 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoSent: A Denoising Objective for Self-Supervised Sentence Representation Learning
Jan 24, 2024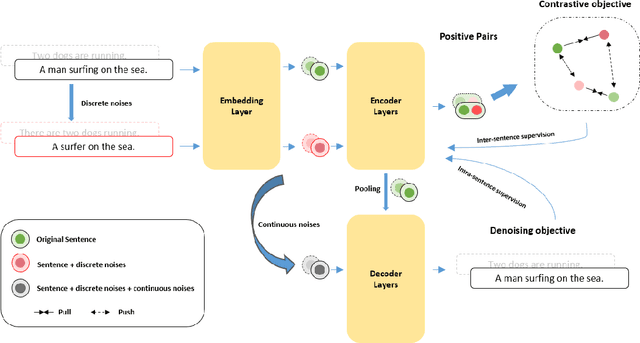
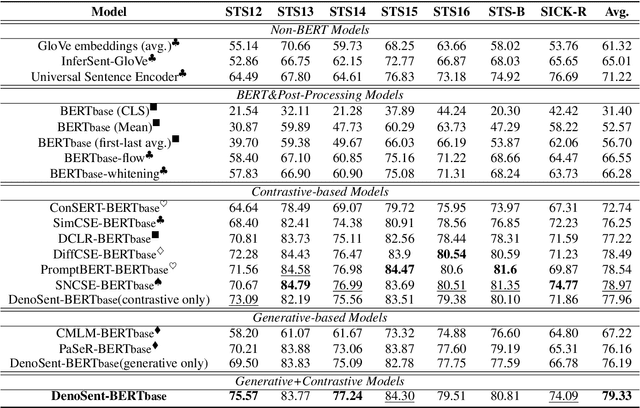
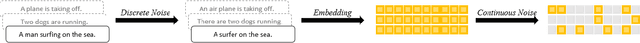
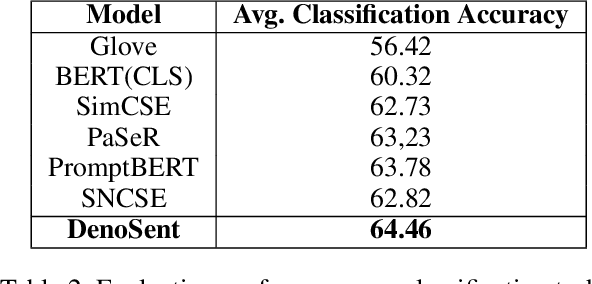
Contrastive-learning-based methods have dominated sentence representation learning. These methods regularize the representation space by pulling similar sentence representations closer and pushing away the dissimilar ones and have been proven effective in various NLP tasks, e.g., semantic textual similarity (STS) tasks. However, it is challenging for these methods to learn fine-grained semantics as they only learn from the inter-sentence perspective, i.e., their supervision signal comes from the relationship between data samples. In this work, we propose a novel denoising objective that inherits from another perspective, i.e., the intra-sentence perspective. By introducing both discrete and continuous noise, we generate noisy sentences and then train our model to restore them to their original form. Our empirical evaluations demonstrate that this approach delivers competitive results on both semantic textual similarity (STS) and a wide range of transfer tasks, standing up well in comparison to contrastive-learning-based methods. Notably, the proposed intra-sentence denoising objective complements existing inter-sentence contrastive methodologies and can be integrated with them to further enhance performance. Our code is available at https://github.com/xinghaow99/DenoSent.
Evaluating Hallucinations in Chinese Large Language Models
Oct 05, 2023



In this paper, we establish a benchmark named HalluQA (Chinese Hallucination Question-Answering) to measure the hallucination phenomenon in Chinese large language models. HalluQA contains 450 meticulously designed adversarial questions, spanning multiple domains, and takes into account Chinese historical culture, customs, and social phenomena. During the construction of HalluQA, we consider two types of hallucinations: imitative falsehoods and factual errors, and we construct adversarial samples based on GLM-130B and ChatGPT. For evaluation, we design an automated evaluation method using GPT-4 to judge whether a model output is hallucinated. We conduct extensive experiments on 24 large language models, including ERNIE-Bot, Baichuan2, ChatGLM, Qwen, SparkDesk and etc. Out of the 24 models, 18 achieved non-hallucination rates lower than 50%. This indicates that HalluQA is highly challenging. We analyze the primary types of hallucinations in different types of models and their causes. Additionally, we discuss which types of hallucinations should be prioritized for different types of models.
BERTScore is Unfair: On Social Bias in Language Model-Based Metrics for Text Generation
Oct 14, 2022
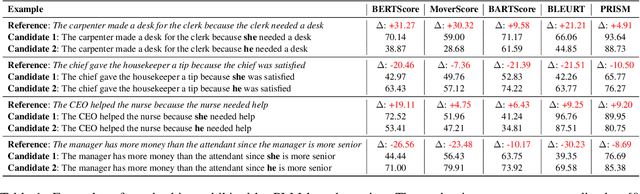

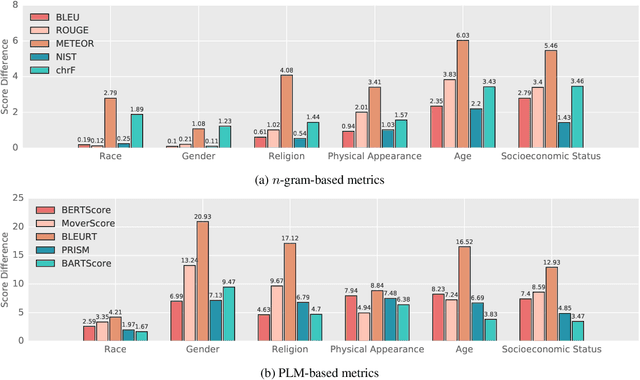
Automatic evaluation metrics are crucial to the development of generative systems. In recent years, pre-trained language model (PLM) based metrics, such as BERTScore, have been commonly adopted in various generation tasks. However, it has been demonstrated that PLMs encode a range of stereotypical societal biases, leading to a concern on the fairness of PLMs as metrics. To that end, this work presents the first systematic study on the social bias in PLM-based metrics. We demonstrate that popular PLM-based metrics exhibit significantly higher social bias than traditional metrics on 6 sensitive attributes, namely race, gender, religion, physical appearance, age, and socioeconomic status. In-depth analysis suggests that choosing paradigms (matching, regression, or generation) of the metric has a greater impact on fairness than choosing PLMs. In addition, we develop debiasing adapters that are injected into PLM layers, mitigating bias in PLM-based metrics while retaining high performance for evaluating text generation.
Towards Efficient NLP: A Standard Evaluation and A Strong Baseline
Oct 13, 2021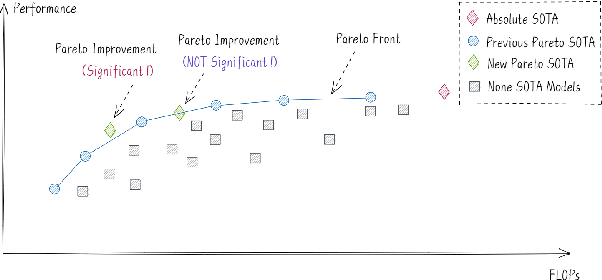
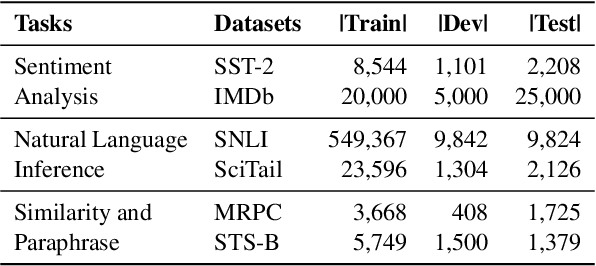
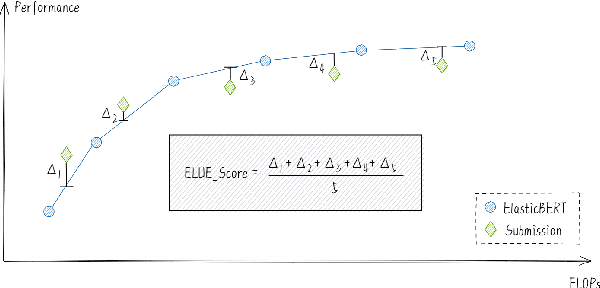
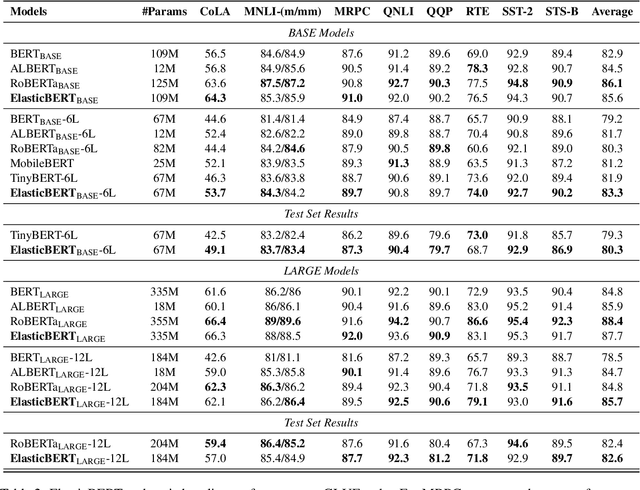
Supersized pre-trained language models have pushed the accuracy of various NLP tasks to a new state-of-the-art (SOTA). Rather than pursuing the reachless SOTA accuracy, most works are pursuing improvement on other dimensions such as efficiency, leading to "Pareto SOTA". Different from accuracy, the metric for efficiency varies across different studies, making them hard to be fairly compared. To that end, this work presents ELUE (Efficient Language Understanding Evaluation), a standard evaluation, and a public leaderboard for efficient NLP models. ELUE is dedicated to depicting the Pareto Front for various language understanding tasks, such that it can tell whether and how much a method achieves Pareto improvement. Along with the benchmark, we also pre-train and release a strong baseline, ElasticBERT, whose elasticity is both static and dynamic. ElasticBERT is static in that it allows reducing model layers on demand. ElasticBERT is dynamic in that it selectively executes parts of model layers conditioned on the input. We demonstrate the ElasticBERT, despite its simplicity, outperforms or performs on par with SOTA compressed and early exiting models. The ELUE benchmark is publicly available at http://eluebenchmark.fastnlp.top/.