 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling On-Device LLMs Personalization with Smartphone Sensing
Jul 05, 2024

This demo presents a novel end-to-end framework that combines on-device large language models (LLMs) with smartphone sensing technologies to achieve context-aware and personalized services. The framework addresses critical limitations of current personalization solutions via cloud-based LLMs, such as privacy concerns, latency and cost, and limited personal sensor data. To achieve this, we innovatively proposed deploying LLMs on smartphones with multimodal sensor data and customized prompt engineering, ensuring privacy and enhancing personalization performance through context-aware sensing. A case study involving a university student demonstrated the proposed framework's capability to provide tailored recommendations. In addition, we show that the proposed framework achieves the best trade-off in privacy, performance, latency, cost, battery and energy consumption between on-device and cloud LLMs. Future work aims to integrate more diverse sensor data and conduct large-scale user studies to further refine the personalization. We envision the proposed framework could significantly improve user experiences in various domains such as healthcare, productivity, and entertainment by providing secure, context-aware, and efficient interactions directly on users' devices.
A new fuzzy multi-attribute group decision-making method based on TOPSIS and optimization models
Nov 27, 2023In this paper, a new method based on TOPSIS and optimization models is proposed for multi-attribute group decision-making in the environment of interval-valued intuitionistic fuzzy sets.Firstly, by minimizing the sum of differences between individual evaluations and the overallconsistent evaluations of all experts, a new optimization model is established for determining expert weights. Secondly, based on TOPSIS method, the improved closeness index for evaluating each alternative is obtained. Finally, the attribute weight is determined by establishing an optimization model with the goal of maximizing the closeness of each alternative, and it is brought into the closeness index so that the alternatives can be ranked. Combining all these together, the complete fuzzy multi-attribute group decision-making algorithm is formulated, which can give full play to the advantages of subjective and objective weighting methods. In the end, the feasibility and effectiveness of the provided method are verified by a real case study.
On the uncertainty analysis of the data-enabled physics-informed neural network for solving neutron diffusion eigenvalue problem
Mar 17, 2023In practical engineering experiments, the data obtained through detectors are inevitably noisy. For the already proposed data-enabled physics-informed neural network (DEPINN) \citep{DEPINN}, we investigate the performance of DEPINN in calculating the neutron diffusion eigenvalue problem from several perspectives when the prior data contain different scales of noise. Further, in order to reduce the effect of noise and improve the utilization of the noisy prior data, we propose innovative interval loss functions and give some rigorous mathematical proofs. The robustness of DEPINN is examined on two typical benchmark problems through a large number of numerical results, and the effectiveness of the proposed interval loss function is demonstrated by comparison. This paper confirms the feasibility of the improved DEPINN for practical engineering applications in nuclear reactor physics.
BEVDistill: Cross-Modal BEV Distillation for Multi-View 3D Object Detection
Nov 17, 2022
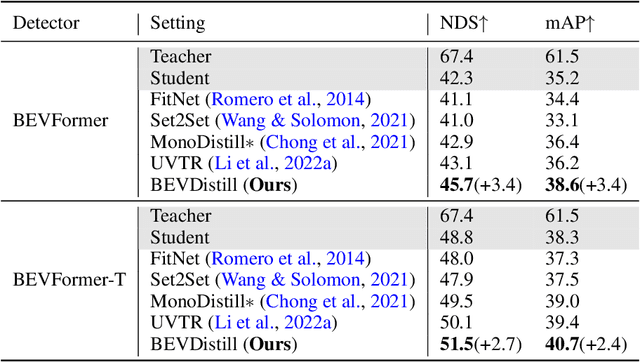


3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Owing to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views is extremely difficult due to the lack of depth information. Current approaches tend to adopt heavy backbones for image encoders, making them inapplicable for real-world deployment. Different from the images, LiDAR points are superior in providing spatial cues, resulting in highly precise localization. In this paper, we explore the incorporation of LiDAR-based detectors for multi-view 3D object detection. Instead of directly training a depth prediction network, we unify the image and LiDAR features in the Bird-Eye-View (BEV) space and adaptively transfer knowledge across non-homogenous representations in a teacher-student paradigm. To this end, we propose \textbf{BEVDistill}, a cross-modal BEV knowledge distillation (KD) framework for multi-view 3D object detection. Extensive experiments demonstrate that the proposed method outperforms current KD approaches on a highly-competitive baseline, BEVFormer, without introducing any extra cost in the inference phase. Notably, our best model achieves 59.4 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various image-based detectors. Code will be available at https://github.com/zehuichen123/BEVDistill.
Neural Networks Base on Power Method and Inverse Power Method for Solving Linear Eigenvalue Problems
Sep 28, 2022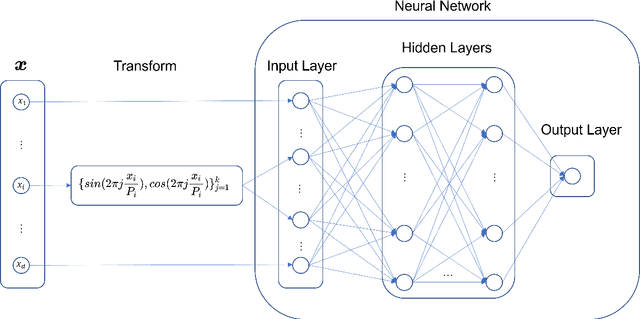
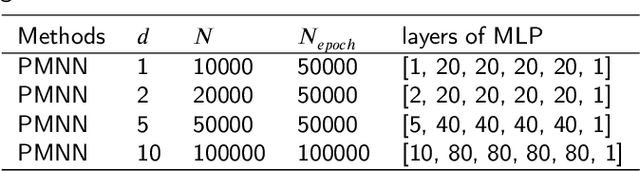
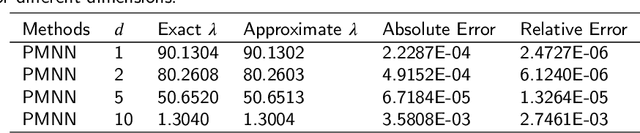
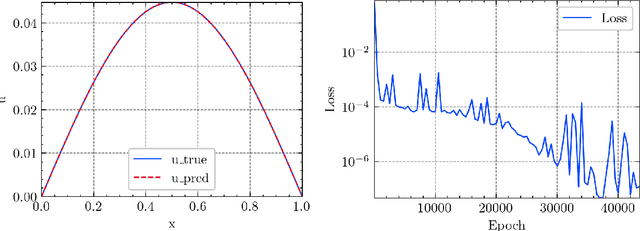
In this article, we propose three methods Power Method Neural Network (PMNN), Inverse Power Method Neural Networ (IPMNN) and Shifted Inverse Power Method Neural Network (SIPMNN) combined with power method, inverse power method and shifted inverse power method to solve eigenvalue problems with the dominant eigenvalue, the smallest eigenvalue and the smallest zero eigenvalue, respectively. The methods share similar spirits with traditional methods, but the differences are the differential operator realized by Automatic Differentiation (AD), the eigenfunction learned by the neural network and the iterations implemented by optimizing the specially defined loss function. We examine the applicability and accuracy of our methods in several numerical examples in high dimensions. Numerical results obtained by our methods for multidimensional problems show that our methods can provide accurate eigenvalue and eigenfunction approximations.
AutoAlignV2: Deformable Feature Aggregation for Dynamic Multi-Modal 3D Object Detection
Jul 21, 2022



Point clouds and RGB images are two general perceptional sources in autonomous driving. The former can provide accurate localization of objects, and the latter is denser and richer in semantic information. Recently, AutoAlign presents a learnable paradigm in combining these two modalities for 3D object detection. However, it suffers from high computational cost introduced by the global-wise attention. To solve the problem, we propose Cross-Domain DeformCAFA module in this work. It attends to sparse learnable sampling points for cross-modal relational modeling, which enhances the tolerance to calibration error and greatly speeds up the feature aggregation across different modalities. To overcome the complex GT-AUG under multi-modal settings, we design a simple yet effective cross-modal augmentation strategy on convex combination of image patches given their depth information. Moreover, by carrying out a novel image-level dropout training scheme, our model is able to infer in a dynamic manner. To this end, we propose AutoAlignV2, a faster and stronger multi-modal 3D detection framework, built on top of AutoAlign. Extensive experiments on nuScenes benchmark demonstrate the effectiveness and efficiency of AutoAlignV2. Notably, our best model reaches 72.4 NDS on nuScenes test leaderboard, achieving new state-of-the-art results among all published multi-modal 3D object detectors. Code will be available at https://github.com/zehuichen123/AutoAlignV2.
Graph-DETR3D: Rethinking Overlapping Regions for Multi-View 3D Object Detection
Apr 26, 2022
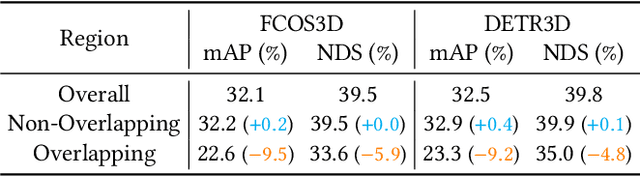


3D object detection from multiple image views is a fundamental and challenging task for visual scene understanding. Due to its low cost and high efficiency, multi-view 3D object detection has demonstrated promising application prospects. However, accurately detecting objects through perspective views in the 3D space is extremely difficult due to the lack of depth information. Recently, DETR3D introduces a novel 3D-2D query paradigm in aggregating multi-view images for 3D object detection and achieves state-of-the-art performance. In this paper, with intensive pilot experiments, we quantify the objects located at different regions and find that the "truncated instances" (i.e., at the border regions of each image) are the main bottleneck hindering the performance of DETR3D. Although it merges multiple features from two adjacent views in the overlapping regions, DETR3D still suffers from insufficient feature aggregation, thus missing the chance to fully boost the detection performance. In an effort to tackle the problem, we propose Graph-DETR3D to automatically aggregate multi-view imagery information through graph structure learning (GSL). It constructs a dynamic 3D graph between each object query and 2D feature maps to enhance the object representations, especially at the border regions. Besides, Graph-DETR3D benefits from a novel depth-invariant multi-scale training strategy, which maintains the visual depth consistency by simultaneously scaling the image size and the object depth. Extensive experiments on the nuScenes dataset demonstrate the effectiveness and efficiency of our Graph-DETR3D. Notably, our best model achieves 49.5 NDS on the nuScenes test leaderboard, achieving new state-of-the-art in comparison with various published image-view 3D object detectors.
AutoAlign: Pixel-Instance Feature Aggregation for Multi-Modal 3D Object Detection
Jan 17, 2022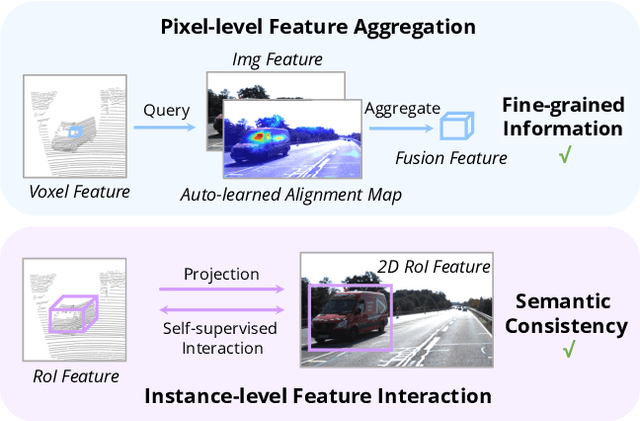
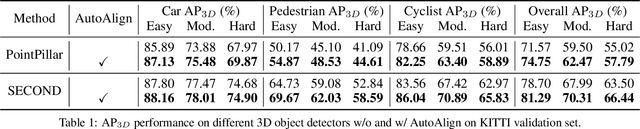
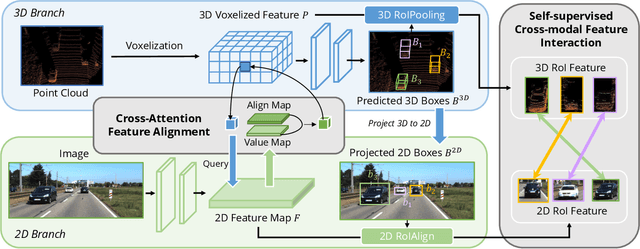

Object detection through either RGB images or the LiDAR point clouds has been extensively explored in autonomous driving. However, it remains challenging to make these two data sources complementary and beneficial to each other. In this paper, we propose \textit{AutoAlign}, an automatic feature fusion strategy for 3D object detection. Instead of establishing deterministic correspondence with camera projection matrix, we model the mapping relationship between the image and point clouds with a learnable alignment map. This map enables our model to automate the alignment of non-homogenous features in a dynamic and data-driven manner. Specifically, a cross-attention feature alignment module is devised to adaptively aggregate \textit{pixel-level} image features for each voxel. To enhance the semantic consistency during feature alignment, we also design a self-supervised cross-modal feature interaction module, through which the model can learn feature aggregation with \textit{instance-level} feature guidance. Extensive experimental results show that our approach can lead to 2.3 mAP and 7.0 mAP improvements on the KITTI and nuScenes datasets, respectively. Notably, our best model reaches 70.9 NDS on the nuScenes testing leaderboard, achieving competitive performance among various state-of-the-arts.