 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-Scale Person Detection and Localization using Overhead Fisheye Cameras
Jul 17, 2023


Location determination finds wide applications in daily life. Instead of existing efforts devoted to localizing tourist photos captured by perspective cameras, in this article, we focus on devising person positioning solutions using overhead fisheye cameras. Such solutions are advantageous in large field of view (FOV), low cost, anti-occlusion, and unaggressive work mode (without the necessity of cameras carried by persons). However, related studies are quite scarce, due to the paucity of data. To stimulate research in this exciting area, we present LOAF, the first large-scale overhead fisheye dataset for person detection and localization. LOAF is built with many essential features, e.g., i) the data cover abundant diversities in scenes, human pose, density, and location; ii) it contains currently the largest number of annotated pedestrian, i.e., 457K bounding boxes with groundtruth location information; iii) the body-boxes are labeled as radius-aligned so as to fully address the positioning challenge. To approach localization, we build a fisheye person detection network, which exploits the fisheye distortions by a rotation-equivariant training strategy and predict radius-aligned human boxes end-to-end. Then, the actual locations of the detected persons are calculated by a numerical solution on the fisheye model and camera altitude data. Extensive experiments on LOAF validate the superiority of our fisheye detector w.r.t. previous methods, and show that our whole fisheye positioning solution is able to locate all persons in FOV with an accuracy of 0.5 m, within 0.1 s.
Quality-Aware Network for Face Parsing
Jun 14, 2021
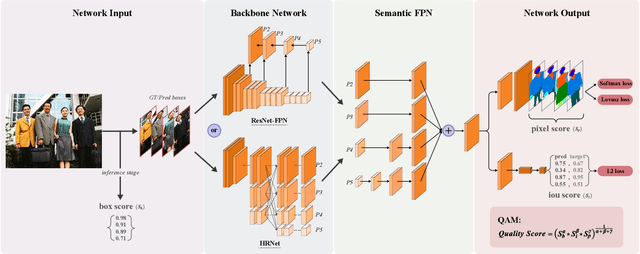


This is a very short technical report, which introduces the solution of the Team BUPT-CASIA for Short-video Face Parsing Track of The 3rd Person in Context (PIC) Workshop and Challenge at CVPR 2021. Face parsing has recently attracted increasing interest due to its numerous application potentials. Generally speaking, it has a lot in common with human parsing, such as task setting, data characteristics, number of categories and so on. Therefore, this work applies state-of-the-art human parsing method to face parsing task to explore the similarities and differences between them. Our submission achieves 86.84% score and wins the 2nd place in the challenge.
Renovating Parsing R-CNN for Accurate Multiple Human Parsing
Sep 20, 2020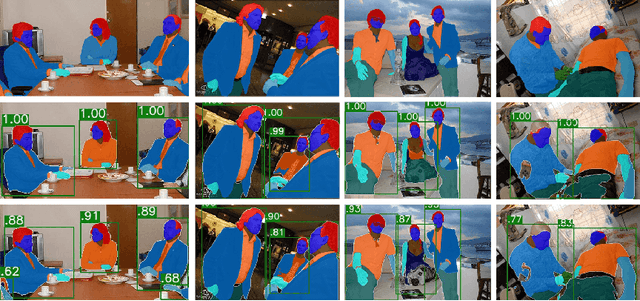

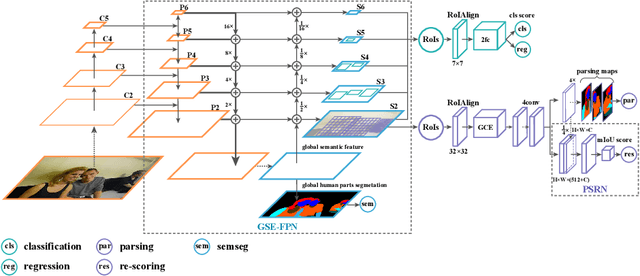
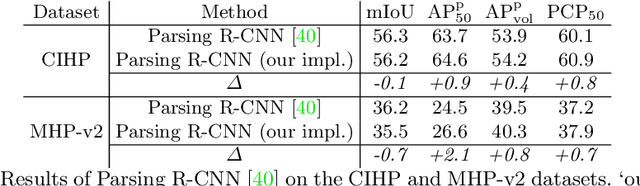
Multiple human parsing aims to segment various human parts and associate each part with the corresponding instance simultaneously. This is a very challenging task due to the diverse human appearance, semantic ambiguity of different body parts, and complex background. Through analysis of multiple human parsing task, we observe that human-centric global perception and accurate instance-level parsing scoring are crucial for obtaining high-quality results. But the most state-of-the-art methods have not paid enough attention to these issues. To reverse this phenomenon, we present Renovating Parsing R-CNN (RP R-CNN), which introduces a global semantic enhanced feature pyramid network and a parsing re-scoring network into the existing high-performance pipeline. The proposed RP R-CNN adopts global semantic representation to enhance multi-scale features for generating human parsing maps, and regresses a confidence score to represent its quality. Extensive experiments show that RP R-CNN performs favorably against state-of-the-art methods on CIHP and MHP-v2 datasets. Code and models are available at https://github.com/soeaver/RP-R-CNN.