 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMPDE-Net and Moving Sampling Physics-informed Neural Networks Based On Moving Mesh Method
Nov 14, 2023



In this work, we propose an end-to-end adaptive sampling neural network (MMPDE-Net) based on the moving mesh PDE method, which can adaptively generate new coordinates of sampling points by solving the moving mesh PDE. This model focuses on improving the efficiency of individual sampling points. Moreover, we have developed an iterative algorithm based on MMPDE-Net, which makes the sampling points more precise and controllable. Since MMPDE-Net is a framework independent of the deep learning solver, we combine it with PINN to propose MS-PINN and demonstrate its effectiveness by performing error analysis under the assumptions given in this paper. Meanwhile, we demonstrate the performance improvement of MS-PINN compared to PINN through numerical experiments on four typical examples to verify the effectiveness of our method.
On the uncertainty analysis of the data-enabled physics-informed neural network for solving neutron diffusion eigenvalue problem
Mar 17, 2023In practical engineering experiments, the data obtained through detectors are inevitably noisy. For the already proposed data-enabled physics-informed neural network (DEPINN) \citep{DEPINN}, we investigate the performance of DEPINN in calculating the neutron diffusion eigenvalue problem from several perspectives when the prior data contain different scales of noise. Further, in order to reduce the effect of noise and improve the utilization of the noisy prior data, we propose innovative interval loss functions and give some rigorous mathematical proofs. The robustness of DEPINN is examined on two typical benchmark problems through a large number of numerical results, and the effectiveness of the proposed interval loss function is demonstrated by comparison. This paper confirms the feasibility of the improved DEPINN for practical engineering applications in nuclear reactor physics.
Neural Networks Base on Power Method and Inverse Power Method for Solving Linear Eigenvalue Problems
Sep 28, 2022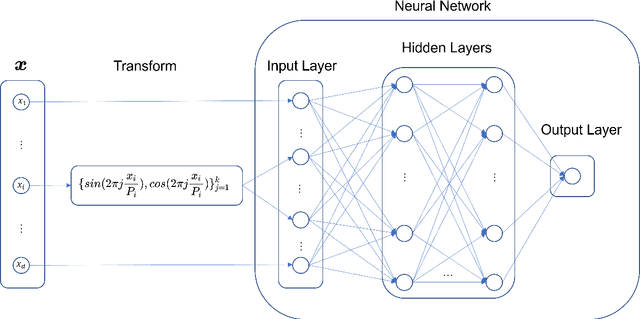
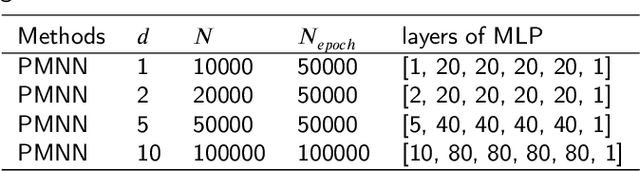
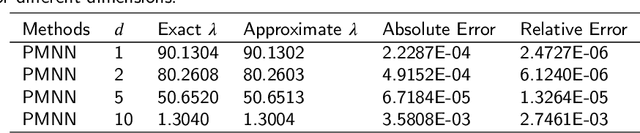
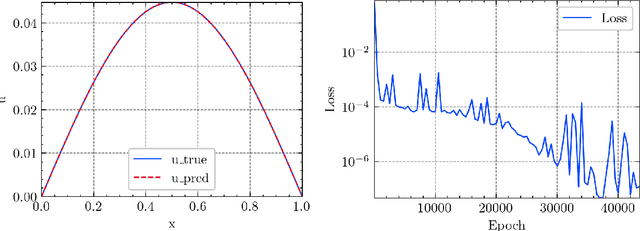
In this article, we propose three methods Power Method Neural Network (PMNN), Inverse Power Method Neural Networ (IPMNN) and Shifted Inverse Power Method Neural Network (SIPMNN) combined with power method, inverse power method and shifted inverse power method to solve eigenvalue problems with the dominant eigenvalue, the smallest eigenvalue and the smallest zero eigenvalue, respectively. The methods share similar spirits with traditional methods, but the differences are the differential operator realized by Automatic Differentiation (AD), the eigenfunction learned by the neural network and the iterations implemented by optimizing the specially defined loss function. We examine the applicability and accuracy of our methods in several numerical examples in high dimensions. Numerical results obtained by our methods for multidimensional problems show that our methods can provide accurate eigenvalue and eigenfunction approximations.
Denoising User-aware Memory Network for Recommendation
Jul 12, 2021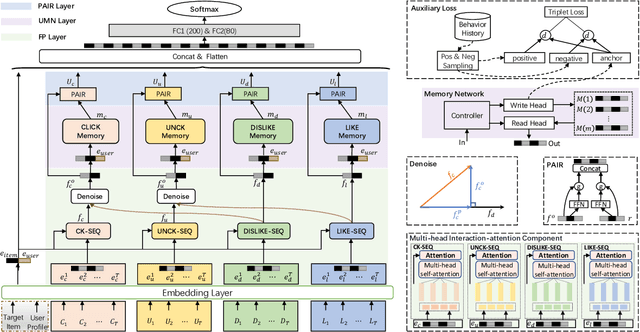
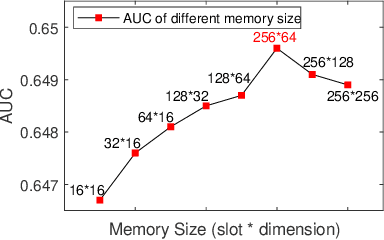
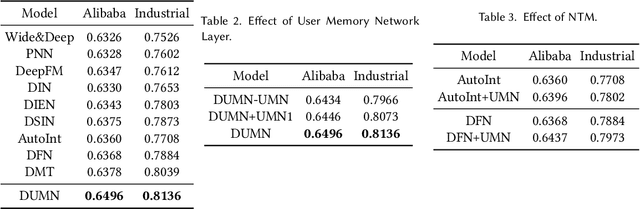

For better user satisfaction and business effectiveness, more and more attention has been paid to the sequence-based recommendation system, which is used to infer the evolution of users' dynamic preferences, and recent studies have noticed that the evolution of users' preferences can be better understood from the implicit and explicit feedback sequences. However, most of the existing recommendation techniques do not consider the noise contained in implicit feedback, which will lead to the biased representation of user interest and a suboptimal recommendation performance. Meanwhile, the existing methods utilize item sequence for capturing the evolution of user interest. The performance of these methods is limited by the length of the sequence, and can not effectively model the long-term interest in a long period of time. Based on this observation, we propose a novel CTR model named denoising user-aware memory network (DUMN). Specifically, the framework: (i) proposes a feature purification module based on orthogonal mapping, which use the representation of explicit feedback to purify the representation of implicit feedback, and effectively denoise the implicit feedback; (ii) designs a user memory network to model the long-term interests in a fine-grained way by improving the memory network, which is ignored by the existing methods; and (iii) develops a preference-aware interactive representation component to fuse the long-term and short-term interests of users based on gating to understand the evolution of unbiased preferences of users. Extensive experiments on two real e-commerce user behavior datasets show that DUMN has a significant improvement over the state-of-the-art baselines. The code of DUMN model has been uploaded as an additional material.
LRC-BERT: Latent-representation Contrastive Knowledge Distillation for Natural Language Understanding
Dec 14, 2020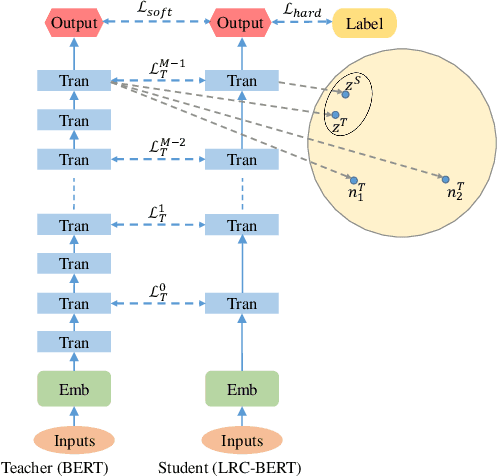

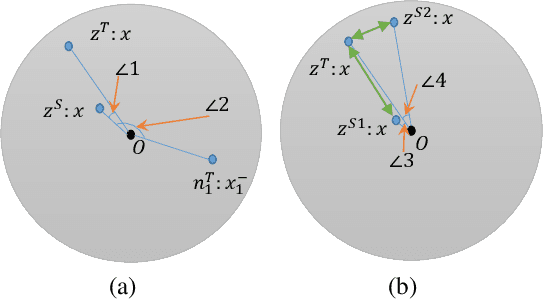

The pre-training models such as BERT have achieved great results in various natural language processing problems. However, a large number of parameters need significant amounts of memory and the consumption of inference time, which makes it difficult to deploy them on edge devices. In this work, we propose a knowledge distillation method LRC-BERT based on contrastive learning to fit the output of the intermediate layer from the angular distance aspect, which is not considered by the existing distillation methods. Furthermore, we introduce a gradient perturbation-based training architecture in the training phase to increase the robustness of LRC-BERT, which is the first attempt in knowledge distillation. Additionally, in order to better capture the distribution characteristics of the intermediate layer, we design a two-stage training method for the total distillation loss. Finally, by verifying 8 datasets on the General Language Understanding Evaluation (GLUE) benchmark, the performance of the proposed LRC-BERT exceeds the existing state-of-the-art methods, which proves the effectiveness of our method.