 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabOSBench: Benchmarking Computer Use Agents for Scientific Instrument Control
Jun 15, 2026Current computer-use benchmarks primarily focus on software operation tasks in virtualized systems, whereas scientific instrumentation scenarios require coordinated control over complex interfaces, and feedback-driven parameter adjustment. However, directly evaluating agents on physical high-precision instruments is impractical due to high cost, safety risks, limited accessibility, and difficulty in ensuring reproducible evaluation. This motivates the need for a simulated yet realistic testbed that preserves the operational challenges of scientific instruments while enabling scalable and safe benchmarking. To this end, we introduce LabOSBench, a challenging benchmark for multimodal GUI agents built on a suite of web-based scientific-instrument simulators. Operating directly via a browser, LabOSBench avoids resource-heavy OS virtualization while supporting flexible task configuration and execution-based evaluation. Specifically, LabOSBench constructs 96 subtasks across eight instrument simulators, covering workflows from sample loading, alignment, parameter tuning, and data acquisition to result inspection. We evaluate general-purpose vision-language models, specialized GUI agent models, and advanced agentic frameworks at both subtask and end-to-end levels. Our experiments reveal that while existing agents can complete many structured GUI subtasks, they still struggle with feedback-driven operations and long-horizon workflow execution. Overall, LabOSBench provides a reproducible, low-cost testbed for advancing computer-using agents toward scientific-instrument control.
Owl-AuraID 1.0: An Intelligent System for Autonomous Scientific Instrumentation and Scientific Data Analysis
Mar 31, 2026Scientific discovery increasingly depends on high-throughput characterization, yet automation is hindered by proprietary GUIs and the limited generalizability of existing API-based systems. We present Owl-AuraID, a software-hardware collaborative embodied agent system that adopts a GUI-native paradigm to operate instruments through the same interfaces as human experts. Its skill-centric framework integrates Type-1 (GUI operation) and Type-2 (data analysis) skills into end-to-end workflows, connecting physical sample handling with scientific interpretation. Owl-AuraID demonstrates broad coverage across ten categories of precision instruments and diverse workflows, including multimodal spectral analysis, microscopic imaging, and crystallographic analysis, supporting modalities such as FTIR, NMR, AFM, and TGA. Overall, Owl-AuraID provides a practical, extensible foundation for autonomous laboratories and illustrates a path toward evolving laboratory intelligence through reusable operational and analytical skills. The code are available at https://github.com/OpenOwlab/AuraID.
FD$^2$: A Dedicated Framework for Fine-Grained Dataset Distillation
Mar 26, 2026Dataset distillation (DD) compresses a large training set into a small synthetic set, reducing storage and training cost, and has shown strong results on general benchmarks. Decoupled DD further improves efficiency by splitting the pipeline into pretraining, sample distillation, and soft-label generation. However, existing decoupled methods largely rely on coarse class-label supervision and optimize samples within each class in a nearly identical manner. On fine-grained datasets, this often yields distilled samples that (i) retain large intra-class variation with subtle inter-class differences and (ii) become overly similar within the same class, limiting localized discriminative cues and hurting recognition. To solve the above-mentioned problems, we propose FD$^{2}$, a dedicated framework for Fine-grained Dataset Distillation. FD$^{2}$ localizes discriminative regions and constructs fine-grained representations for distillation. During pretraining, counterfactual attention learning aggregates discriminative representations to update class prototypes. During distillation, a fine-grained characteristic constraint aligns each sample with its class prototype while repelling others, and a similarity constraint diversifies attention across same-class samples. Experiments on multiple fine-grained and general datasets show that FD$^{2}$ integrates seamlessly with decoupled DD and improves performance in most settings, indicating strong transferability.
Towards Governance-Oriented Low-Altitude Intelligence: A Management-Centric Multi-Modal Benchmark With Implicitly Coordinated Vision-Language Reasoning Framework
Jan 27, 2026Low-altitude vision systems are becoming a critical infrastructure for smart city governance. However, existing object-centric perception paradigms and loosely coupled vision-language pipelines are still difficult to support management-oriented anomaly understanding required in real-world urban governance. To bridge this gap, we introduce GovLA-10K, the first management-oriented multi-modal benchmark for low-altitude intelligence, along with GovLA-Reasoner, a unified vision-language reasoning framework tailored for governance-aware aerial perception. Unlike existing studies that aim to exhaustively annotate all visible objects, GovLA-10K is deliberately designed around functionally salient targets that directly correspond to practical management needs, and further provides actionable management suggestions grounded in these observations. To effectively coordinate the fine-grained visual grounding with high-level contextual language reasoning, GovLA-Reasoner introduces an efficient feature adapter that implicitly coordinates discriminative representation sharing between the visual detector and the large language model (LLM). Extensive experiments show that our method significantly improves performance while avoiding the need of fine-tuning for any task-specific individual components. We believe our work offers a new perspective and foundation for future studies on management-aware low-altitude vision-language systems.
Toward Multi-Fidelity Machine Learning Force Field for Cathode Materials
Nov 14, 2025Machine learning force fields (MLFFs), which employ neural networks to map atomic structures to system energies, effectively combine the high accuracy of first-principles calculation with the computational efficiency of empirical force fields. They are widely used in computational materials simulations. However, the development and application of MLFFs for lithium-ion battery cathode materials remain relatively limited. This is primarily due to the complex electronic structure characteristics of cathode materials and the resulting scarcity of high-quality computational datasets available for force field training. In this work, we develop a multi-fidelity machine learning force field framework to enhance the data efficiency of computational results, which can simultaneously utilize both low-fidelity non-magnetic and high-fidelity magnetic computational datasets of cathode materials for training. Tests conducted on the lithium manganese iron phosphate (LMFP) cathode material system demonstrate the effectiveness of this multi-fidelity approach. This work helps to achieve high-accuracy MLFF training for cathode materials at a lower training dataset cost, and offers new perspectives for applying MLFFs to computational simulations of cathode materials.
Propagating Sparse Depth via Depth Foundation Model for Out-of-Distribution Depth Completion
Aug 07, 2025
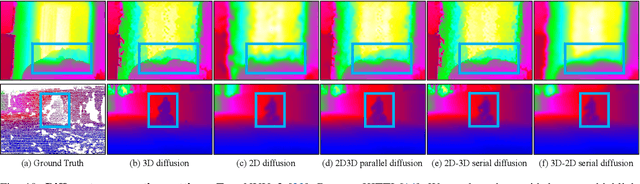

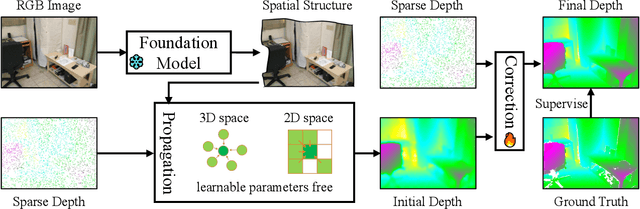
Depth completion is a pivotal challenge in computer vision, aiming at reconstructing the dense depth map from a sparse one, typically with a paired RGB image. Existing learning based models rely on carefully prepared but limited data, leading to significant performance degradation in out-of-distribution (OOD) scenarios. Recent foundation models have demonstrated exceptional robustness in monocular depth estimation through large-scale training, and using such models to enhance the robustness of depth completion models is a promising solution. In this work, we propose a novel depth completion framework that leverages depth foundation models to attain remarkable robustness without large-scale training. Specifically, we leverage a depth foundation model to extract environmental cues, including structural and semantic context, from RGB images to guide the propagation of sparse depth information into missing regions. We further design a dual-space propagation approach, without any learnable parameters, to effectively propagates sparse depth in both 3D and 2D spaces to maintain geometric structure and local consistency. To refine the intricate structure, we introduce a learnable correction module to progressively adjust the depth prediction towards the real depth. We train our model on the NYUv2 and KITTI datasets as in-distribution datasets and extensively evaluate the framework on 16 other datasets. Our framework performs remarkably well in the OOD scenarios and outperforms existing state-of-the-art depth completion methods. Our models are released in https://github.com/shenglunch/PSD.
3DAxisPrompt: Promoting the 3D Grounding and Reasoning in GPT-4o
Mar 17, 2025Multimodal Large Language Models (MLLMs) exhibit impressive capabilities across a variety of tasks, especially when equipped with carefully designed visual prompts. However, existing studies primarily focus on logical reasoning and visual understanding, while the capability of MLLMs to operate effectively in 3D vision remains an ongoing area of exploration. In this paper, we introduce a novel visual prompting method, called 3DAxisPrompt, to elicit the 3D understanding capabilities of MLLMs in real-world scenes. More specifically, our method leverages the 3D coordinate axis and masks generated from the Segment Anything Model (SAM) to provide explicit geometric priors to MLLMs and then extend their impressive 2D grounding and reasoning ability to real-world 3D scenarios. Besides, we first provide a thorough investigation of the potential visual prompting formats and conclude our findings to reveal the potential and limits of 3D understanding capabilities in GPT-4o, as a representative of MLLMs. Finally, we build evaluation environments with four datasets, i.e., ScanRefer, ScanNet, FMB, and nuScene datasets, covering various 3D tasks. Based on this, we conduct extensive quantitative and qualitative experiments, which demonstrate the effectiveness of the proposed method. Overall, our study reveals that MLLMs, with the help of 3DAxisPrompt, can effectively perceive an object's 3D position in real-world scenarios. Nevertheless, a single prompt engineering approach does not consistently achieve the best outcomes for all 3D tasks. This study highlights the feasibility of leveraging MLLMs for 3D vision grounding/reasoning with prompt engineering techniques.
Commenting Higher-level Code Unit: Full Code, Reduced Code, or Hierarchical Code Summarization
Mar 13, 2025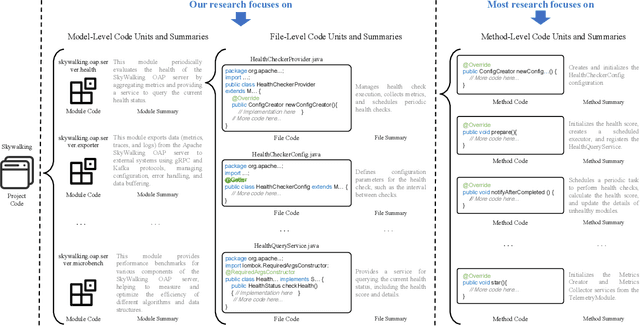

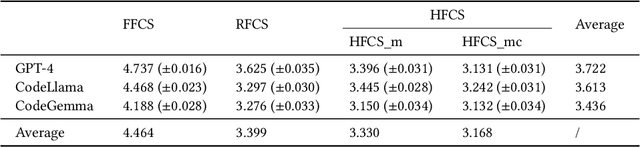

Commenting code is a crucial activity in software development, as it aids in facilitating future maintenance and updates. To enhance the efficiency of writing comments and reduce developers' workload, researchers has proposed various automated code summarization (ACS) techniques to automatically generate comments/summaries for given code units. However, these ACS techniques primarily focus on generating summaries for code units at the method level. There is a significant lack of research on summarizing higher-level code units, such as file-level and module-level code units, despite the fact that summaries of these higher-level code units are highly useful for quickly gaining a macro-level understanding of software components and architecture. To fill this gap, in this paper, we conduct a systematic study on how to use LLMs for commenting higher-level code units, including file level and module level. These higher-level units are significantly larger than method-level ones, which poses challenges in handling long code inputs within LLM constraints and maintaining efficiency. To address these issues, we explore various summarization strategies for ACS of higher-level code units, which can be divided into three types: full code summarization, reduced code summarization, and hierarchical code summarization. The experimental results suggest that for summarizing file-level code units, using the full code is the most effective approach, with reduced code serving as a cost-efficient alternative. However, for summarizing module-level code units, hierarchical code summarization becomes the most promising strategy. In addition, inspired by the research on method-level ACS, we also investigate using the LLM as an evaluator to evaluate the quality of summaries of higher-level code units. The experimental results demonstrate that the LLM's evaluation results strongly correlate with human evaluations.
SeisMoLLM: Advancing Seismic Monitoring via Cross-modal Transfer with Pre-trained Large Language Model
Feb 27, 2025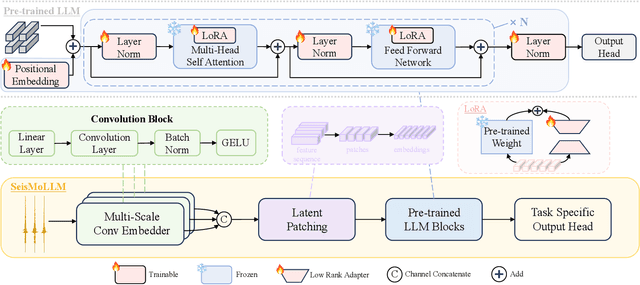
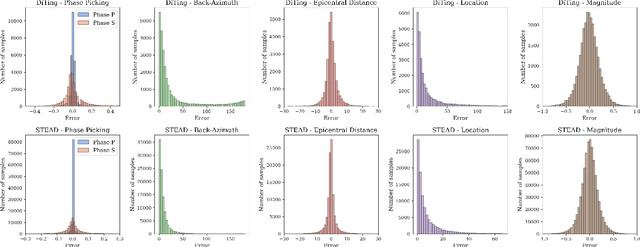
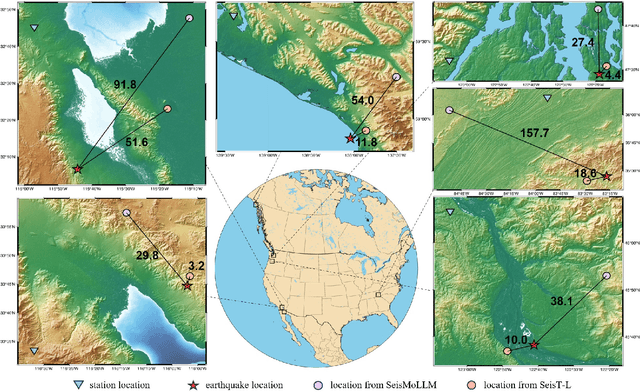
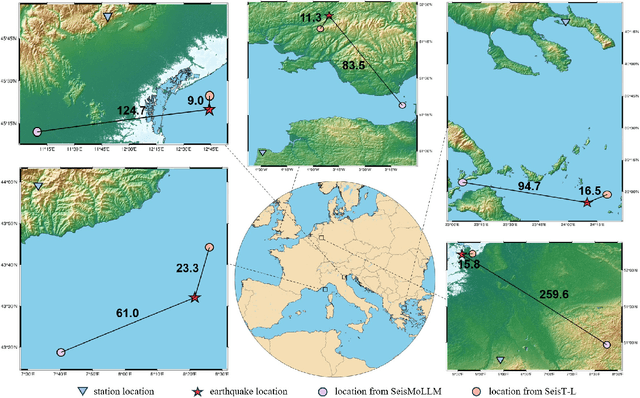
Recent advances in deep learning have revolutionized seismic monitoring, yet developing a foundation model that performs well across multiple complex tasks remains challenging, particularly when dealing with degraded signals or data scarcity. This work presents SeisMoLLM, the first foundation model that utilizes cross-modal transfer for seismic monitoring, to unleash the power of large-scale pre-training from a large language model without requiring direct pre-training on seismic datasets. Through elaborate waveform tokenization and fine-tuning of pre-trained GPT-2 model, SeisMoLLM achieves state-of-the-art performance on the DiTing and STEAD datasets across five critical tasks: back-azimuth estimation, epicentral distance estimation, magnitude estimation, phase picking, and first-motion polarity classification. It attains 36 best results out of 43 task metrics and 12 top scores out of 16 few-shot generalization metrics, with many relative improvements ranging from 10% to 50%. In addition to its superior performance, SeisMoLLM maintains efficiency comparable to or even better than lightweight models in both training and inference. These findings establish SeisMoLLM as a promising foundation model for practical seismic monitoring and highlight cross-modal transfer as an exciting new direction for earthquake studies, showcasing the potential of advanced deep learning techniques to propel seismology research forward.
Towards Efficient and Intelligent Laser Weeding: Method and Dataset for Weed Stem Detection
Feb 10, 2025



Weed control is a critical challenge in modern agriculture, as weeds compete with crops for essential nutrient resources, significantly reducing crop yield and quality. Traditional weed control methods, including chemical and mechanical approaches, have real-life limitations such as associated environmental impact and efficiency. An emerging yet effective approach is laser weeding, which uses a laser beam as the stem cutter. Although there have been studies that use deep learning in weed recognition, its application in intelligent laser weeding still requires a comprehensive understanding. Thus, this study represents the first empirical investigation of weed recognition for laser weeding. To increase the efficiency of laser beam cut and avoid damaging the crops of interest, the laser beam shall be directly aimed at the weed root. Yet, weed stem detection remains an under-explored problem. We integrate the detection of crop and weed with the localization of weed stem into one end-to-end system. To train and validate the proposed system in a real-life scenario, we curate and construct a high-quality weed stem detection dataset with human annotations. The dataset consists of 7,161 high-resolution pictures collected in the field with annotations of 11,151 instances of weed. Experimental results show that the proposed system improves weeding accuracy by 6.7% and reduces energy cost by 32.3% compared to existing weed recognition systems.