 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep-HOSeq: Deep Higher Order Sequence Fusion for Multimodal Sentiment Analysis
Paper and Code
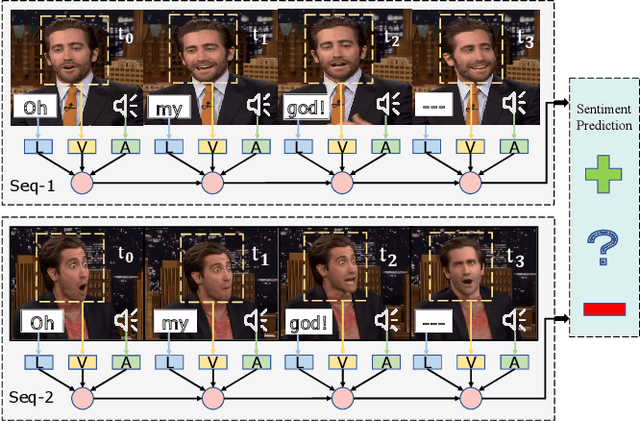
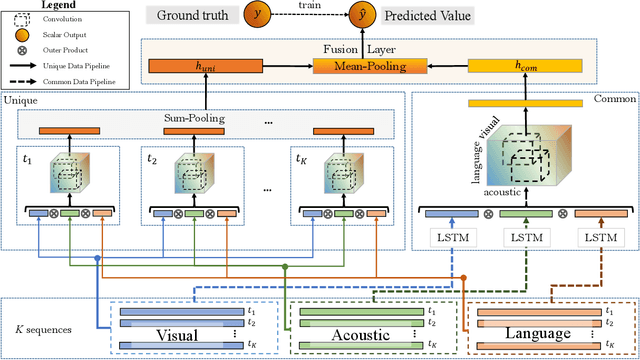
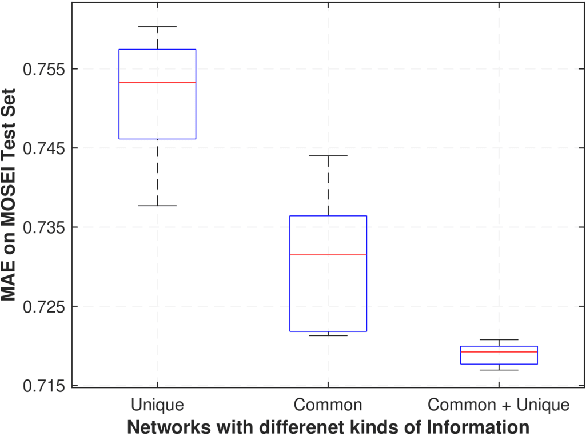
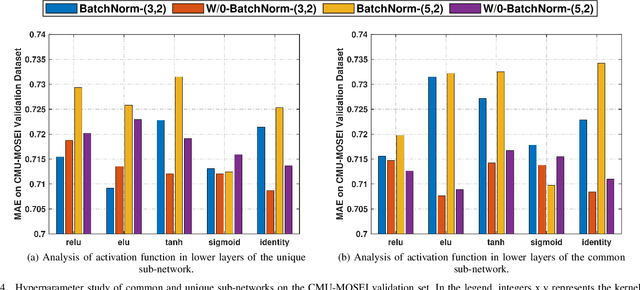
Multimodal sentiment analysis utilizes multiple heterogeneous modalities for sentiment classification. The recent multimodal fusion schemes customize LSTMs to discover intra-modal dynamics and design sophisticated attention mechanisms to discover the inter-modal dynamics from multimodal sequences. Although powerful, these schemes completely rely on attention mechanisms which is problematic due to two major drawbacks 1) deceptive attention masks, and 2) training dynamics. Nevertheless, strenuous efforts are required to optimize hyperparameters of these consolidate architectures, in particular their custom-designed LSTMs constrained by attention schemes. In this research, we first propose a common network to discover both intra-modal and inter-modal dynamics by utilizing basic LSTMs and tensor based convolution networks. We then propose unique networks to encapsulate temporal-granularity among the modalities which is essential while extracting information within asynchronous sequences. We then integrate these two kinds of information via a fusion layer and call our novel multimodal fusion scheme as Deep-HOSeq (Deep network with higher order Common and Unique Sequence information). The proposed Deep-HOSeq efficiently discovers all-important information from multimodal sequences and the effectiveness of utilizing both types of information is empirically demonstrated on CMU-MOSEI and CMU-MOSI benchmark datasets. The source code of our proposed Deep-HOSeq is and available at https://github.com/sverma88/Deep-HOSeq--ICDM-2020.