 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLegendre Memory Unit with A Multi-Slice Compensation Model for Short-Term Wind Speed Forecasting Based on Wind Farm Cluster Data
Feb 04, 2026With more wind farms clustered for integration, the short-term wind speed prediction of such wind farm clusters is critical for normal operation of power systems. This paper focuses on achieving accurate, fast, and robust wind speed prediction by full use of cluster data with spatial-temporal correlation. First, weighted mean filtering (WMF) is applied to denoise wind speed data at the single-farm level. The Legendre memory unit (LMU) is then innovatively applied for the wind speed prediction, in combination with the Compensating Parameter based on Kendall rank correlation coefficient (CPK) of wind farm cluster data, to construct the multi-slice LMU (MSLMU). Finally, an innovative ensemble model WMF-CPK-MSLMU is proposed herein, with three key blocks: data pre-processing, forecasting, and multi-slice compensation. Advantages include: 1) LMU jointly models linear and nonlinear dependencies among farms to capture spatial-temporal correlations through backpropagation; 2) MSLMU enhances forecasting by using CPK-derived weights instead of random initialization, allowing spatial correlations to fully activate hidden nodes across clustered wind farms.; 3) CPK adaptively weights the compensation model in MSLMU and complements missing data spatially, to facilitate the whole model highly accurate and robust. Test results on different wind farm clusters indicate the effectiveness and superiority of proposed ensemble model WMF-CPK-MSLMU in the short-term prediction of wind farm clusters compared to the existing models.
FPTN: Fast Pure Transformer Network for Traffic Flow Forecasting
Mar 14, 2023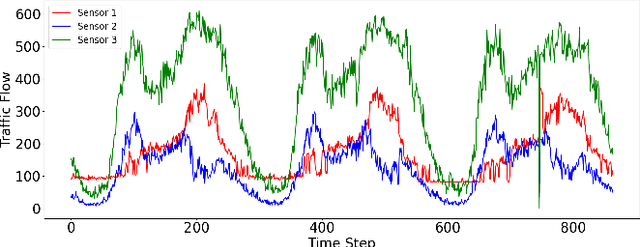
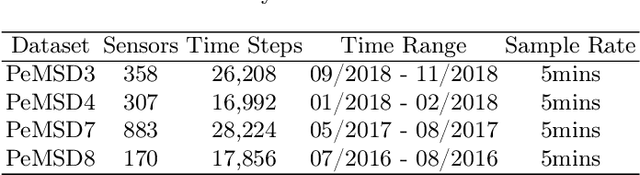
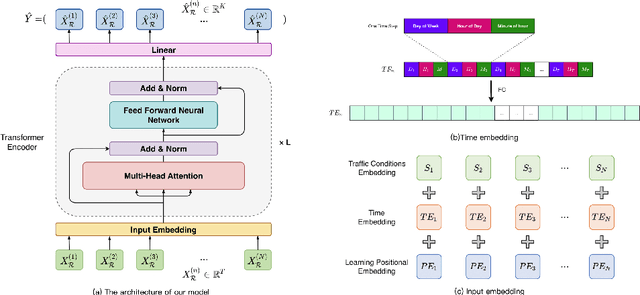
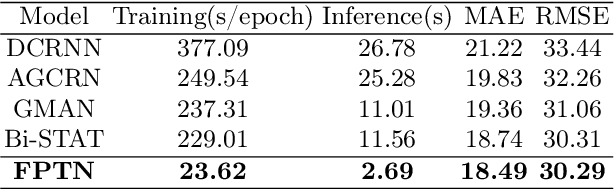
Traffic flow forecasting is challenging due to the intricate spatio-temporal correlations in traffic flow data. Existing Transformer-based methods usually treat traffic flow forecasting as multivariate time series (MTS) forecasting. However, too many sensors can cause a vector with a dimension greater than 800, which is difficult to process without information loss. In addition, these methods design complex mechanisms to capture spatial dependencies in MTS, resulting in slow forecasting speed. To solve the abovementioned problems, we propose a Fast Pure Transformer Network (FPTN) in this paper. First, the traffic flow data are divided into sequences along the sensor dimension instead of the time dimension. Then, to adequately represent complex spatio-temporal correlations, Three types of embeddings are proposed for projecting these vectors into a suitable vector space. After that, to capture the complex spatio-temporal correlations simultaneously in these vectors, we utilize Transformer encoder and stack it with several layers. Extensive experiments are conducted with 4 real-world datasets and 13 baselines, which demonstrate that FPTN outperforms the state-of-the-art on two metrics. Meanwhile, the computational time of FPTN spent is less than a quarter of other state-of-the-art Transformer-based models spent, and the requirements for computing resources are significantly reduced.
Denoising User-aware Memory Network for Recommendation
Jul 12, 2021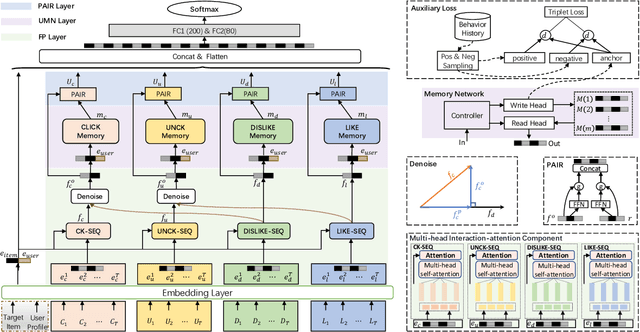
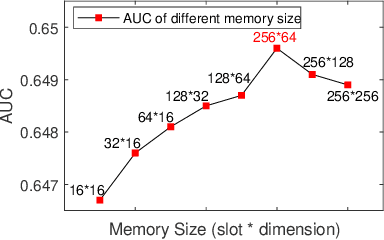
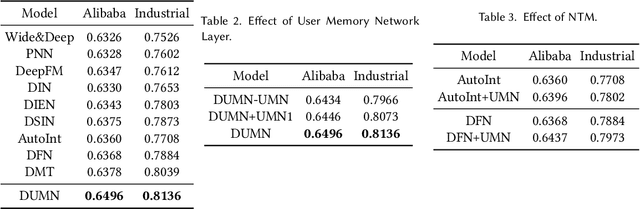

For better user satisfaction and business effectiveness, more and more attention has been paid to the sequence-based recommendation system, which is used to infer the evolution of users' dynamic preferences, and recent studies have noticed that the evolution of users' preferences can be better understood from the implicit and explicit feedback sequences. However, most of the existing recommendation techniques do not consider the noise contained in implicit feedback, which will lead to the biased representation of user interest and a suboptimal recommendation performance. Meanwhile, the existing methods utilize item sequence for capturing the evolution of user interest. The performance of these methods is limited by the length of the sequence, and can not effectively model the long-term interest in a long period of time. Based on this observation, we propose a novel CTR model named denoising user-aware memory network (DUMN). Specifically, the framework: (i) proposes a feature purification module based on orthogonal mapping, which use the representation of explicit feedback to purify the representation of implicit feedback, and effectively denoise the implicit feedback; (ii) designs a user memory network to model the long-term interests in a fine-grained way by improving the memory network, which is ignored by the existing methods; and (iii) develops a preference-aware interactive representation component to fuse the long-term and short-term interests of users based on gating to understand the evolution of unbiased preferences of users. Extensive experiments on two real e-commerce user behavior datasets show that DUMN has a significant improvement over the state-of-the-art baselines. The code of DUMN model has been uploaded as an additional material.
LRC-BERT: Latent-representation Contrastive Knowledge Distillation for Natural Language Understanding
Dec 14, 2020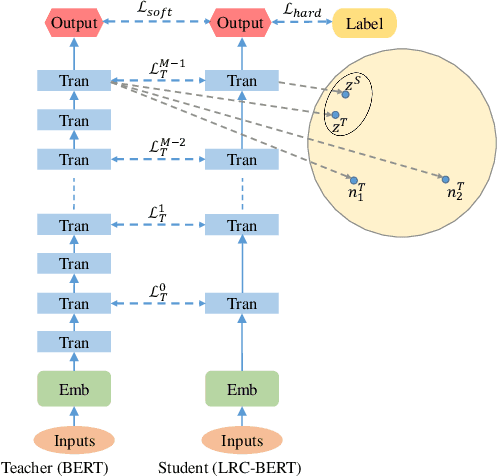


The pre-training models such as BERT have achieved great results in various natural language processing problems. However, a large number of parameters need significant amounts of memory and the consumption of inference time, which makes it difficult to deploy them on edge devices. In this work, we propose a knowledge distillation method LRC-BERT based on contrastive learning to fit the output of the intermediate layer from the angular distance aspect, which is not considered by the existing distillation methods. Furthermore, we introduce a gradient perturbation-based training architecture in the training phase to increase the robustness of LRC-BERT, which is the first attempt in knowledge distillation. Additionally, in order to better capture the distribution characteristics of the intermediate layer, we design a two-stage training method for the total distillation loss. Finally, by verifying 8 datasets on the General Language Understanding Evaluation (GLUE) benchmark, the performance of the proposed LRC-BERT exceeds the existing state-of-the-art methods, which proves the effectiveness of our method.