 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Jun 16, 2025



We introduce MiniMax-M1, the world's first open-weight, large-scale hybrid-attention reasoning model. MiniMax-M1 is powered by a hybrid Mixture-of-Experts (MoE) architecture combined with a lightning attention mechanism. The model is developed based on our previous MiniMax-Text-01 model, which contains a total of 456 billion parameters with 45.9 billion parameters activated per token. The M1 model natively supports a context length of 1 million tokens, 8x the context size of DeepSeek R1. Furthermore, the lightning attention mechanism in MiniMax-M1 enables efficient scaling of test-time compute. These properties make M1 particularly suitable for complex tasks that require processing long inputs and thinking extensively. MiniMax-M1 is trained using large-scale reinforcement learning (RL) on diverse problems including sandbox-based, real-world software engineering environments. In addition to M1's inherent efficiency advantage for RL training, we propose CISPO, a novel RL algorithm to further enhance RL efficiency. CISPO clips importance sampling weights rather than token updates, outperforming other competitive RL variants. Combining hybrid-attention and CISPO enables MiniMax-M1's full RL training on 512 H800 GPUs to complete in only three weeks, with a rental cost of just $534,700. We release two versions of MiniMax-M1 models with 40K and 80K thinking budgets respectively, where the 40K model represents an intermediate phase of the 80K training. Experiments on standard benchmarks show that our models are comparable or superior to strong open-weight models such as the original DeepSeek-R1 and Qwen3-235B, with particular strengths in complex software engineering, tool utilization, and long-context tasks. We publicly release MiniMax-M1 at https://github.com/MiniMax-AI/MiniMax-M1.
Domain2Vec: Vectorizing Datasets to Find the Optimal Data Mixture without Training
Jun 12, 2025



We introduce~\textsc{Domain2Vec}, a novel approach that decomposes any dataset into a linear combination of several \emph{meta-domains}, a new concept designed to capture the key underlying features of datasets. \textsc{Domain2Vec} maintains a vocabulary of meta-domains and uses a classifier to decompose any given dataset into a domain vector that corresponds to a distribution over this vocabulary. These domain vectors enable the identification of the optimal data mixture for language model (LM) pretraining in a training-free manner under the \emph{\textbf{D}istribution \textbf{A}lignment \textbf{A}ssumption} (DA$^{2}$), which suggests that when the data distributions of the training set and the validation set are better aligned, a lower validation loss is achieved. Moreover, \textsc{Domain2vec} can be seamlessly integrated into previous works to model the relationship between domain vectors and LM performance, greatly enhancing the efficiency and scalability of previous methods. Extensive experiments demonstrate that \textsc{Domain2Vec} helps find the data mixture that enhances downstream task performance with minimal computational overhead. Specifically, \textsc{Domain2Vec} achieves the same validation loss on Pile-CC using only $51.5\%$ of the computation required when training on the original mixture of The Pile dataset. Under equivalent compute budget, \textsc{Domain2Vec} improves downstream performance by an average of $2.83\%$.
SynLogic: Synthesizing Verifiable Reasoning Data at Scale for Learning Logical Reasoning and Beyond
May 26, 2025Recent advances such as OpenAI-o1 and DeepSeek R1 have demonstrated the potential of Reinforcement Learning (RL) to enhance reasoning abilities in Large Language Models (LLMs). While open-source replication efforts have primarily focused on mathematical and coding domains, methods and resources for developing general reasoning capabilities remain underexplored. This gap is partly due to the challenge of collecting diverse and verifiable reasoning data suitable for RL. We hypothesize that logical reasoning is critical for developing general reasoning capabilities, as logic forms a fundamental building block of reasoning. In this work, we present SynLogic, a data synthesis framework and dataset that generates diverse logical reasoning data at scale, encompassing 35 diverse logical reasoning tasks. The SynLogic approach enables controlled synthesis of data with adjustable difficulty and quantity. Importantly, all examples can be verified by simple rules, making them ideally suited for RL with verifiable rewards. In our experiments, we validate the effectiveness of RL training on the SynLogic dataset based on 7B and 32B models. SynLogic leads to state-of-the-art logical reasoning performance among open-source datasets, surpassing DeepSeek-R1-Distill-Qwen-32B by 6 points on BBEH. Furthermore, mixing SynLogic data with mathematical and coding tasks improves the training efficiency of these domains and significantly enhances reasoning generalization. Notably, our mixed training model outperforms DeepSeek-R1-Zero-Qwen-32B across multiple benchmarks. These findings position SynLogic as a valuable resource for advancing the broader reasoning capabilities of LLMs. We open-source both the data synthesis pipeline and the SynLogic dataset at https://github.com/MiniMax-AI/SynLogic.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
LongSafetyBench: Long-Context LLMs Struggle with Safety Issues
Nov 11, 2024



With the development of large language models (LLMs), the sequence length of these models continues to increase, drawing significant attention to long-context language models. However, the evaluation of these models has been primarily limited to their capabilities, with a lack of research focusing on their safety. Existing work, such as ManyShotJailbreak, has to some extent demonstrated that long-context language models can exhibit safety concerns. However, the methods used are limited and lack comprehensiveness. In response, we introduce \textbf{LongSafetyBench}, the first benchmark designed to objectively and comprehensively evaluate the safety of long-context models. LongSafetyBench consists of 10 task categories, with an average length of 41,889 words. After testing eight long-context language models on LongSafetyBench, we found that existing models generally exhibit insufficient safety capabilities. The proportion of safe responses from most mainstream long-context LLMs is below 50\%. Moreover, models' safety performance in long-context scenarios does not always align with that in short-context scenarios. Further investigation revealed that long-context models tend to overlook harmful content within lengthy texts. We also proposed a simple yet effective solution, allowing open-source models to achieve performance comparable to that of top-tier closed-source models. We believe that LongSafetyBench can serve as a valuable benchmark for evaluating the safety capabilities of long-context language models. We hope that our work will encourage the broader community to pay attention to the safety of long-context models and contribute to the development of solutions to improve the safety of long-context LLMs.
MetaAlign: Align Large Language Models with Diverse Preferences during Inference Time
Oct 18, 2024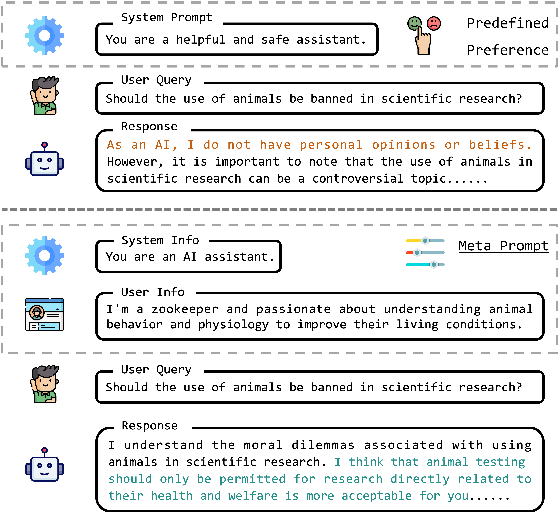



Large Language Models (LLMs) acquire extensive knowledge and remarkable abilities from extensive text corpora, making them powerful tools for various applications. To make LLMs more usable, aligning them with human preferences is essential. Existing alignment techniques, such as Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO), typically embed predefined preferences directly within the model's parameters. These methods, however, often result in a static alignment that can not account for the diversity of human preferences in practical applications. In response to this challenge, we propose an effective method, \textbf{MetaAlign}, which aims to help LLMs dynamically align with various explicit or implicit preferences specified at inference time. Experimental results show that LLMs optimized on our meticulously constructed MetaAlign Dataset can effectively align with any preferences specified at the inference stage, validating the feasibility of MetaAlign. We hope that our work can provide some insights into the alignment of language models.
Calibrating the Confidence of Large Language Models by Eliciting Fidelity
Apr 03, 2024



Large language models optimized with techniques like RLHF have achieved good alignment in being helpful and harmless. However, post-alignment, these language models often exhibit overconfidence, where the expressed confidence does not accurately calibrate with their correctness rate. In this paper, we decompose the language model confidence into the \textit{Uncertainty} about the question and the \textit{Fidelity} to the answer generated by language models. Then, we propose a plug-and-play method to estimate the confidence of language models. Our method has shown good calibration performance by conducting experiments with 6 RLHF-LMs on four MCQA datasets. Moreover, we propose two novel metrics, IPR and CE, to evaluate the calibration of the model, and we have conducted a detailed discussion on \textit{Truly Well-Calibrated Confidence}. Our method could serve as a strong baseline, and we hope that this work will provide some insights into the model confidence calibration.
Labeled Interactive Topic Models
Nov 15, 2023
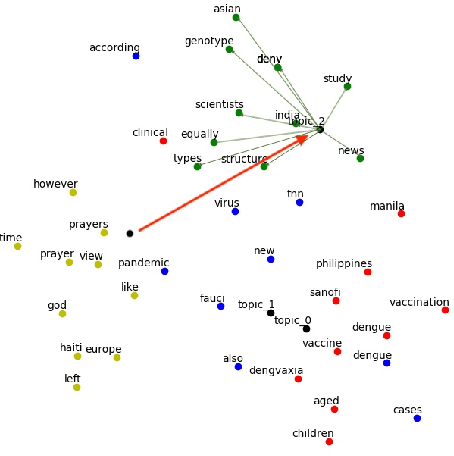
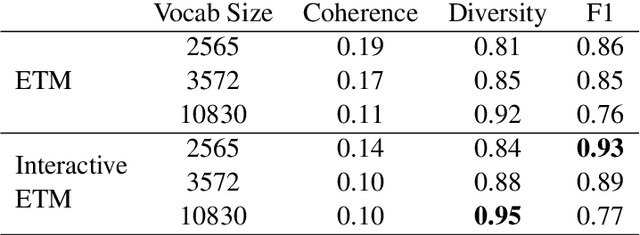
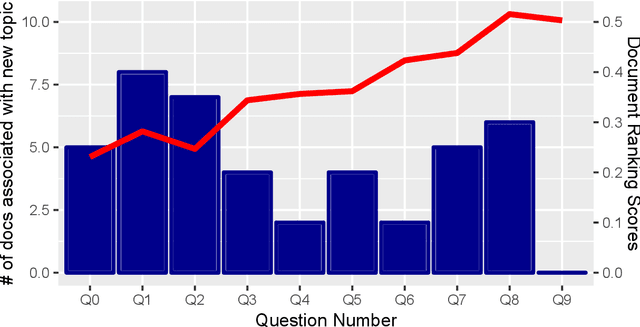
Topic models help users understand large document collections; however, topic models do not always find the ``right'' topics. While classical probabilistic and anchor-based topic models have interactive variants to guide models toward better topics, such interactions are not available for neural topic models such as the embedded topic model (\abr{etm}). We correct this lacuna by adding an intuitive interaction to neural topic models: users can label a topic with a word, and topics are updated so that the topic words are close to the label. This allows a user to refine topics based on their information need. While, interactivity is intuitive for \abr{etm}, we extend this framework to work with other neural topic models as well. We develop an interactive interface which allows users to interact and relabel topic models as they see fit. We evaluate our method through a human study, where users can relabel topics to find relevant documents. Using our method, user labeling improves document rank scores, helping to find more relevant documents to a given query when compared to no user labeling.
Evaluating Hallucinations in Chinese Large Language Models
Oct 05, 2023



In this paper, we establish a benchmark named HalluQA (Chinese Hallucination Question-Answering) to measure the hallucination phenomenon in Chinese large language models. HalluQA contains 450 meticulously designed adversarial questions, spanning multiple domains, and takes into account Chinese historical culture, customs, and social phenomena. During the construction of HalluQA, we consider two types of hallucinations: imitative falsehoods and factual errors, and we construct adversarial samples based on GLM-130B and ChatGPT. For evaluation, we design an automated evaluation method using GPT-4 to judge whether a model output is hallucinated. We conduct extensive experiments on 24 large language models, including ERNIE-Bot, Baichuan2, ChatGLM, Qwen, SparkDesk and etc. Out of the 24 models, 18 achieved non-hallucination rates lower than 50%. This indicates that HalluQA is highly challenging. We analyze the primary types of hallucinations in different types of models and their causes. Additionally, we discuss which types of hallucinations should be prioritized for different types of models.
PromptNER: A Prompting Method for Few-shot Named Entity Recognition via k Nearest Neighbor Search
May 20, 2023


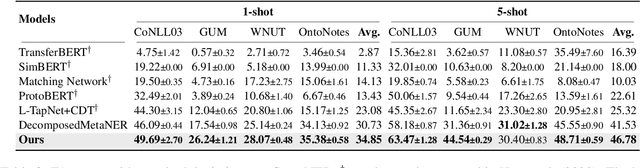
Few-shot Named Entity Recognition (NER) is a task aiming to identify named entities via limited annotated samples. Recently, prototypical networks have shown promising performance in few-shot NER. Most of prototypical networks will utilize the entities from the support set to construct label prototypes and use the query set to compute span-level similarities and optimize these label prototype representations. However, these methods are usually unsuitable for fine-tuning in the target domain, where only the support set is available. In this paper, we propose PromptNER: a novel prompting method for few-shot NER via k nearest neighbor search. We use prompts that contains entity category information to construct label prototypes, which enables our model to fine-tune with only the support set. Our approach achieves excellent transfer learning ability, and extensive experiments on the Few-NERD and CrossNER datasets demonstrate that our model achieves superior performance over state-of-the-art methods.