 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVitalAgent: A Tool-Augmented Agent for Reactive and Proactive Physiological Monitoring over Wearable Health Data
May 28, 2026Wearable devices enable continuous monitoring of physiological signals such as ECG and PPG, but existing mHealth systems are largely limited to task-specific prediction pipelines or reactive question answering over static summaries. They lack the ability to support temporal reasoning, persistent physiological context, and proactive monitoring over long-term signal streams. We propose VitalAgent, a tool-augmented agentic framework for ECG/PPG-based mHealth that supports both reactive question answering and proactive monitoring. VitalAgent is built on a longitudinal physiological memory and a tool-augmented reasoning interface that enables dynamic computation over raw signals. We further introduce VitalBench, a longitudinal physiological monitoring benchmark dataset comprising 1,862 QA pairs for reactive question answering and 90.2 hours of continuous ECG/PPG recordings for proactive monitoring, covering cardiac, physical activity, and stress-related tasks. Experiments demonstrate that VitalAgent achieves over 30% improvement over prompt-based and ReAct baselines in reactive evaluation and supports proactive alert monitoring over long-term physiological signals, highlighting the importance of dynamic tool use and long-term physiological monitoring.
Do LLMs Need to See Everything? A Benchmark and Study of Failures in LLM-driven Smartphone Automation using Screentext vs. Screenshots
Apr 20, 2026With the rapid advancement of large language models (LLMs), mobile agents have emerged as promising tools for phone automation, simulating human interactions on screens to accomplish complex tasks. However, these agents often suffer from low accuracy, misinterpretation of user instructions, and failure on challenging tasks, with limited prior work examining why and where they fail. To address this, we introduce DailyDroid, a benchmark of 75 tasks in five scenarios across 25 Android apps, spanning three difficulty levels to mimic everyday smartphone use. We evaluate it using text-only and multimodal (text + screenshot) inputs on GPT-4o and o4-mini across 300 trials, revealing comparable performance with multimodal inputs yielding marginally higher success rates. Through in-depth failure analysis, we compile a handbook of common failures. Our findings reveal critical issues in UI accessibility, input modalities, and LLM/app design, offering implications for future mobile agents, applications, and UI development.
HealthSLM-Bench: Benchmarking Small Language Models for Mobile and Wearable Healthcare Monitoring
Sep 08, 2025Mobile and wearable healthcare monitoring play a vital role in facilitating timely interventions, managing chronic health conditions, and ultimately improving individuals' quality of life. Previous studies on large language models (LLMs) have highlighted their impressive generalization abilities and effectiveness in healthcare prediction tasks. However, most LLM-based healthcare solutions are cloud-based, which raises significant privacy concerns and results in increased memory usage and latency. To address these challenges, there is growing interest in compact models, Small Language Models (SLMs), which are lightweight and designed to run locally and efficiently on mobile and wearable devices. Nevertheless, how well these models perform in healthcare prediction remains largely unexplored. We systematically evaluated SLMs on health prediction tasks using zero-shot, few-shot, and instruction fine-tuning approaches, and deployed the best performing fine-tuned SLMs on mobile devices to evaluate their real-world efficiency and predictive performance in practical healthcare scenarios. Our results show that SLMs can achieve performance comparable to LLMs while offering substantial gains in efficiency and privacy. However, challenges remain, particularly in handling class imbalance and few-shot scenarios. These findings highlight SLMs, though imperfect in their current form, as a promising solution for next-generation, privacy-preserving healthcare monitoring.
Gazing at Failure: Investigating Human Gaze in Response to Robot Failure in Collaborative Tasks
Feb 24, 2025Robots are prone to making errors, which can negatively impact their credibility as teammates during collaborative tasks with human users. Detecting and recovering from these failures is crucial for maintaining effective level of trust from users. However, robots may fail without being aware of it. One way to detect such failures could be by analysing humans' non-verbal behaviours and reactions to failures. This study investigates how human gaze dynamics can signal a robot's failure and examines how different types of failures affect people's perception of robot. We conducted a user study with 27 participants collaborating with a robotic mobile manipulator to solve tangram puzzles. The robot was programmed to experience two types of failures -- executional and decisional -- occurring either at the beginning or end of the task, with or without acknowledgement of the failure. Our findings reveal that the type and timing of the robot's failure significantly affect participants' gaze behaviour and perception of the robot. Specifically, executional failures led to more gaze shifts and increased focus on the robot, while decisional failures resulted in lower entropy in gaze transitions among areas of interest, particularly when the failure occurred at the end of the task. These results highlight that gaze can serve as a reliable indicator of robot failures and their types, and could also be used to predict the appropriate recovery actions.
Predicting Affective States from Screen Text Sentiment
Aug 23, 2024The proliferation of mobile sensing technologies has enabled the study of various physiological and behavioural phenomena through unobtrusive data collection from smartphone sensors. This approach offers real-time insights into individuals' physical and mental states, creating opportunities for personalised treatment and interventions. However, the potential of analysing the textual content viewed on smartphones to predict affective states remains underexplored. To better understand how the screen text that users are exposed to and interact with can influence their affects, we investigated a subset of data obtained from a digital phenotyping study of Australian university students conducted in 2023. We employed linear regression, zero-shot, and multi-shot prompting using a large language model (LLM) to analyse relationships between screen text and affective states. Our findings indicate that multi-shot prompting substantially outperforms both linear regression and zero-shot prompting, highlighting the importance of context in affect prediction. We discuss the value of incorporating textual and sentiment data for improving affect prediction, providing a basis for future advancements in understanding smartphone use and wellbeing.
Enabling On-Device LLMs Personalization with Smartphone Sensing
Jul 05, 2024

This demo presents a novel end-to-end framework that combines on-device large language models (LLMs) with smartphone sensing technologies to achieve context-aware and personalized services. The framework addresses critical limitations of current personalization solutions via cloud-based LLMs, such as privacy concerns, latency and cost, and limited personal sensor data. To achieve this, we innovatively proposed deploying LLMs on smartphones with multimodal sensor data and customized prompt engineering, ensuring privacy and enhancing personalization performance through context-aware sensing. A case study involving a university student demonstrated the proposed framework's capability to provide tailored recommendations. In addition, we show that the proposed framework achieves the best trade-off in privacy, performance, latency, cost, battery and energy consumption between on-device and cloud LLMs. Future work aims to integrate more diverse sensor data and conduct large-scale user studies to further refine the personalization. We envision the proposed framework could significantly improve user experiences in various domains such as healthcare, productivity, and entertainment by providing secure, context-aware, and efficient interactions directly on users' devices.
DDoD: Dual Denial of Decision Attacks on Human-AI Teams
Dec 07, 2022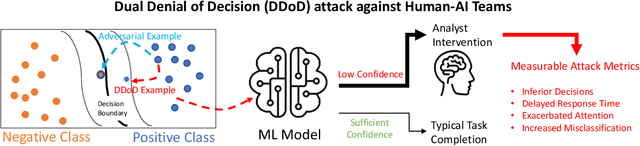
Artificial Intelligence (AI) systems have been increasingly used to make decision-making processes faster, more accurate, and more efficient. However, such systems are also at constant risk of being attacked. While the majority of attacks targeting AI-based applications aim to manipulate classifiers or training data and alter the output of an AI model, recently proposed Sponge Attacks against AI models aim to impede the classifier's execution by consuming substantial resources. In this work, we propose \textit{Dual Denial of Decision (DDoD) attacks against collaborative Human-AI teams}. We discuss how such attacks aim to deplete \textit{both computational and human} resources, and significantly impair decision-making capabilities. We describe DDoD on human and computational resources and present potential risk scenarios in a series of exemplary domains.
Smartphone App Usage Prediction Using Points of Interest
Nov 26, 2017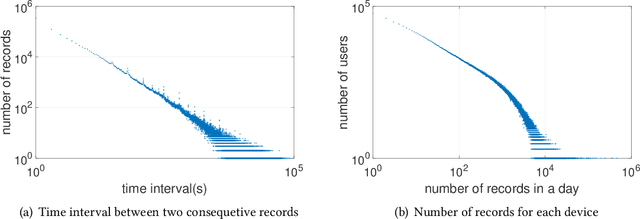
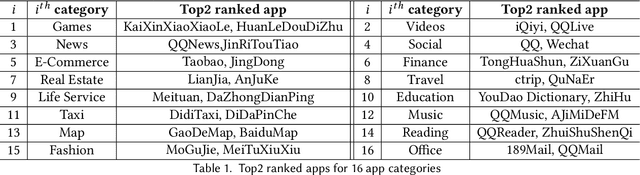
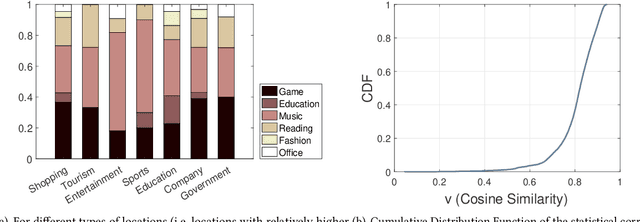

In this paper we present the first population-level, city-scale analysis of application usage on smartphones. Using deep packet inspection at the network operator level, we obtained a geo-tagged dataset with more than 6 million unique devices that launched more than 10,000 unique applications across the city of Shanghai over one week. We develop a technique that leverages transfer learning to predict which applications are most popular and estimate the whole usage distribution based on the Point of Interest (POI) information of that particular location. We demonstrate that our technique has an 83.0% hitrate in successfully identifying the top five popular applications, and a 0.15 RMSE when estimating usage with just 10% sampled sparse data. It outperforms by about 25.7% over the existing state-of-the-art approaches. Our findings pave the way for predicting which apps are relevant to a user given their current location, and which applications are popular where. The implications of our findings are broad: it enables a range of systems to benefit from such timely predictions, including operating systems, network operators, appstores, advertisers, and service providers.