 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 1st PortraitCraft Challenge: A CVPR 2026 Workshop Competition on Portrait Composition Understanding and Generation
Jun 09, 2026This paper presents an overview of the inaugural PortraitCraft Challenge, held as one of the official competitions at CVPR 2026. The challenge focuses on portrait composition understanding and generation, aiming to advance AI research in portrait aesthetics analysis and controllable image synthesis. Unlike existing datasets and tasks that primarily focus on global aesthetic scoring, PortraitCraft introduces a unified evaluation framework comprising two complementary tracks. Track 1 requires models to perform structured portrait composition understanding, and Track 2 requires models to generate portrait images from structured composition descriptions under explicit compositional constraints. To support the challenge, we constructed and publicly released a large-scale portrait composition dataset consisting of approximately 50,000 curated real portrait images, providing multi-level supervision. This report describes the challenge setup, evaluation protocols, dataset composition, and final results, along with an analysis of the technical characteristics of the submitted solutions. The PortraitCraft Challenge provides a standardized and reproducible platform for research on portrait composition understanding and generation, and is expected to foster further progress in the fields of portrait aesthetics and controllable image generation.
TextFake: Benchmarking AI-Generated Image Detection on Text-Rich Images
May 31, 2026Recent AI-generated image (AIGI) detectors perform well on natural-image benchmarks, but their behavior on text-rich forgeries, such as fabricated screenshots, documents, and news pages prevalent in misinformation, remains untested. We introduce TextFake, a 20,000-image benchmark for text-rich AIGI detection spanning 28 languages, 4 topic categories, and 2 scene modalities. Fake images are synthesized via a four-stage pipeline that annotates real images along three controlled dimensions and generates counterparts through distribution-aligned structured prompting, ruling out covariate shortcuts. Zero-shot evaluation of 14 specialized detectors and 3 frontier VLM APIs reveals a large systematic gap: no method exceeds 80% accuracy, with some dropping over 60% from natural-image benchmarks. Diagnostic evaluations identify three failure modes: the Text Density Curse, where dense glyphs overwhelm low-level detectors; Cloaking via Rendering Fidelity, where stronger text rendering suppresses enerative artifacts; and Threshold Collapse, where routine perturbations drive detectors toward chance-level performance.
TRACE: A Multi-Agent System for Autonomous Physical Reasoning in Seismological Science
Mar 22, 2026Inferring the physical mechanisms that govern earthquake sequences from indirect geophysical observations remains difficult, particularly across tectonically distinct environments where similar seismic patterns can reflect different underlying processes. Current interpretations rely heavily on the expert synthesis of catalogs, spatiotemporal statistics, and candidate physical models, limiting reproducibility and the systematic transfer of insight across settings. Here we present TRACE (Trans-perspective Reasoning and Automated Comprehensive Evaluator), a multi-agent system that combines large language model planning with formal seismological constraints to derive auditable, physically grounded mechanistic inference from raw observations. Applied to the 2019 Ridgecrest sequence, TRACE autonomously identifies stress-perturbation-induced delayed triggering, resolving the cascading interaction between the Mw 6.4 and Mw 7.1 mainshocks; in the Santorini-Kolumbo case, the system identifies a structurally guided intrusion model, distinguishing fault-channeled episodic migration from the continuous propagation expected in homogeneous crustal failure. By providing a generalizable logical infrastructure for interpreting heterogeneous seismic phenomena, TRACE advances the field from expert-dependent analysis toward knowledge-guided autonomous discovery in Earth sciences.
RiO-DETR: DETR for Real-time Oriented Object Detection
Mar 10, 2026We present RiO-DETR: DETR for Real-time Oriented Object Detection, the first real-time oriented detection transformer to the best of our knowledge. Adapting DETR to oriented bounding boxes (OBBs) poses three challenges: semantics-dependent orientation, angle periodicity that breaks standard Euclidean refinement, and an enlarged search space that slows convergence. RiO-DETR resolves these issues with task-native designs while preserving real-time efficiency. First, we propose Content-Driven Angle Estimation by decoupling angle from positional queries, together with Rotation-Rectified Orthogonal Attention to capture complementary cues for reliable orientation. Second, Decoupled Periodic Refinement combines bounded coarse-to-fine updates with a Shortest-Path Periodic Loss for stable learning across angular seams. Third, Oriented Dense O2O injects angular diversity into dense supervision to speed up angle convergence at no extra cost. Extensive experiments on DOTA-1.0, DIOR-R, and FAIR-1M-2.0 demonstrate RiO-DETR establishes a new speed--accuracy trade-off for real-time oriented detection. Code will be made publicly available.
Prism: Spectral-Aware Block-Sparse Attention
Feb 09, 2026Block-sparse attention is promising for accelerating long-context LLM pre-filling, yet identifying relevant blocks efficiently remains a bottleneck. Existing methods typically employ coarse-grained attention as a proxy for block importance estimation, but often resort to expensive token-level searching or scoring, resulting in significant selection overhead. In this work, we trace the inaccuracy of standard coarse-grained attention via mean pooling to a theoretical root cause: the interaction between mean pooling and Rotary Positional Embeddings (RoPE). We prove that mean pooling acts as a low-pass filter that induces destructive interference in high-frequency dimensions, effectively creating a "blind spot" for local positional information (e.g., slash patterns). To address this, we introduce Prism, a training-free spectral-aware approach that decomposes block selection into high-frequency and low-frequency branches. By applying energy-based temperature calibration, Prism restores the attenuated positional signals directly from pooled representations, enabling block importance estimation using purely block-level operations, thereby improving efficiency. Extensive evaluations confirm that Prism maintains accuracy parity with full attention while delivering up to $\mathbf{5.1\times}$ speedup.
SAPL: Semantic-Agnostic Prompt Learning in CLIP for Weakly Supervised Image Manipulation Localization
Jan 09, 2026Malicious image manipulation threatens public safety and requires efficient localization methods. Existing approaches depend on costly pixel-level annotations which make training expensive. Existing weakly supervised methods rely only on image-level binary labels and focus on global classification, often overlooking local edge cues that are critical for precise localization. We observe that feature variations at manipulated boundaries are substantially larger than in interior regions. To address this gap, we propose Semantic-Agnostic Prompt Learning (SAPL) in CLIP, which learns text prompts that intentionally encode non-semantic, boundary-centric cues so that CLIPs multimodal similarity highlights manipulation edges rather than high-level object semantics. SAPL combines two complementary modules Edge-aware Contextual Prompt Learning (ECPL) and Hierarchical Edge Contrastive Learning (HECL) to exploit edge information in both textual and visual spaces. The proposed ECPL leverages edge-enhanced image features to generate learnable textual prompts via an attention mechanism, embedding semantic-irrelevant information into text features, to guide CLIP focusing on manipulation edges. The proposed HECL extract genuine and manipulated edge patches, and utilize contrastive learning to boost the discrimination between genuine edge patches and manipulated edge patches. Finally, we predict the manipulated regions from the similarity map after processing. Extensive experiments on multiple public benchmarks demonstrate that SAPL significantly outperforms existing approaches, achieving state-of-the-art localization performance.
Decoupled Proxy Alignment: Mitigating Language Prior Conflict for Multimodal Alignment in MLLM
Sep 18, 2025Multimodal large language models (MLLMs) have gained significant attention due to their impressive ability to integrate vision and language modalities. Recent advancements in MLLMs have primarily focused on improving performance through high-quality datasets, novel architectures, and optimized training strategies. However, in this paper, we identify a previously overlooked issue, language prior conflict, a mismatch between the inherent language priors of large language models (LLMs) and the language priors in training datasets. This conflict leads to suboptimal vision-language alignment, as MLLMs are prone to adapting to the language style of training samples. To address this issue, we propose a novel training method called Decoupled Proxy Alignment (DPA). DPA introduces two key innovations: (1) the use of a proxy LLM during pretraining to decouple the vision-language alignment process from language prior interference, and (2) dynamic loss adjustment based on visual relevance to strengthen optimization signals for visually relevant tokens. Extensive experiments demonstrate that DPA significantly mitigates the language prior conflict, achieving superior alignment performance across diverse datasets, model families, and scales. Our method not only improves the effectiveness of MLLM training but also shows exceptional generalization capabilities, making it a robust approach for vision-language alignment. Our code is available at https://github.com/fnlp-vision/DPA.
UnifiedVisual: A Framework for Constructing Unified Vision-Language Datasets
Sep 18, 2025Unified vision large language models (VLLMs) have recently achieved impressive advancements in both multimodal understanding and generation, powering applications such as visual question answering and text-guided image synthesis. However, progress in unified VLLMs remains constrained by the lack of datasets that fully exploit the synergistic potential between these two core abilities. Existing datasets typically address understanding and generation in isolation, thereby limiting the performance of unified VLLMs. To bridge this critical gap, we introduce a novel dataset construction framework, UnifiedVisual, and present UnifiedVisual-240K, a high-quality dataset meticulously designed to facilitate mutual enhancement between multimodal understanding and generation. UnifiedVisual-240K seamlessly integrates diverse visual and textual inputs and outputs, enabling comprehensive cross-modal reasoning and precise text-to-image alignment. Our dataset encompasses a wide spectrum of tasks and data sources, ensuring rich diversity and addressing key shortcomings of prior resources. Extensive experiments demonstrate that models trained on UnifiedVisual-240K consistently achieve strong performance across a wide range of tasks. Notably, these models exhibit significant mutual reinforcement between multimodal understanding and generation, further validating the effectiveness of our framework and dataset. We believe UnifiedVisual represents a new growth point for advancing unified VLLMs and unlocking their full potential. Our code and datasets is available at https://github.com/fnlp-vision/UnifiedVisual.
Context-Aware Weakly Supervised Image Manipulation Localization with SAM Refinement
Mar 26, 2025Malicious image manipulation poses societal risks, increasing the importance of effective image manipulation detection methods. Recent approaches in image manipulation detection have largely been driven by fully supervised approaches, which require labor-intensive pixel-level annotations. Thus, it is essential to explore weakly supervised image manipulation localization methods that only require image-level binary labels for training. However, existing weakly supervised image manipulation methods overlook the importance of edge information for accurate localization, leading to suboptimal localization performance. To address this, we propose a Context-Aware Boundary Localization (CABL) module to aggregate boundary features and learn context-inconsistency for localizing manipulated areas. Furthermore, by leveraging Class Activation Mapping (CAM) and Segment Anything Model (SAM), we introduce the CAM-Guided SAM Refinement (CGSR) module to generate more accurate manipulation localization maps. By integrating two modules, we present a novel weakly supervised framework based on a dual-branch Transformer-CNN architecture. Our method achieves outstanding localization performance across multiple datasets.
SeisMoLLM: Advancing Seismic Monitoring via Cross-modal Transfer with Pre-trained Large Language Model
Feb 27, 2025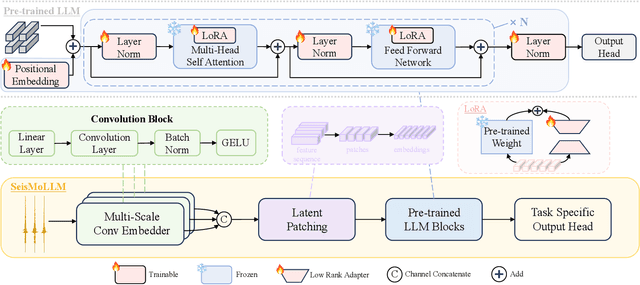
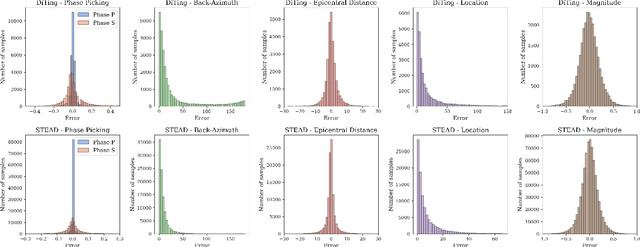
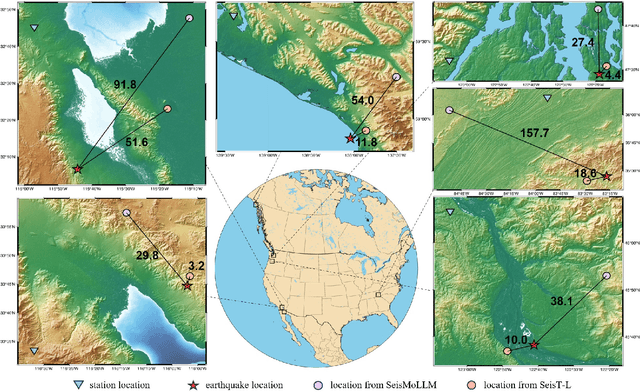
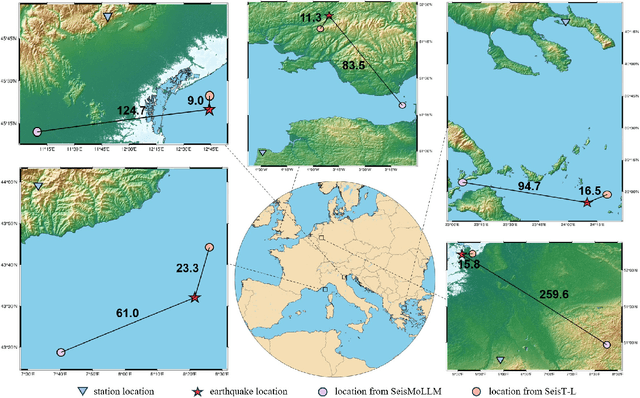
Recent advances in deep learning have revolutionized seismic monitoring, yet developing a foundation model that performs well across multiple complex tasks remains challenging, particularly when dealing with degraded signals or data scarcity. This work presents SeisMoLLM, the first foundation model that utilizes cross-modal transfer for seismic monitoring, to unleash the power of large-scale pre-training from a large language model without requiring direct pre-training on seismic datasets. Through elaborate waveform tokenization and fine-tuning of pre-trained GPT-2 model, SeisMoLLM achieves state-of-the-art performance on the DiTing and STEAD datasets across five critical tasks: back-azimuth estimation, epicentral distance estimation, magnitude estimation, phase picking, and first-motion polarity classification. It attains 36 best results out of 43 task metrics and 12 top scores out of 16 few-shot generalization metrics, with many relative improvements ranging from 10% to 50%. In addition to its superior performance, SeisMoLLM maintains efficiency comparable to or even better than lightweight models in both training and inference. These findings establish SeisMoLLM as a promising foundation model for practical seismic monitoring and highlight cross-modal transfer as an exciting new direction for earthquake studies, showcasing the potential of advanced deep learning techniques to propel seismology research forward.