 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIFFVSGG: Diffusion-Driven Online Video Scene Graph Generation
Mar 18, 2025Top-leading solutions for Video Scene Graph Generation (VSGG) typically adopt an offline pipeline. Though demonstrating promising performance, they remain unable to handle real-time video streams and consume large GPU memory. Moreover, these approaches fall short in temporal reasoning, merely aggregating frame-level predictions over a temporal context. In response, we introduce DIFFVSGG, an online VSGG solution that frames this task as an iterative scene graph update problem. Drawing inspiration from Latent Diffusion Models (LDMs) which generate images via denoising a latent feature embedding, we unify the decoding of object classification, bounding box regression, and graph generation three tasks using one shared feature embedding. Then, given an embedding containing unified features of object pairs, we conduct a step-wise Denoising on it within LDMs, so as to deliver a clean embedding which clearly indicates the relationships between objects. This embedding then serves as the input to task-specific heads for object classification, scene graph generation, etc. DIFFVSGG further facilitates continuous temporal reasoning, where predictions for subsequent frames leverage results of past frames as the conditional inputs of LDMs, to guide the reverse diffusion process for current frames. Extensive experiments on three setups of Action Genome demonstrate the superiority of DIFFVSGG.
Human-Object Interaction Detection Collaborated with Large Relation-driven Diffusion Models
Oct 26, 2024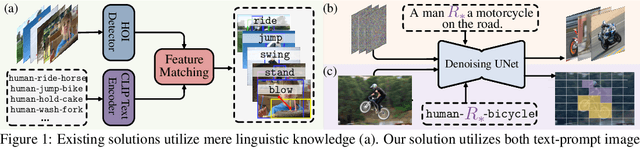
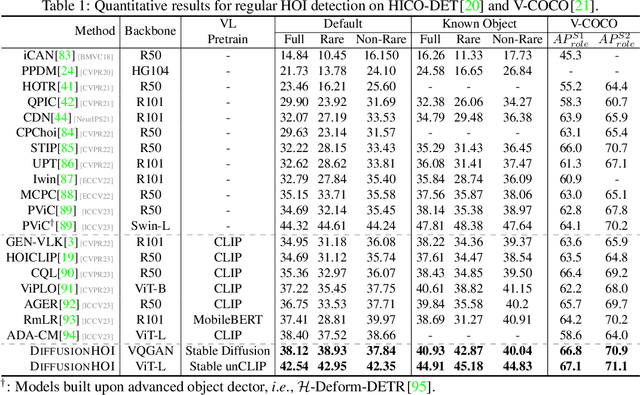
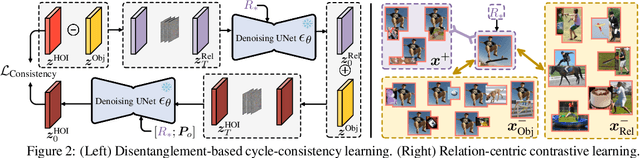
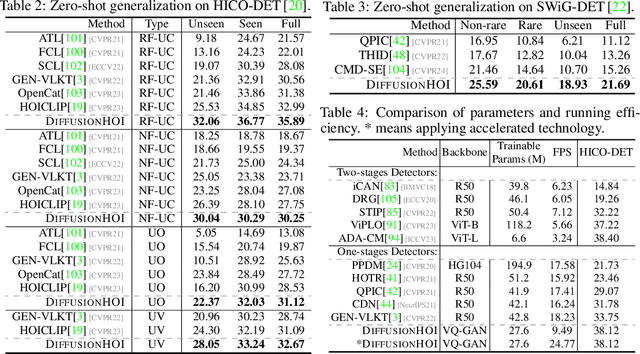
Prevalent human-object interaction (HOI) detection approaches typically leverage large-scale visual-linguistic models to help recognize events involving humans and objects. Though promising, models trained via contrastive learning on text-image pairs often neglect mid/low-level visual cues and struggle at compositional reasoning. In response, we introduce DIFFUSIONHOI, a new HOI detector shedding light on text-to-image diffusion models. Unlike the aforementioned models, diffusion models excel in discerning mid/low-level visual concepts as generative models, and possess strong compositionality to handle novel concepts expressed in text inputs. Considering diffusion models usually emphasize instance objects, we first devise an inversion-based strategy to learn the expression of relation patterns between humans and objects in embedding space. These learned relation embeddings then serve as textual prompts, to steer diffusion models generate images that depict specific interactions, and extract HOI-relevant cues from images without heavy fine-tuning. Benefited from above, DIFFUSIONHOI achieves SOTA performance on three datasets under both regular and zero-shot setups.
General and Task-Oriented Video Segmentation
Jul 09, 2024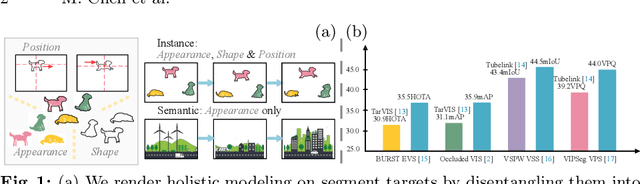
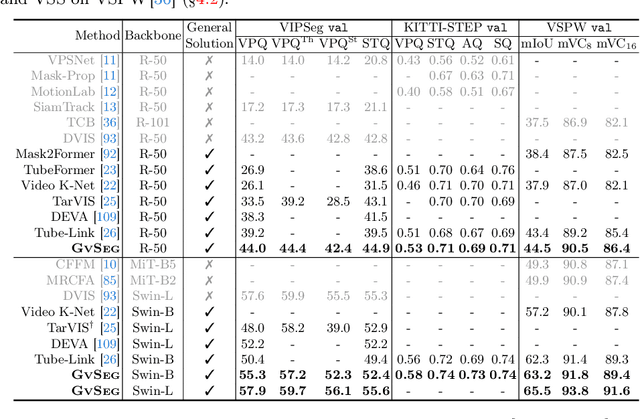
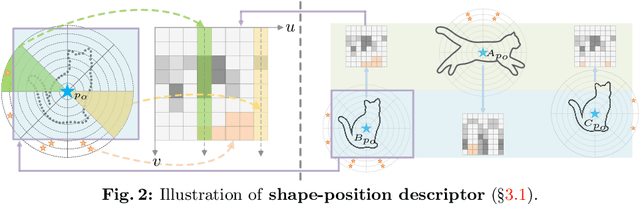
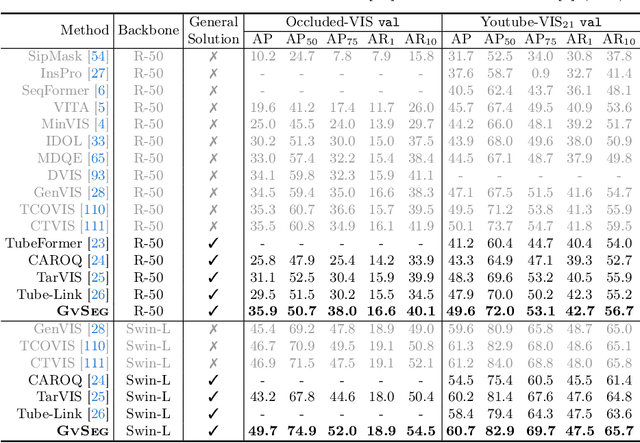
We present GvSeg, a general video segmentation framework for addressing four different video segmentation tasks (i.e., instance, semantic, panoptic, and exemplar-guided) while maintaining an identical architectural design. Currently, there is a trend towards developing general video segmentation solutions that can be applied across multiple tasks. This streamlines research endeavors and simplifies deployment. However, such a highly homogenized framework in current design, where each element maintains uniformity, could overlook the inherent diversity among different tasks and lead to suboptimal performance. To tackle this, GvSeg: i) provides a holistic disentanglement and modeling for segment targets, thoroughly examining them from the perspective of appearance, position, and shape, and on this basis, ii) reformulates the query initialization, matching and sampling strategies in alignment with the task-specific requirement. These architecture-agnostic innovations empower GvSeg to effectively address each unique task by accommodating the specific properties that characterize them. Extensive experiments on seven gold-standard benchmark datasets demonstrate that GvSeg surpasses all existing specialized/general solutions by a significant margin on four different video segmentation tasks.
Frequency-based Matcher for Long-tailed Semantic Segmentation
Jun 06, 2024
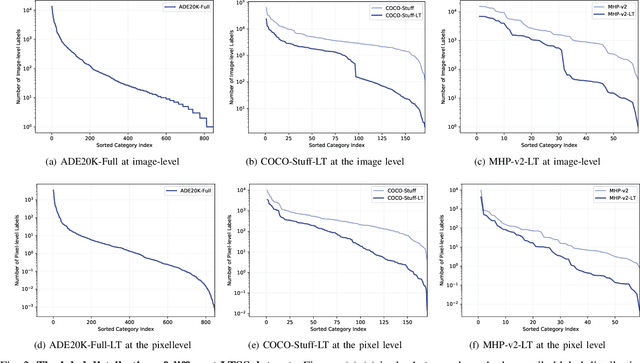
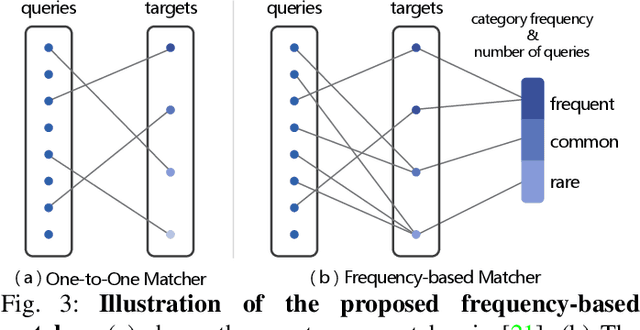
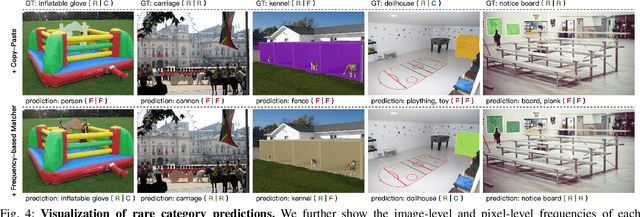
The successful application of semantic segmentation technology in the real world has been among the most exciting achievements in the computer vision community over the past decade. Although the long-tailed phenomenon has been investigated in many fields, e.g., classification and object detection, it has not received enough attention in semantic segmentation and has become a non-negligible obstacle to applying semantic segmentation technology in autonomous driving and virtual reality. Therefore, in this work, we focus on a relatively under-explored task setting, long-tailed semantic segmentation (LTSS). We first establish three representative datasets from different aspects, i.e., scene, object, and human. We further propose a dual-metric evaluation system and construct the LTSS benchmark to demonstrate the performance of semantic segmentation methods and long-tailed solutions. We also propose a transformer-based algorithm to improve LTSS, frequency-based matcher, which solves the oversuppression problem by one-to-many matching and automatically determines the number of matching queries for each class. Given the comprehensiveness of this work and the importance of the issues revealed, this work aims to promote the empirical study of semantic segmentation tasks. Our datasets, codes, and models will be publicly available.
Clustering Propagation for Universal Medical Image Segmentation
Mar 25, 2024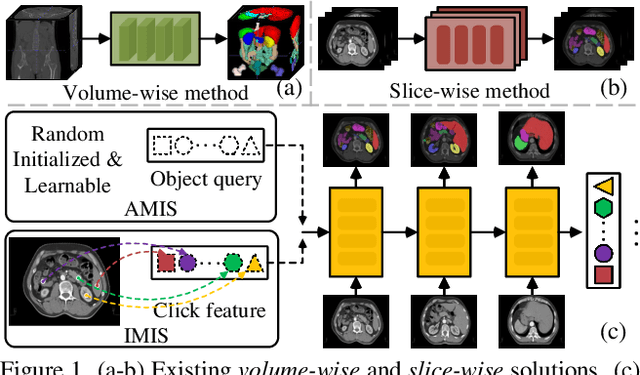
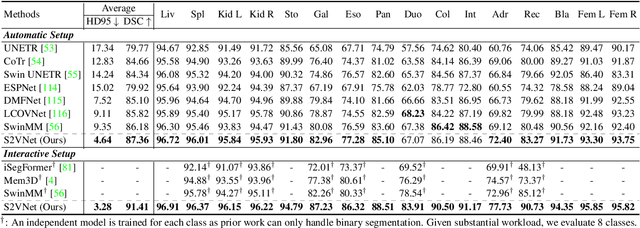
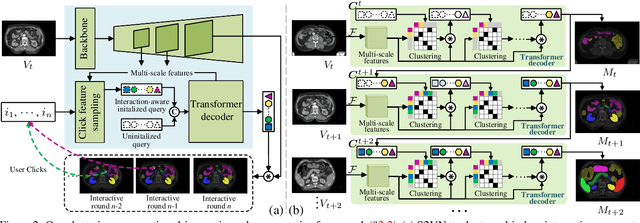
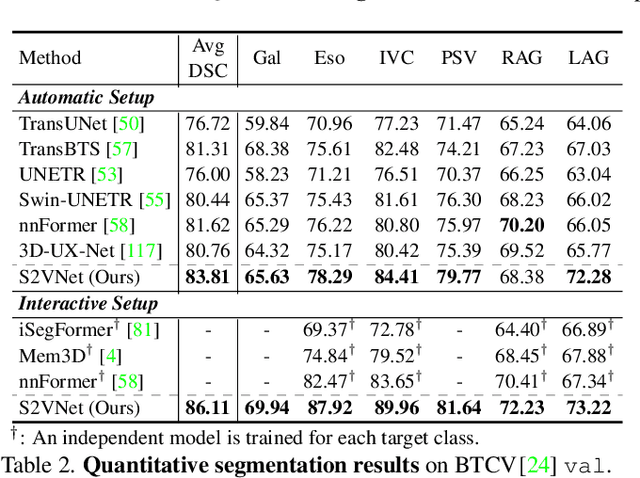
Prominent solutions for medical image segmentation are typically tailored for automatic or interactive setups, posing challenges in facilitating progress achieved in one task to another.$_{\!}$ This$_{\!}$ also$_{\!}$ necessitates$_{\!}$ separate$_{\!}$ models for each task, duplicating both training time and parameters.$_{\!}$ To$_{\!}$ address$_{\!}$ above$_{\!}$ issues,$_{\!}$ we$_{\!}$ introduce$_{\!}$ S2VNet,$_{\!}$ a$_{\!}$ universal$_{\!}$ framework$_{\!}$ that$_{\!}$ leverages$_{\!}$ Slice-to-Volume$_{\!}$ propagation$_{\!}$ to$_{\!}$ unify automatic/interactive segmentation within a single model and one training session. Inspired by clustering-based segmentation techniques, S2VNet makes full use of the slice-wise structure of volumetric data by initializing cluster centers from the cluster$_{\!}$ results$_{\!}$ of$_{\!}$ previous$_{\!}$ slice.$_{\!}$ This enables knowledge acquired from prior slices to assist in the segmentation of the current slice, further efficiently bridging the communication between remote slices using mere 2D networks. Moreover, such a framework readily accommodates interactive segmentation with no architectural change, simply by initializing centroids from user inputs. S2VNet distinguishes itself by swift inference speeds and reduced memory consumption compared to prevailing 3D solutions. It can also handle multi-class interactions with each of them serving to initialize different centroids. Experiments on three benchmarks demonstrate S2VNet surpasses task-specified solutions on both automatic/interactive setups.
Neural-Logic Human-Object Interaction Detection
Nov 16, 2023The interaction decoder utilized in prevalent Transformer-based HOI detectors typically accepts pre-composed human-object pairs as inputs. Though achieving remarkable performance, such paradigm lacks feasibility and cannot explore novel combinations over entities during decoding. We present L OGIC HOI, a new HOI detector that leverages neural-logic reasoning and Transformer to infer feasible interactions between entities. Specifically, we modify the self-attention mechanism in vanilla Transformer, enabling it to reason over the <human, action, object> triplet and constitute novel interactions. Meanwhile, such reasoning process is guided by two crucial properties for understanding HOI: affordances (the potential actions an object can facilitate) and proxemics (the spatial relations between humans and objects). We formulate these two properties in first-order logic and ground them into continuous space to constrain the learning process of our approach, leading to improved performance and zero-shot generalization capabilities. We evaluate L OGIC HOI on V-COCO and HICO-DET under both normal and zero-shot setups, achieving significant improvements over existing methods.
LOGICSEG: Parsing Visual Semantics with Neural Logic Learning and Reasoning
Sep 28, 2023Current high-performance semantic segmentation models are purely data-driven sub-symbolic approaches and blind to the structured nature of the visual world. This is in stark contrast to human cognition which abstracts visual perceptions at multiple levels and conducts symbolic reasoning with such structured abstraction. To fill these fundamental gaps, we devise LOGICSEG, a holistic visual semantic parser that integrates neural inductive learning and logic reasoning with both rich data and symbolic knowledge. In particular, the semantic concepts of interest are structured as a hierarchy, from which a set of constraints are derived for describing the symbolic relations and formalized as first-order logic rules. After fuzzy logic-based continuous relaxation, logical formulae are grounded onto data and neural computational graphs, hence enabling logic-induced network training. During inference, logical constraints are packaged into an iterative process and injected into the network in a form of several matrix multiplications, so as to achieve hierarchy-coherent prediction with logic reasoning. These designs together make LOGICSEG a general and compact neural-logic machine that is readily integrated into existing segmentation models. Extensive experiments over four datasets with various segmentation models and backbones verify the effectiveness and generality of LOGICSEG. We believe this study opens a new avenue for visual semantic parsing.
Large-Scale Person Detection and Localization using Overhead Fisheye Cameras
Jul 17, 2023


Location determination finds wide applications in daily life. Instead of existing efforts devoted to localizing tourist photos captured by perspective cameras, in this article, we focus on devising person positioning solutions using overhead fisheye cameras. Such solutions are advantageous in large field of view (FOV), low cost, anti-occlusion, and unaggressive work mode (without the necessity of cameras carried by persons). However, related studies are quite scarce, due to the paucity of data. To stimulate research in this exciting area, we present LOAF, the first large-scale overhead fisheye dataset for person detection and localization. LOAF is built with many essential features, e.g., i) the data cover abundant diversities in scenes, human pose, density, and location; ii) it contains currently the largest number of annotated pedestrian, i.e., 457K bounding boxes with groundtruth location information; iii) the body-boxes are labeled as radius-aligned so as to fully address the positioning challenge. To approach localization, we build a fisheye person detection network, which exploits the fisheye distortions by a rotation-equivariant training strategy and predict radius-aligned human boxes end-to-end. Then, the actual locations of the detected persons are calculated by a numerical solution on the fisheye model and camera altitude data. Extensive experiments on LOAF validate the superiority of our fisheye detector w.r.t. previous methods, and show that our whole fisheye positioning solution is able to locate all persons in FOV with an accuracy of 0.5 m, within 0.1 s.
Segment and Track Anything
May 11, 2023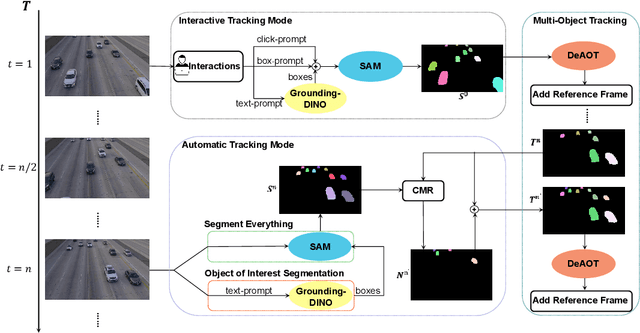
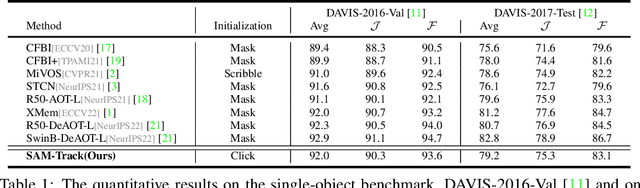


This report presents a framework called Segment And Track Anything (SAMTrack) that allows users to precisely and effectively segment and track any object in a video. Additionally, SAM-Track employs multimodal interaction methods that enable users to select multiple objects in videos for tracking, corresponding to their specific requirements. These interaction methods comprise click, stroke, and text, each possessing unique benefits and capable of being employed in combination. As a result, SAM-Track can be used across an array of fields, ranging from drone technology, autonomous driving, medical imaging, augmented reality, to biological analysis. SAM-Track amalgamates Segment Anything Model (SAM), an interactive key-frame segmentation model, with our proposed AOT-based tracking model (DeAOT), which secured 1st place in four tracks of the VOT 2022 challenge, to facilitate object tracking in video. In addition, SAM-Track incorporates Grounding-DINO, which enables the framework to support text-based interaction. We have demonstrated the remarkable capabilities of SAM-Track on DAVIS-2016 Val (92.0%), DAVIS-2017 Test (79.2%)and its practicability in diverse applications. The project page is available at: https://github.com/z-x-yang/Segment-and-Track-Anything.
Boosting Video Object Segmentation via Space-time Correspondence Learning
Apr 13, 2023Current top-leading solutions for video object segmentation (VOS) typically follow a matching-based regime: for each query frame, the segmentation mask is inferred according to its correspondence to previously processed and the first annotated frames. They simply exploit the supervisory signals from the groundtruth masks for learning mask prediction only, without posing any constraint on the space-time correspondence matching, which, however, is the fundamental building block of such regime. To alleviate this crucial yet commonly ignored issue, we devise a correspondence-aware training framework, which boosts matching-based VOS solutions by explicitly encouraging robust correspondence matching during network learning. Through comprehensively exploring the intrinsic coherence in videos on pixel and object levels, our algorithm reinforces the standard, fully supervised training of mask segmentation with label-free, contrastive correspondence learning. Without neither requiring extra annotation cost during training, nor causing speed delay during deployment, nor incurring architectural modification, our algorithm provides solid performance gains on four widely used benchmarks, i.e., DAVIS2016&2017, and YouTube-VOS2018&2019, on the top of famous matching-based VOS solutions.