-resolution features. We then employ a Shape-to-Scene strategy (S2SS) to amalgamate points from various shapes, creating a random pseudo scene (comprising multiple objects) for training data, mitigating disparities between shapes and scenes. Finally, a point-point contrastive loss (PPC) is applied for the pre-training of MH-P/V. In PPC, the inherent correspondence (i.e., point pairs) is naturally obtained in S2SS. Extensive experiments have demonstrated the transferability of 3D representations learned by MH-P/V across shape-level and scene-level 3D tasks. MH-P achieves notable performance on well-known point cloud datasets (93.8% OA on ScanObjectNN and 87.6% instance mIoU on ShapeNetPart). MH-V also achieves promising performance in 3D semantic segmentation and 3D object detection.