 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSS-Speech: Towards True Speech-to-Speech Models Without Text Guidance
Oct 02, 2025



Spoken dialogue systems often rely on cascaded pipelines that transcribe, process, and resynthesize speech. While effective, this design discards paralinguistic cues and limits expressivity. Recent end-to-end methods reduce latency and better preserve these cues, yet still rely on text intermediates, creating a fundamental bottleneck. We present MOSS-Speech, a true speech-to-speech large language model that directly understands and generates speech without relying on text guidance. Our approach combines a modality-based layer-splitting architecture with a frozen pre-training strategy, preserving the reasoning and knowledge of pretrained text LLMs while adding native speech capabilities. Experiments show that our model achieves state-of-the-art results in spoken question answering and delivers comparable speech-to-speech performance relative to existing text-guided systems, while still maintaining competitive text performance. By narrowing the gap between text-guided and direct speech generation, our work establishes a new paradigm for expressive and efficient end-to-end speech interaction.
Decoupled Proxy Alignment: Mitigating Language Prior Conflict for Multimodal Alignment in MLLM
Sep 18, 2025Multimodal large language models (MLLMs) have gained significant attention due to their impressive ability to integrate vision and language modalities. Recent advancements in MLLMs have primarily focused on improving performance through high-quality datasets, novel architectures, and optimized training strategies. However, in this paper, we identify a previously overlooked issue, language prior conflict, a mismatch between the inherent language priors of large language models (LLMs) and the language priors in training datasets. This conflict leads to suboptimal vision-language alignment, as MLLMs are prone to adapting to the language style of training samples. To address this issue, we propose a novel training method called Decoupled Proxy Alignment (DPA). DPA introduces two key innovations: (1) the use of a proxy LLM during pretraining to decouple the vision-language alignment process from language prior interference, and (2) dynamic loss adjustment based on visual relevance to strengthen optimization signals for visually relevant tokens. Extensive experiments demonstrate that DPA significantly mitigates the language prior conflict, achieving superior alignment performance across diverse datasets, model families, and scales. Our method not only improves the effectiveness of MLLM training but also shows exceptional generalization capabilities, making it a robust approach for vision-language alignment. Our code is available at https://github.com/fnlp-vision/DPA.
Thus Spake Long-Context Large Language Model
Feb 24, 2025Long context is an important topic in Natural Language Processing (NLP), running through the development of NLP architectures, and offers immense opportunities for Large Language Models (LLMs) giving LLMs the lifelong learning potential akin to humans. Unfortunately, the pursuit of a long context is accompanied by numerous obstacles. Nevertheless, long context remains a core competitive advantage for LLMs. In the past two years, the context length of LLMs has achieved a breakthrough extension to millions of tokens. Moreover, the research on long-context LLMs has expanded from length extrapolation to a comprehensive focus on architecture, infrastructure, training, and evaluation technologies. Inspired by the symphonic poem, Thus Spake Zarathustra, we draw an analogy between the journey of extending the context of LLM and the attempts of humans to transcend its mortality. In this survey, We will illustrate how LLM struggles between the tremendous need for a longer context and its equal need to accept the fact that it is ultimately finite. To achieve this, we give a global picture of the lifecycle of long-context LLMs from four perspectives: architecture, infrastructure, training, and evaluation, showcasing the full spectrum of long-context technologies. At the end of this survey, we will present 10 unanswered questions currently faced by long-context LLMs. We hope this survey can serve as a systematic introduction to the research on long-context LLMs.
LongSafetyBench: Long-Context LLMs Struggle with Safety Issues
Nov 11, 2024



With the development of large language models (LLMs), the sequence length of these models continues to increase, drawing significant attention to long-context language models. However, the evaluation of these models has been primarily limited to their capabilities, with a lack of research focusing on their safety. Existing work, such as ManyShotJailbreak, has to some extent demonstrated that long-context language models can exhibit safety concerns. However, the methods used are limited and lack comprehensiveness. In response, we introduce \textbf{LongSafetyBench}, the first benchmark designed to objectively and comprehensively evaluate the safety of long-context models. LongSafetyBench consists of 10 task categories, with an average length of 41,889 words. After testing eight long-context language models on LongSafetyBench, we found that existing models generally exhibit insufficient safety capabilities. The proportion of safe responses from most mainstream long-context LLMs is below 50\%. Moreover, models' safety performance in long-context scenarios does not always align with that in short-context scenarios. Further investigation revealed that long-context models tend to overlook harmful content within lengthy texts. We also proposed a simple yet effective solution, allowing open-source models to achieve performance comparable to that of top-tier closed-source models. We believe that LongSafetyBench can serve as a valuable benchmark for evaluating the safety capabilities of long-context language models. We hope that our work will encourage the broader community to pay attention to the safety of long-context models and contribute to the development of solutions to improve the safety of long-context LLMs.
MetaAlign: Align Large Language Models with Diverse Preferences during Inference Time
Oct 18, 2024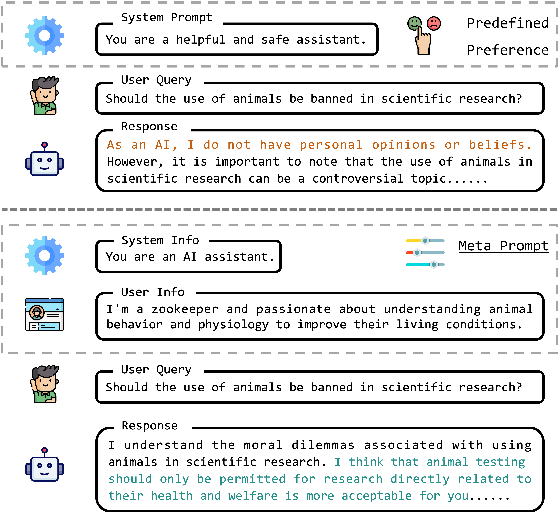



Large Language Models (LLMs) acquire extensive knowledge and remarkable abilities from extensive text corpora, making them powerful tools for various applications. To make LLMs more usable, aligning them with human preferences is essential. Existing alignment techniques, such as Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO), typically embed predefined preferences directly within the model's parameters. These methods, however, often result in a static alignment that can not account for the diversity of human preferences in practical applications. In response to this challenge, we propose an effective method, \textbf{MetaAlign}, which aims to help LLMs dynamically align with various explicit or implicit preferences specified at inference time. Experimental results show that LLMs optimized on our meticulously constructed MetaAlign Dataset can effectively align with any preferences specified at the inference stage, validating the feasibility of MetaAlign. We hope that our work can provide some insights into the alignment of language models.
IntrinsicVoice: Empowering LLMs with Intrinsic Real-time Voice Interaction Abilities
Oct 09, 2024



Current methods of building LLMs with voice interaction capabilities rely heavily on explicit text autoregressive generation before or during speech response generation to maintain content quality, which unfortunately brings computational overhead and increases latency in multi-turn interactions. To address this, we introduce IntrinsicVoic,e an LLM designed with intrinsic real-time voice interaction capabilities. IntrinsicVoice aims to facilitate the transfer of textual capabilities of pre-trained LLMs to the speech modality by mitigating the modality gap between text and speech. Our novelty architecture, GroupFormer, can reduce speech sequences to lengths comparable to text sequences while generating high-quality audio, significantly reducing the length difference between speech and text, speeding up inference, and alleviating long-text modeling issues. Additionally, we construct a multi-turn speech-to-speech dialogue dataset named \method-500k which includes nearly 500k turns of speech-to-speech dialogues, and a cross-modality training strategy to enhance the semantic alignment between speech and text. Experimental results demonstrate that IntrinsicVoice can generate high-quality speech response with latency lower than 100ms in multi-turn dialogue scenarios. Demos are available at https://instrinsicvoice.github.io/.
SpeechAlign: Aligning Speech Generation to Human Preferences
Apr 08, 2024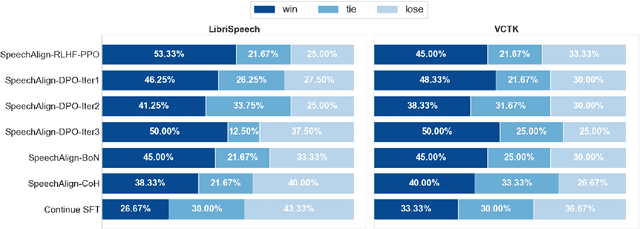
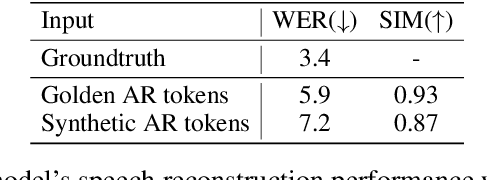
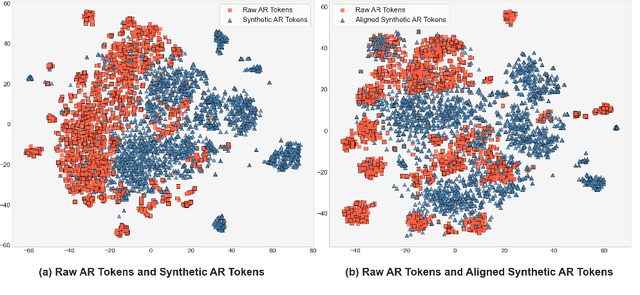

Speech language models have significantly advanced in generating realistic speech, with neural codec language models standing out. However, the integration of human feedback to align speech outputs to human preferences is often neglected. This paper addresses this gap by first analyzing the distribution gap in codec language models, highlighting how it leads to discrepancies between the training and inference phases, which negatively affects performance. Then we explore leveraging learning from human feedback to bridge the distribution gap. We introduce SpeechAlign, an iterative self-improvement strategy that aligns speech language models to human preferences. SpeechAlign involves constructing a preference codec dataset contrasting golden codec tokens against synthetic tokens, followed by preference optimization to improve the codec language model. This cycle of improvement is carried out iteratively to steadily convert weak models to strong ones. Through both subjective and objective evaluations, we show that SpeechAlign can bridge the distribution gap and facilitating continuous self-improvement of the speech language model. Moreover, SpeechAlign exhibits robust generalization capabilities and works for smaller models. Code and models will be available at https://github.com/0nutation/SpeechGPT.
Calibrating the Confidence of Large Language Models by Eliciting Fidelity
Apr 03, 2024



Large language models optimized with techniques like RLHF have achieved good alignment in being helpful and harmless. However, post-alignment, these language models often exhibit overconfidence, where the expressed confidence does not accurately calibrate with their correctness rate. In this paper, we decompose the language model confidence into the \textit{Uncertainty} about the question and the \textit{Fidelity} to the answer generated by language models. Then, we propose a plug-and-play method to estimate the confidence of language models. Our method has shown good calibration performance by conducting experiments with 6 RLHF-LMs on four MCQA datasets. Moreover, we propose two novel metrics, IPR and CE, to evaluate the calibration of the model, and we have conducted a detailed discussion on \textit{Truly Well-Calibrated Confidence}. Our method could serve as a strong baseline, and we hope that this work will provide some insights into the model confidence calibration.
SpeechGPT-Gen: Scaling Chain-of-Information Speech Generation
Jan 25, 2024



Benefiting from effective speech modeling, current Speech Large Language Models (SLLMs) have demonstrated exceptional capabilities in in-context speech generation and efficient generalization to unseen speakers. However, the prevailing information modeling process is encumbered by certain redundancies, leading to inefficiencies in speech generation. We propose Chain-of-Information Generation (CoIG), a method for decoupling semantic and perceptual information in large-scale speech generation. Building on this, we develop SpeechGPT-Gen, an 8-billion-parameter SLLM efficient in semantic and perceptual information modeling. It comprises an autoregressive model based on LLM for semantic information modeling and a non-autoregressive model employing flow matching for perceptual information modeling. Additionally, we introduce the novel approach of infusing semantic information into the prior distribution to enhance the efficiency of flow matching. Extensive experimental results demonstrate that SpeechGPT-Gen markedly excels in zero-shot text-to-speech, zero-shot voice conversion, and speech-to-speech dialogue, underscoring CoIG's remarkable proficiency in capturing and modeling speech's semantic and perceptual dimensions. Code and models are available at https://github.com/0nutation/SpeechGPT.
SpeechAgents: Human-Communication Simulation with Multi-Modal Multi-Agent Systems
Jan 08, 2024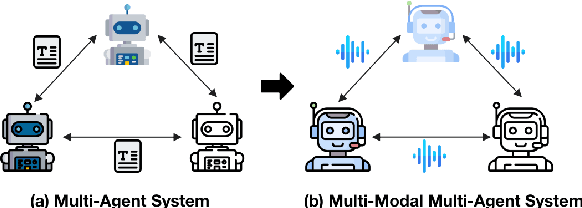
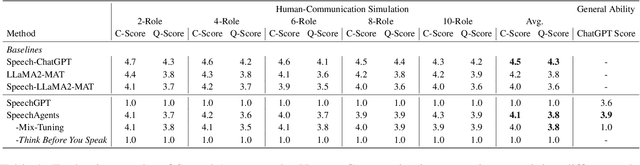
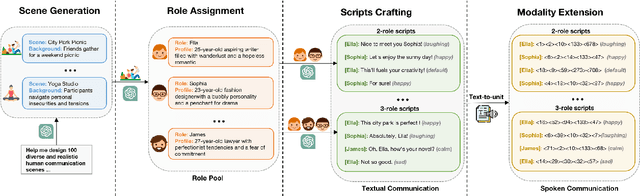
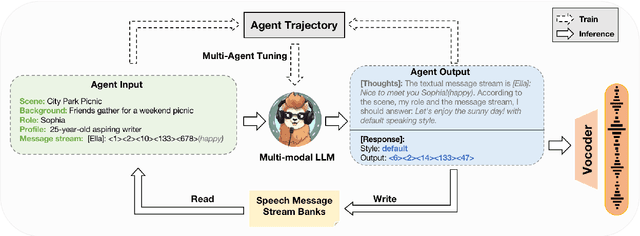
Human communication is a complex and diverse process that not only involves multiple factors such as language, commonsense, and cultural backgrounds but also requires the participation of multimodal information, such as speech. Large Language Model (LLM)-based multi-agent systems have demonstrated promising performance in simulating human society. Can we leverage LLM-based multi-agent systems to simulate human communication? However, current LLM-based multi-agent systems mainly rely on text as the primary medium. In this paper, we propose SpeechAgents, a multi-modal LLM based multi-agent system designed for simulating human communication. SpeechAgents utilizes multi-modal LLM as the control center for individual agent and employes multi-modal signals as the medium for exchanged messages among agents. Additionally, we propose Multi-Agent Tuning to enhance the multi-agent capabilities of LLM without compromising general abilities. To strengthen and evaluate the effectiveness of human communication simulation, we build the Human-Communication Simulation Benchmark. Experimental results demonstrate that SpeechAgents can simulate human communication dialogues with consistent content, authentic rhythm, and rich emotions and demonstrate excellent scalability even with up to 25 agents, which can apply to tasks such as drama creation and audio novels generation. Code and models will be open-sourced at https://github. com/0nutation/SpeechAgents