 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaAlign: Align Large Language Models with Diverse Preferences during Inference Time
Paper and Code
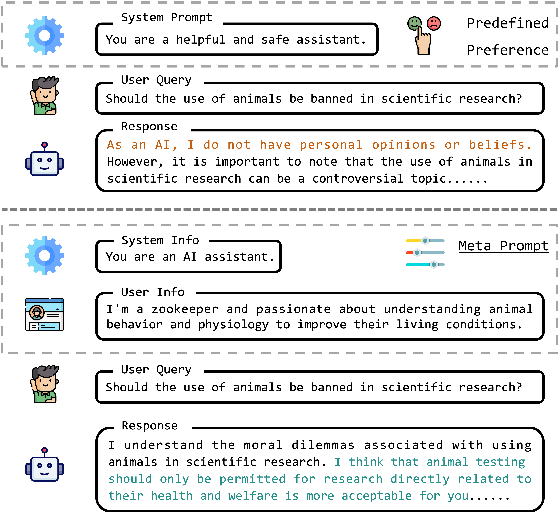



Large Language Models (LLMs) acquire extensive knowledge and remarkable abilities from extensive text corpora, making them powerful tools for various applications. To make LLMs more usable, aligning them with human preferences is essential. Existing alignment techniques, such as Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO), typically embed predefined preferences directly within the model's parameters. These methods, however, often result in a static alignment that can not account for the diversity of human preferences in practical applications. In response to this challenge, we propose an effective method, \textbf{MetaAlign}, which aims to help LLMs dynamically align with various explicit or implicit preferences specified at inference time. Experimental results show that LLMs optimized on our meticulously constructed MetaAlign Dataset can effectively align with any preferences specified at the inference stage, validating the feasibility of MetaAlign. We hope that our work can provide some insights into the alignment of language models.