 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifiedVisual: A Framework for Constructing Unified Vision-Language Datasets
Sep 18, 2025Unified vision large language models (VLLMs) have recently achieved impressive advancements in both multimodal understanding and generation, powering applications such as visual question answering and text-guided image synthesis. However, progress in unified VLLMs remains constrained by the lack of datasets that fully exploit the synergistic potential between these two core abilities. Existing datasets typically address understanding and generation in isolation, thereby limiting the performance of unified VLLMs. To bridge this critical gap, we introduce a novel dataset construction framework, UnifiedVisual, and present UnifiedVisual-240K, a high-quality dataset meticulously designed to facilitate mutual enhancement between multimodal understanding and generation. UnifiedVisual-240K seamlessly integrates diverse visual and textual inputs and outputs, enabling comprehensive cross-modal reasoning and precise text-to-image alignment. Our dataset encompasses a wide spectrum of tasks and data sources, ensuring rich diversity and addressing key shortcomings of prior resources. Extensive experiments demonstrate that models trained on UnifiedVisual-240K consistently achieve strong performance across a wide range of tasks. Notably, these models exhibit significant mutual reinforcement between multimodal understanding and generation, further validating the effectiveness of our framework and dataset. We believe UnifiedVisual represents a new growth point for advancing unified VLLMs and unlocking their full potential. Our code and datasets is available at https://github.com/fnlp-vision/UnifiedVisual.
Decoupled Proxy Alignment: Mitigating Language Prior Conflict for Multimodal Alignment in MLLM
Sep 18, 2025Multimodal large language models (MLLMs) have gained significant attention due to their impressive ability to integrate vision and language modalities. Recent advancements in MLLMs have primarily focused on improving performance through high-quality datasets, novel architectures, and optimized training strategies. However, in this paper, we identify a previously overlooked issue, language prior conflict, a mismatch between the inherent language priors of large language models (LLMs) and the language priors in training datasets. This conflict leads to suboptimal vision-language alignment, as MLLMs are prone to adapting to the language style of training samples. To address this issue, we propose a novel training method called Decoupled Proxy Alignment (DPA). DPA introduces two key innovations: (1) the use of a proxy LLM during pretraining to decouple the vision-language alignment process from language prior interference, and (2) dynamic loss adjustment based on visual relevance to strengthen optimization signals for visually relevant tokens. Extensive experiments demonstrate that DPA significantly mitigates the language prior conflict, achieving superior alignment performance across diverse datasets, model families, and scales. Our method not only improves the effectiveness of MLLM training but also shows exceptional generalization capabilities, making it a robust approach for vision-language alignment. Our code is available at https://github.com/fnlp-vision/DPA.
LongSafetyBench: Long-Context LLMs Struggle with Safety Issues
Nov 11, 2024



With the development of large language models (LLMs), the sequence length of these models continues to increase, drawing significant attention to long-context language models. However, the evaluation of these models has been primarily limited to their capabilities, with a lack of research focusing on their safety. Existing work, such as ManyShotJailbreak, has to some extent demonstrated that long-context language models can exhibit safety concerns. However, the methods used are limited and lack comprehensiveness. In response, we introduce \textbf{LongSafetyBench}, the first benchmark designed to objectively and comprehensively evaluate the safety of long-context models. LongSafetyBench consists of 10 task categories, with an average length of 41,889 words. After testing eight long-context language models on LongSafetyBench, we found that existing models generally exhibit insufficient safety capabilities. The proportion of safe responses from most mainstream long-context LLMs is below 50\%. Moreover, models' safety performance in long-context scenarios does not always align with that in short-context scenarios. Further investigation revealed that long-context models tend to overlook harmful content within lengthy texts. We also proposed a simple yet effective solution, allowing open-source models to achieve performance comparable to that of top-tier closed-source models. We believe that LongSafetyBench can serve as a valuable benchmark for evaluating the safety capabilities of long-context language models. We hope that our work will encourage the broader community to pay attention to the safety of long-context models and contribute to the development of solutions to improve the safety of long-context LLMs.
Denoising User-aware Memory Network for Recommendation
Jul 12, 2021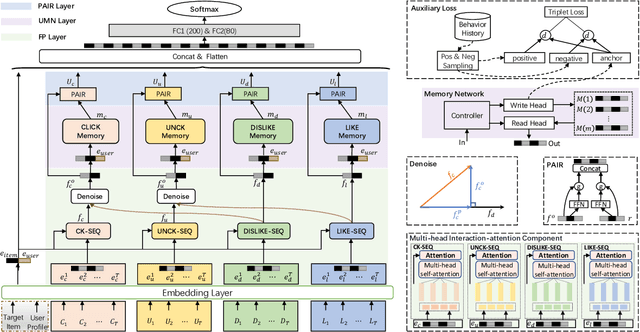
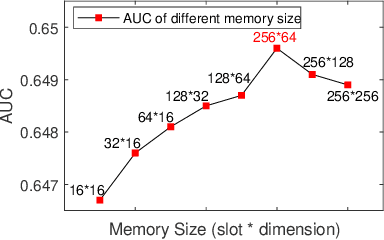
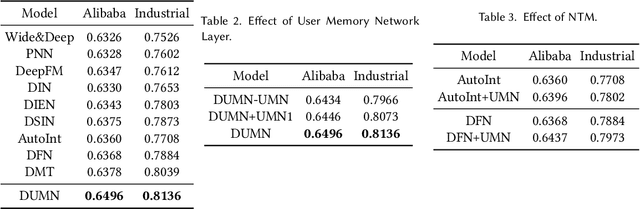

For better user satisfaction and business effectiveness, more and more attention has been paid to the sequence-based recommendation system, which is used to infer the evolution of users' dynamic preferences, and recent studies have noticed that the evolution of users' preferences can be better understood from the implicit and explicit feedback sequences. However, most of the existing recommendation techniques do not consider the noise contained in implicit feedback, which will lead to the biased representation of user interest and a suboptimal recommendation performance. Meanwhile, the existing methods utilize item sequence for capturing the evolution of user interest. The performance of these methods is limited by the length of the sequence, and can not effectively model the long-term interest in a long period of time. Based on this observation, we propose a novel CTR model named denoising user-aware memory network (DUMN). Specifically, the framework: (i) proposes a feature purification module based on orthogonal mapping, which use the representation of explicit feedback to purify the representation of implicit feedback, and effectively denoise the implicit feedback; (ii) designs a user memory network to model the long-term interests in a fine-grained way by improving the memory network, which is ignored by the existing methods; and (iii) develops a preference-aware interactive representation component to fuse the long-term and short-term interests of users based on gating to understand the evolution of unbiased preferences of users. Extensive experiments on two real e-commerce user behavior datasets show that DUMN has a significant improvement over the state-of-the-art baselines. The code of DUMN model has been uploaded as an additional material.
LRC-BERT: Latent-representation Contrastive Knowledge Distillation for Natural Language Understanding
Dec 14, 2020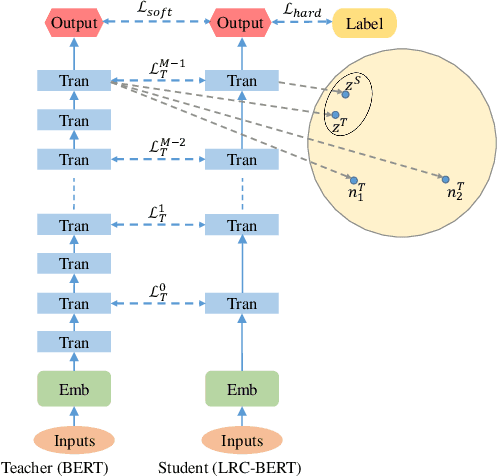

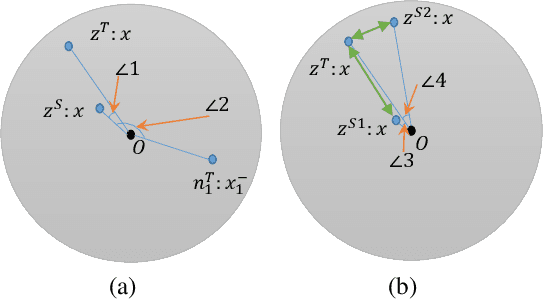

The pre-training models such as BERT have achieved great results in various natural language processing problems. However, a large number of parameters need significant amounts of memory and the consumption of inference time, which makes it difficult to deploy them on edge devices. In this work, we propose a knowledge distillation method LRC-BERT based on contrastive learning to fit the output of the intermediate layer from the angular distance aspect, which is not considered by the existing distillation methods. Furthermore, we introduce a gradient perturbation-based training architecture in the training phase to increase the robustness of LRC-BERT, which is the first attempt in knowledge distillation. Additionally, in order to better capture the distribution characteristics of the intermediate layer, we design a two-stage training method for the total distillation loss. Finally, by verifying 8 datasets on the General Language Understanding Evaluation (GLUE) benchmark, the performance of the proposed LRC-BERT exceeds the existing state-of-the-art methods, which proves the effectiveness of our method.