 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of World Models for Autonomous Driving
Jan 20, 2025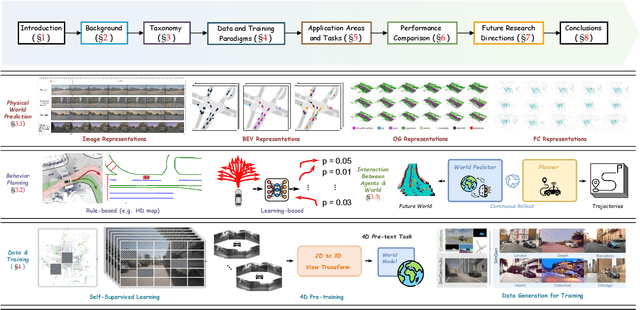
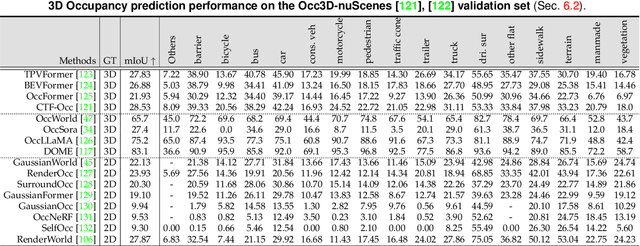
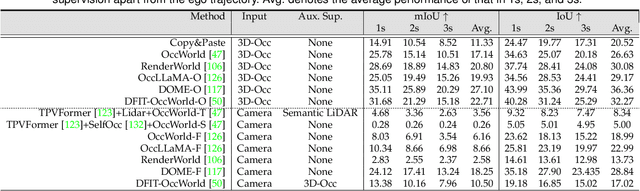
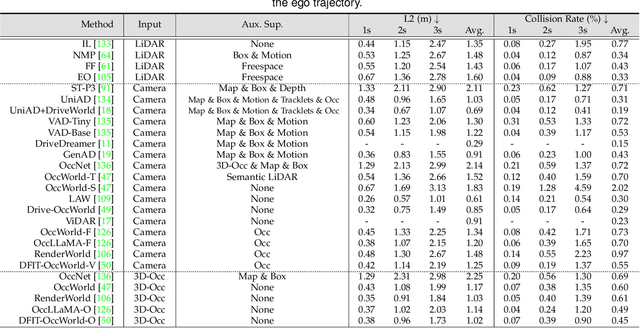
Recent breakthroughs in autonomous driving have revolutionized the way vehicles perceive and interact with their surroundings. In particular, world models have emerged as a linchpin technology, offering high-fidelity representations of the driving environment that integrate multi-sensor data, semantic cues, and temporal dynamics. Such models unify perception, prediction, and planning, thereby enabling autonomous systems to make rapid, informed decisions under complex and often unpredictable conditions. Research trends span diverse areas, including 4D occupancy prediction and generative data synthesis, all of which bolster scene understanding and trajectory forecasting. Notably, recent works exploit large-scale pretraining and advanced self-supervised learning to scale up models' capacity for rare-event simulation and real-time interaction. In addressing key challenges -- ranging from domain adaptation and long-tail anomaly detection to multimodal fusion -- these world models pave the way for more robust, reliable, and adaptable autonomous driving solutions. This survey systematically reviews the state of the art, categorizing techniques by their focus on future prediction, behavior planning, and the interaction between the two. We also identify potential directions for future research, emphasizing holistic integration, improved computational efficiency, and advanced simulation. Our comprehensive analysis underscores the transformative role of world models in driving next-generation autonomous systems toward safer and more equitable mobility.
Shape2Scene: 3D Scene Representation Learning Through Pre-training on Shape Data
Jul 14, 2024



Current 3D self-supervised learning methods of 3D scenes face a data desert issue, resulting from the time-consuming and expensive collecting process of 3D scene data. Conversely, 3D shape datasets are easier to collect. Despite this, existing pre-training strategies on shape data offer limited potential for 3D scene understanding due to significant disparities in point quantities. To tackle these challenges, we propose Shape2Scene (S2S), a novel method that learns representations of large-scale 3D scenes from 3D shape data. We first design multiscale and high-resolution backbones for shape and scene level 3D tasks, i.e., MH-P (point-based) and MH-V (voxel-based). MH-P/V establishes direct paths to highresolution features that capture deep semantic information across multiple scales. This pivotal nature makes them suitable for a wide range of 3D downstream tasks that tightly rely on high-resolution features. We then employ a Shape-to-Scene strategy (S2SS) to amalgamate points from various shapes, creating a random pseudo scene (comprising multiple objects) for training data, mitigating disparities between shapes and scenes. Finally, a point-point contrastive loss (PPC) is applied for the pre-training of MH-P/V. In PPC, the inherent correspondence (i.e., point pairs) is naturally obtained in S2SS. Extensive experiments have demonstrated the transferability of 3D representations learned by MH-P/V across shape-level and scene-level 3D tasks. MH-P achieves notable performance on well-known point cloud datasets (93.8% OA on ScanObjectNN and 87.6% instance mIoU on ShapeNetPart). MH-V also achieves promising performance in 3D semantic segmentation and 3D object detection.
LSK3DNet: Towards Effective and Efficient 3D Perception with Large Sparse Kernels
Mar 22, 2024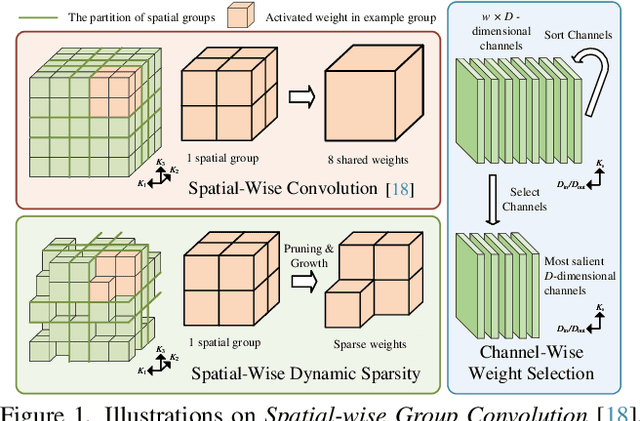
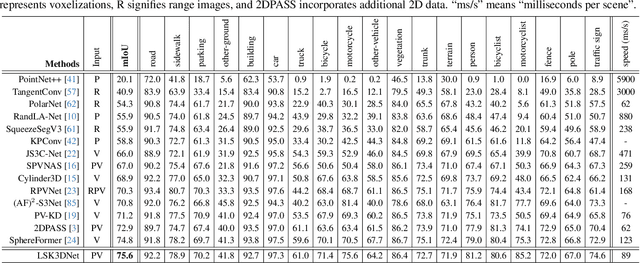
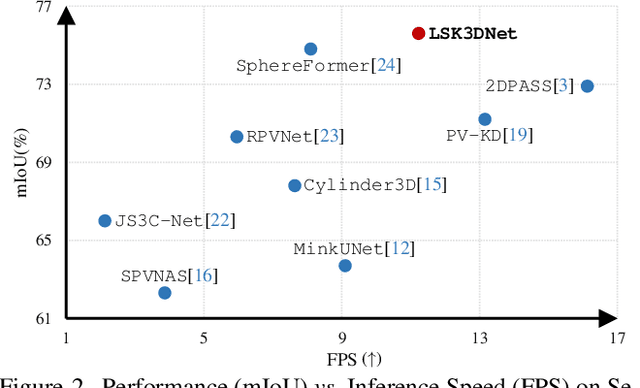
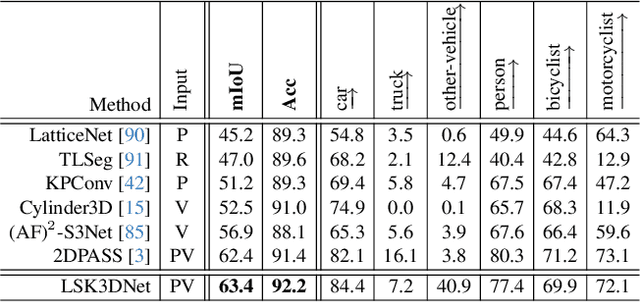
Autonomous systems need to process large-scale, sparse, and irregular point clouds with limited compute resources. Consequently, it is essential to develop LiDAR perception methods that are both efficient and effective. Although naively enlarging 3D kernel size can enhance performance, it will also lead to a cubically-increasing overhead. Therefore, it is crucial to develop streamlined 3D large kernel designs that eliminate redundant weights and work effectively with larger kernels. In this paper, we propose an efficient and effective Large Sparse Kernel 3D Neural Network (LSK3DNet) that leverages dynamic pruning to amplify the 3D kernel size. Our method comprises two core components: Spatial-wise Dynamic Sparsity (SDS) and Channel-wise Weight Selection (CWS). SDS dynamically prunes and regrows volumetric weights from the beginning to learn a large sparse 3D kernel. It not only boosts performance but also significantly reduces model size and computational cost. Moreover, CWS selects the most important channels for 3D convolution during training and subsequently prunes the redundant channels to accelerate inference for 3D vision tasks. We demonstrate the effectiveness of LSK3DNet on three benchmark datasets and five tracks compared with classical models and large kernel designs. Notably, LSK3DNet achieves the state-of-the-art performance on SemanticKITTI (i.e., 75.6% on single-scan and 63.4% on multi-scan), with roughly 40% model size reduction and 60% computing operations reduction compared to the naive large 3D kernel model.
Clustering based Point Cloud Representation Learning for 3D Analysis
Jul 27, 2023Point cloud analysis (such as 3D segmentation and detection) is a challenging task, because of not only the irregular geometries of many millions of unordered points, but also the great variations caused by depth, viewpoint, occlusion, etc. Current studies put much focus on the adaption of neural networks to the complex geometries of point clouds, but are blind to a fundamental question: how to learn an appropriate point embedding space that is aware of both discriminative semantics and challenging variations? As a response, we propose a clustering based supervised learning scheme for point cloud analysis. Unlike current de-facto, scene-wise training paradigm, our algorithm conducts within-class clustering on the point embedding space for automatically discovering subclass patterns which are latent yet representative across scenes. The mined patterns are, in turn, used to repaint the embedding space, so as to respect the underlying distribution of the entire training dataset and improve the robustness to the variations. Our algorithm is principled and readily pluggable to modern point cloud segmentation networks during training, without extra overhead during testing. With various 3D network architectures (i.e., voxel-based, point-based, Transformer-based, automatically searched), our algorithm shows notable improvements on famous point cloud segmentation datasets (i.e.,2.0-2.6% on single-scan and 2.0-2.2% multi-scan of SemanticKITTI, 1.8-1.9% on S3DIS, in terms of mIoU). Our algorithm also demonstrates utility in 3D detection, showing 2.0-3.4% mAP gains on KITTI.
SGANVO: Unsupervised Deep Visual Odometry and Depth Estimation with Stacked Generative Adversarial Networks
Jun 20, 2019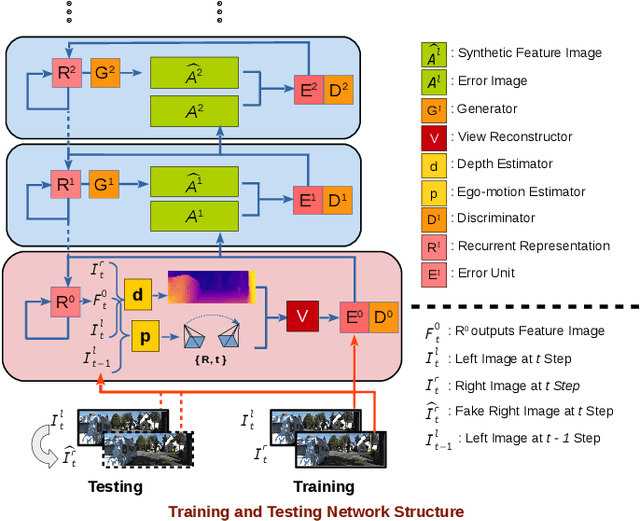
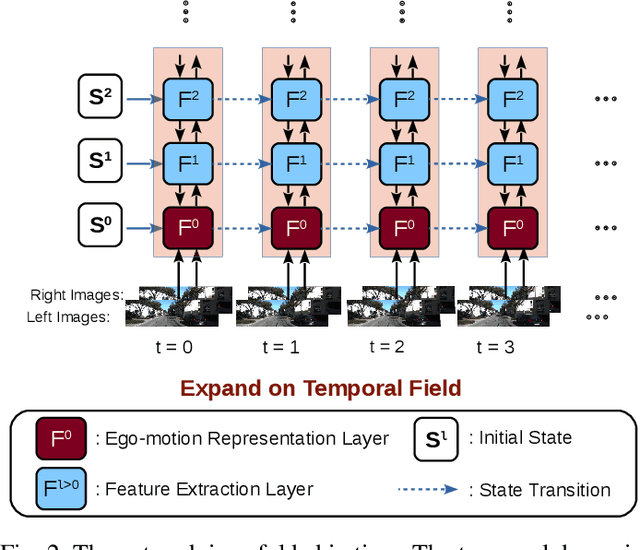
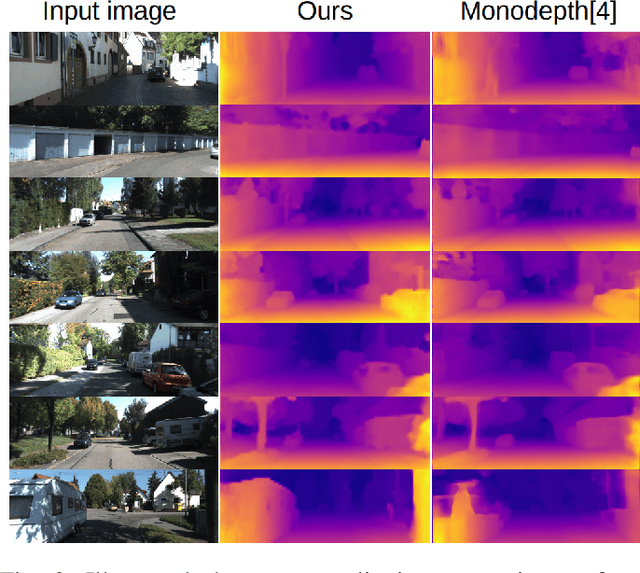
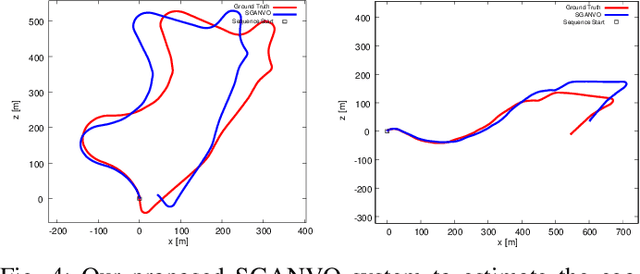
Recently end-to-end unsupervised deep learning methods have achieved an effect beyond geometric methods for visual depth and ego-motion estimation tasks. These data-based learning methods perform more robustly and accurately in some of the challenging scenes. The encoder-decoder network has been widely used in the depth estimation and the RCNN has brought significant improvements in the ego-motion estimation. Furthermore, the latest use of Generative Adversarial Nets(GANs) in depth and ego-motion estimation has demonstrated that the estimation could be further improved by generating pictures in the game learning process. This paper proposes a novel unsupervised network system for visual depth and ego-motion estimation: Stacked Generative Adversarial Network(SGANVO). It consists of a stack of GAN layers, of which the lowest layer estimates the depth and ego-motion while the higher layers estimate the spatial features. It can also capture the temporal dynamic due to the use of a recurrent representation across the layers. See Fig.1 for details. We select the most commonly used KITTI [1] data set for evaluation. The evaluation results show that our proposed method can produce better or comparable results in depth and ego-motion estimation.