 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDoD: Dual Denial of Decision Attacks on Human-AI Teams
Dec 07, 2022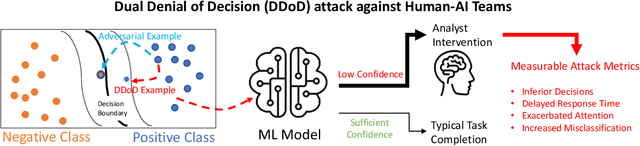
Artificial Intelligence (AI) systems have been increasingly used to make decision-making processes faster, more accurate, and more efficient. However, such systems are also at constant risk of being attacked. While the majority of attacks targeting AI-based applications aim to manipulate classifiers or training data and alter the output of an AI model, recently proposed Sponge Attacks against AI models aim to impede the classifier's execution by consuming substantial resources. In this work, we propose \textit{Dual Denial of Decision (DDoD) attacks against collaborative Human-AI teams}. We discuss how such attacks aim to deplete \textit{both computational and human} resources, and significantly impair decision-making capabilities. We describe DDoD on human and computational resources and present potential risk scenarios in a series of exemplary domains.
A Survey of Explainable Graph Neural Networks: Taxonomy and Evaluation Metrics
Jul 26, 2022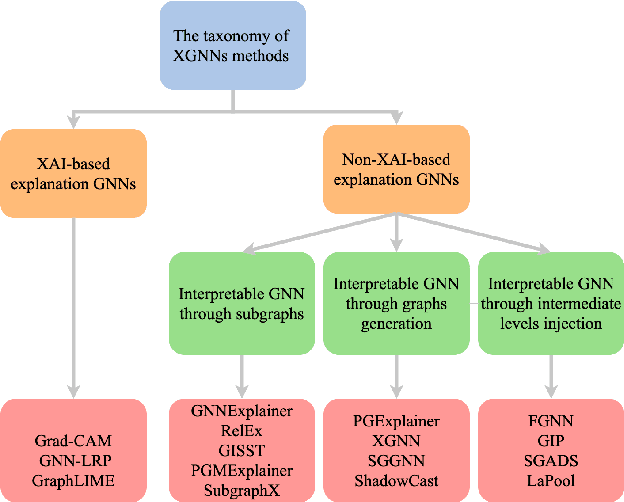

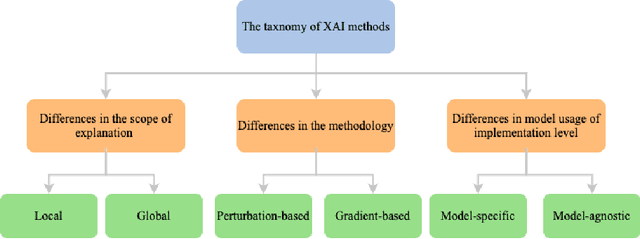
Graph neural networks (GNNs) have demonstrated a significant boost in prediction performance on graph data. At the same time, the predictions made by these models are often hard to interpret. In that regard, many efforts have been made to explain the prediction mechanisms of these models from perspectives such as GNNExplainer, XGNN and PGExplainer. Although such works present systematic frameworks to interpret GNNs, a holistic review for explainable GNNs is unavailable. In this survey, we present a comprehensive review of explainability techniques developed for GNNs. We focus on explainable graph neural networks and categorize them based on the use of explainable methods. We further provide the common performance metrics for GNNs explanations and point out several future research directions.
Imitation Learning: Progress, Taxonomies and Opportunities
Jun 23, 2021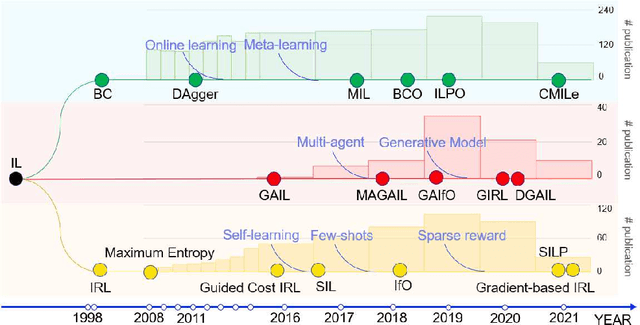
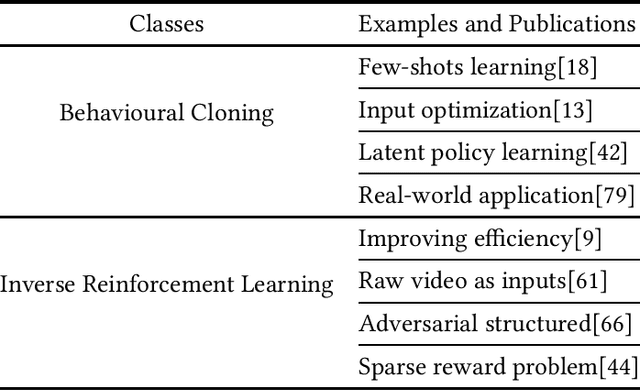
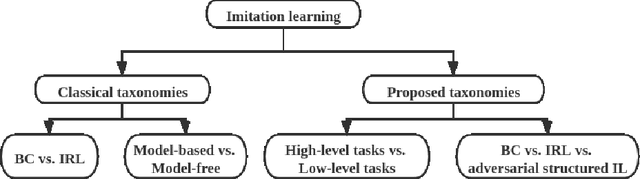

Imitation learning aims to extract knowledge from human experts' demonstrations or artificially created agents in order to replicate their behaviors. Its success has been demonstrated in areas such as video games, autonomous driving, robotic simulations and object manipulation. However, this replicating process could be problematic, such as the performance is highly dependent on the demonstration quality, and most trained agents are limited to perform well in task-specific environments. In this survey, we provide a systematic review on imitation learning. We first introduce the background knowledge from development history and preliminaries, followed by presenting different taxonomies within Imitation Learning and key milestones of the field. We then detail challenges in learning strategies and present research opportunities with learning policy from suboptimal demonstration, voice instructions and other associated optimization schemes.
Variational Co-embedding Learning for Attributed Network Clustering
Apr 15, 2021
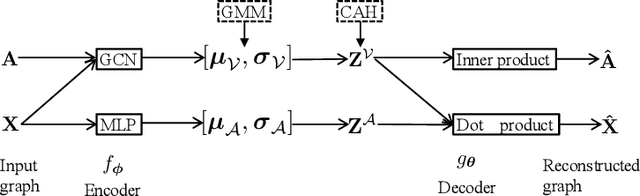
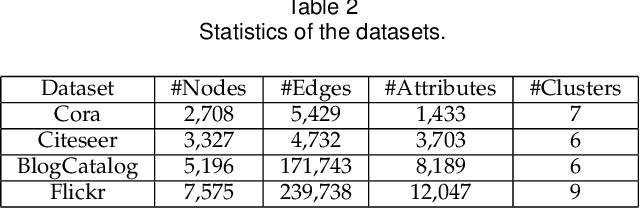
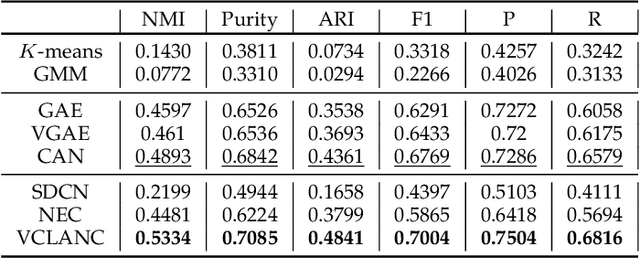
Recent works for attributed network clustering utilize graph convolution to obtain node embeddings and simultaneously perform clustering assignments on the embedding space. It is effective since graph convolution combines the structural and attributive information for node embedding learning. However, a major limitation of such works is that the graph convolution only incorporates the attribute information from the local neighborhood of nodes but fails to exploit the mutual affinities between nodes and attributes. In this regard, we propose a variational co-embedding learning model for attributed network clustering (VCLANC). VCLANC is composed of dual variational auto-encoders to simultaneously embed nodes and attributes. Relying on this, the mutual affinity information between nodes and attributes could be reconstructed from the embedding space and served as extra self-supervised knowledge for representation learning. At the same time, trainable Gaussian mixture model is used as priors to infer the node clustering assignments. To strengthen the performance of the inferred clusters, we use a mutual distance loss on the centers of the Gaussian priors and a clustering assignment hardening loss on the node embeddings. Experimental results on four real-world attributed network datasets demonstrate the effectiveness of the proposed VCLANC for attributed network clustering.
Deep-HOSeq: Deep Higher Order Sequence Fusion for Multimodal Sentiment Analysis
Oct 16, 2020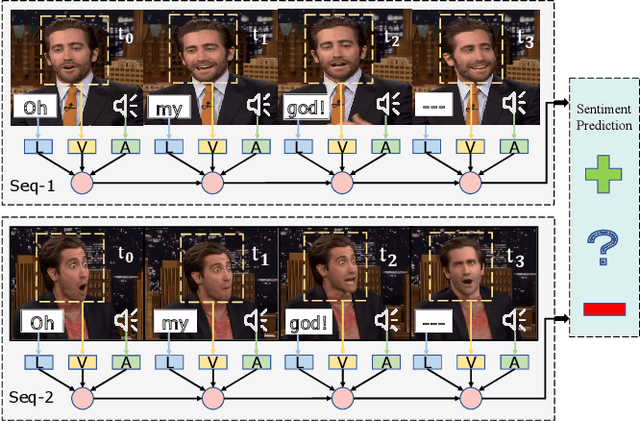
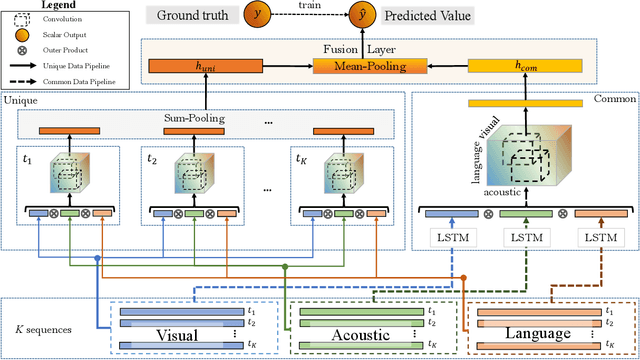
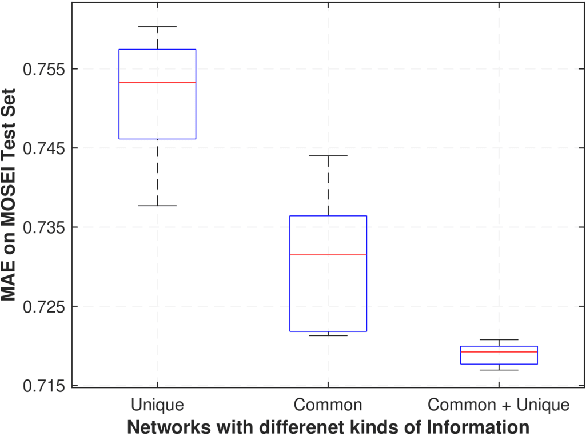
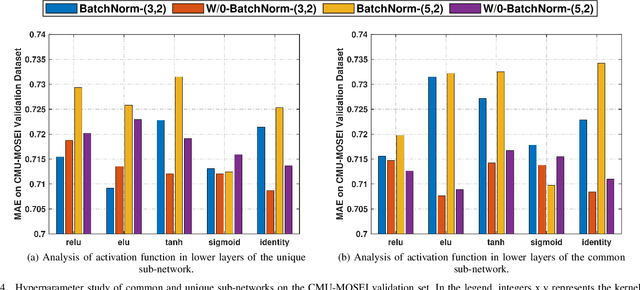
Multimodal sentiment analysis utilizes multiple heterogeneous modalities for sentiment classification. The recent multimodal fusion schemes customize LSTMs to discover intra-modal dynamics and design sophisticated attention mechanisms to discover the inter-modal dynamics from multimodal sequences. Although powerful, these schemes completely rely on attention mechanisms which is problematic due to two major drawbacks 1) deceptive attention masks, and 2) training dynamics. Nevertheless, strenuous efforts are required to optimize hyperparameters of these consolidate architectures, in particular their custom-designed LSTMs constrained by attention schemes. In this research, we first propose a common network to discover both intra-modal and inter-modal dynamics by utilizing basic LSTMs and tensor based convolution networks. We then propose unique networks to encapsulate temporal-granularity among the modalities which is essential while extracting information within asynchronous sequences. We then integrate these two kinds of information via a fusion layer and call our novel multimodal fusion scheme as Deep-HOSeq (Deep network with higher order Common and Unique Sequence information). The proposed Deep-HOSeq efficiently discovers all-important information from multimodal sequences and the effectiveness of utilizing both types of information is empirically demonstrated on CMU-MOSEI and CMU-MOSI benchmark datasets. The source code of our proposed Deep-HOSeq is and available at https://github.com/sverma88/Deep-HOSeq--ICDM-2020.
Attn-HybridNet: Improving Discriminability of Hybrid Features with Attention Fusion
Oct 14, 2020
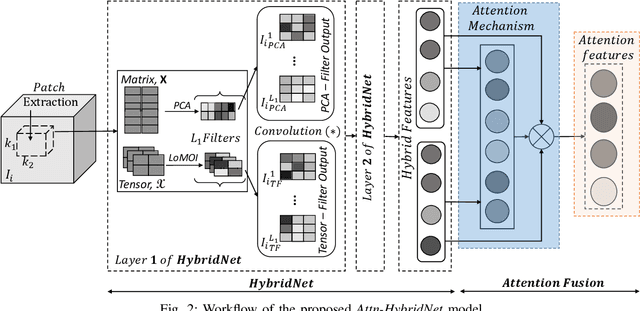
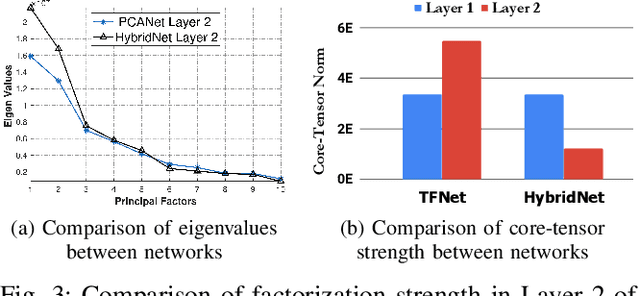

The principal component analysis network (PCANet) is an unsupervised parsimonious deep network, utilizing principal components as filters in its convolution layers. Albeit powerful, the PCANet consists of basic operations such as principal components and spatial pooling, which suffers from two fundamental problems. First, the principal components obtain information by transforming it to column vectors (which we call the amalgamated view), which incurs the loss of the spatial information in the data. Second, the generalized spatial pooling utilized in the PCANet induces feature redundancy and also fails to accommodate spatial statistics of natural images. In this research, we first propose a tensor-factorization based deep network called the Tensor Factorization Network (TFNet). The TFNet extracts features from the spatial structure of the data (which we call the minutiae view). We then show that the information obtained by the PCANet and the TFNet are distinctive and non-trivial but individually insufficient. This phenomenon necessitates the development of proposed HybridNet, which integrates the information discovery with the two views of the data. To enhance the discriminability of hybrid features, we propose Attn-HybridNet, which alleviates the feature redundancy by performing attention-based feature fusion. The significance of our proposed Attn-HybridNet is demonstrated on multiple real-world datasets where the features obtained with Attn-HybridNet achieves better classification performance over other popular baseline methods, demonstrating the effectiveness of the proposed technique.