 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCocoaBench: Evaluating Unified Digital Agents in the Wild
Apr 14, 2026LLM agents now perform strongly in software engineering, deep research, GUI automation, and various other applications, while recent agent scaffolds and models are increasingly integrating these capabilities into unified systems. Yet, most evaluations still test these capabilities in isolation, which leaves a gap for more diverse use cases that require agents to combine different capabilities. We introduce CocoaBench, a benchmark for unified digital agents built from human-designed, long-horizon tasks that require flexible composition of vision, search, and coding. Tasks are specified only by an instruction and an automatic evaluation function over the final output, enabling reliable and scalable evaluation across diverse agent infrastructures. We also present CocoaAgent, a lightweight shared scaffold for controlled comparison across model backbones. Experiments show that current agents remain far from reliable on CocoaBench, with the best evaluated system achieving only 45.1% success rate. Our analysis further points to substantial room for improvement in reasoning and planning, tool use and execution, and visual grounding.
MolmoWeb: Open Visual Web Agent and Open Data for the Open Web
Apr 09, 2026Web agents--autonomous systems that navigate and execute tasks on the web on behalf of users--have the potential to transform how people interact with the digital world. However, the most capable web agents today rely on proprietary models with undisclosed training data and recipes, limiting scientific understanding, reproducibility, and community-driven progress. We believe agents for the open web should be built in the open. To this end, we introduce (1) MolmoWebMix, a large and diverse mixture of browser task demonstrations and web-GUI perception data and (2) MolmoWeb, a family of fully open multimodal web agents. Specifically, MolmoWebMix combines over 100K synthetic task trajectories from multiple complementary generation pipelines with 30K+ human demonstrations, atomic web-skill trajectories, and GUI perception data, including referring expression grounding and screenshot question answering. MolmoWeb agents operate as instruction-conditioned visual-language action policies: given a task instruction and a webpage screenshot, they predict the next browser action, requiring no access to HTML, accessibility trees, or specialized APIs. Available in 4B and 8B size, on browser-use benchmarks like WebVoyager, Online-Mind2Web, and DeepShop, MolmoWeb agents achieve state-of-the-art results outperforming similar scale open-weight-only models such as Fara-7B, UI-Tars-1.5-7B, and Holo1-7B. MolmoWeb-8B also surpasses set-of-marks (SoM) agents built on much larger closed frontier models like GPT-4o. We further demonstrate consistent gains through test-time scaling via parallel rollouts with best-of-N selection, achieving 94.7% and 60.5% pass@4 (compared to 78.2% and 35.3% pass@1) on WebVoyager and Online-Mind2Web respectively. We will release model checkpoints, training data, code, and a unified evaluation harness to enable reproducibility and accelerate open research on web agents.
Humanoid Manipulation Interface: Humanoid Whole-Body Manipulation from Robot-Free Demonstrations
Feb 06, 2026Current approaches for humanoid whole-body manipulation, primarily relying on teleoperation or visual sim-to-real reinforcement learning, are hindered by hardware logistics and complex reward engineering. Consequently, demonstrated autonomous skills remain limited and are typically restricted to controlled environments. In this paper, we present the Humanoid Manipulation Interface (HuMI), a portable and efficient framework for learning diverse whole-body manipulation tasks across various environments. HuMI enables robot-free data collection by capturing rich whole-body motion using portable hardware. This data drives a hierarchical learning pipeline that translates human motions into dexterous and feasible humanoid skills. Extensive experiments across five whole-body tasks--including kneeling, squatting, tossing, walking, and bimanual manipulation--demonstrate that HuMI achieves a 3x increase in data collection efficiency compared to teleoperation and attains a 70% success rate in unseen environments.
Multimodal Spatial Reasoning in the Large Model Era: A Survey and Benchmarks
Oct 29, 2025Humans possess spatial reasoning abilities that enable them to understand spaces through multimodal observations, such as vision and sound. Large multimodal reasoning models extend these abilities by learning to perceive and reason, showing promising performance across diverse spatial tasks. However, systematic reviews and publicly available benchmarks for these models remain limited. In this survey, we provide a comprehensive review of multimodal spatial reasoning tasks with large models, categorizing recent progress in multimodal large language models (MLLMs) and introducing open benchmarks for evaluation. We begin by outlining general spatial reasoning, focusing on post-training techniques, explainability, and architecture. Beyond classical 2D tasks, we examine spatial relationship reasoning, scene and layout understanding, as well as visual question answering and grounding in 3D space. We also review advances in embodied AI, including vision-language navigation and action models. Additionally, we consider emerging modalities such as audio and egocentric video, which contribute to novel spatial understanding through new sensors. We believe this survey establishes a solid foundation and offers insights into the growing field of multimodal spatial reasoning. Updated information about this survey, codes and implementation of the open benchmarks can be found at https://github.com/zhengxuJosh/Awesome-Spatial-Reasoning.
4DRadar-GS: Self-Supervised Dynamic Driving Scene Reconstruction with 4D Radar
Sep 16, 20253D reconstruction and novel view synthesis are critical for validating autonomous driving systems and training advanced perception models. Recent self-supervised methods have gained significant attention due to their cost-effectiveness and enhanced generalization in scenarios where annotated bounding boxes are unavailable. However, existing approaches, which often rely on frequency-domain decoupling or optical flow, struggle to accurately reconstruct dynamic objects due to imprecise motion estimation and weak temporal consistency, resulting in incomplete or distorted representations of dynamic scene elements. To address these challenges, we propose 4DRadar-GS, a 4D Radar-augmented self-supervised 3D reconstruction framework tailored for dynamic driving scenes. Specifically, we first present a 4D Radar-assisted Gaussian initialization scheme that leverages 4D Radar's velocity and spatial information to segment dynamic objects and recover monocular depth scale, generating accurate Gaussian point representations. In addition, we propose a Velocity-guided PointTrack (VGPT) model, which is jointly trained with the reconstruction pipeline under scene flow supervision, to track fine-grained dynamic trajectories and construct temporally consistent representations. Evaluated on the OmniHD-Scenes dataset, 4DRadar-GS achieves state-of-the-art performance in dynamic driving scene 3D reconstruction.
MSDNet: Efficient 4D Radar Super-Resolution via Multi-Stage Distillation
Sep 16, 2025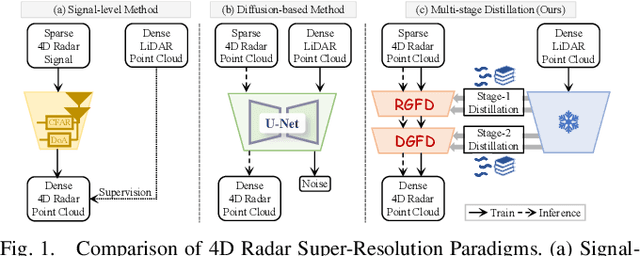
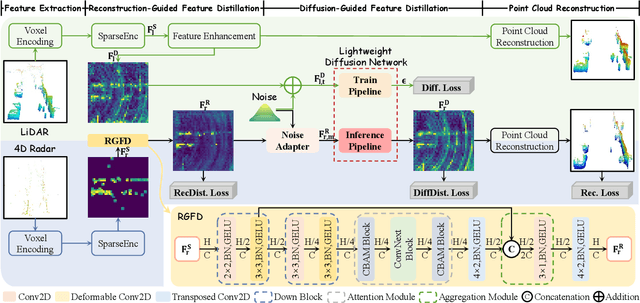
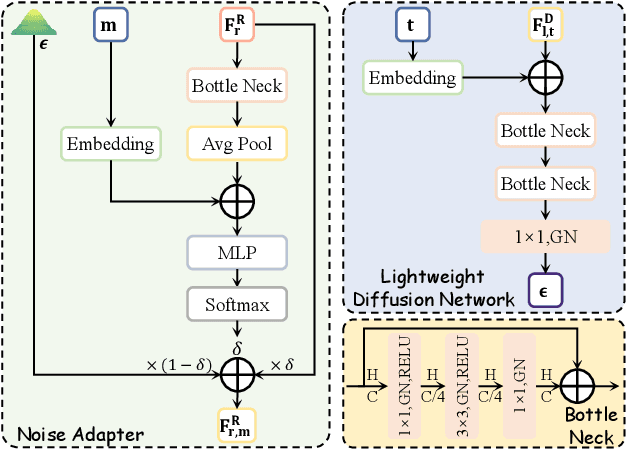
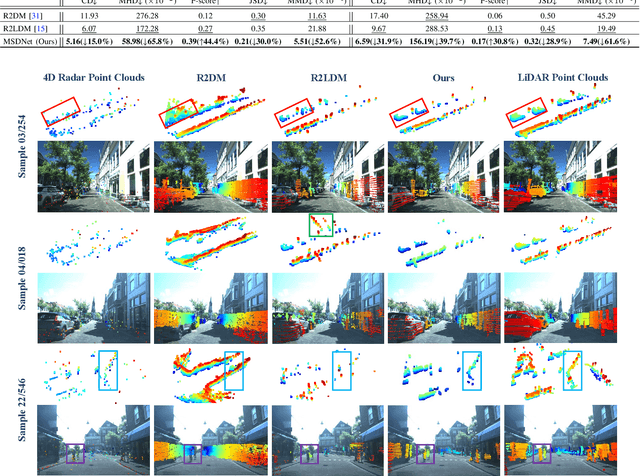
4D radar super-resolution, which aims to reconstruct sparse and noisy point clouds into dense and geometrically consistent representations, is a foundational problem in autonomous perception. However, existing methods often suffer from high training cost or rely on complex diffusion-based sampling, resulting in high inference latency and poor generalization, making it difficult to balance accuracy and efficiency. To address these limitations, we propose MSDNet, a multi-stage distillation framework that efficiently transfers dense LiDAR priors to 4D radar features to achieve both high reconstruction quality and computational efficiency. The first stage performs reconstruction-guided feature distillation, aligning and densifying the student's features through feature reconstruction. In the second stage, we propose diffusion-guided feature distillation, which treats the stage-one distilled features as a noisy version of the teacher's representations and refines them via a lightweight diffusion network. Furthermore, we introduce a noise adapter that adaptively aligns the noise level of the feature with a predefined diffusion timestep, enabling a more precise denoising. Extensive experiments on the VoD and in-house datasets demonstrate that MSDNet achieves both high-fidelity reconstruction and low-latency inference in the task of 4D radar point cloud super-resolution, and consistently improves performance on downstream tasks. The code will be publicly available upon publication.
The Ramon Llull's Thinking Machine for Automated Ideation
Aug 28, 2025This paper revisits Ramon Llull's Ars combinatoria - a medieval framework for generating knowledge through symbolic recombination - as a conceptual foundation for building a modern Llull's thinking machine for research ideation. Our approach defines three compositional axes: Theme (e.g., efficiency, adaptivity), Domain (e.g., question answering, machine translation), and Method (e.g., adversarial training, linear attention). These elements represent high-level abstractions common in scientific work - motivations, problem settings, and technical approaches - and serve as building blocks for LLM-driven exploration. We mine elements from human experts or conference papers and show that prompting LLMs with curated combinations produces research ideas that are diverse, relevant, and grounded in current literature. This modern thinking machine offers a lightweight, interpretable tool for augmenting scientific creativity and suggests a path toward collaborative ideation between humans and AI.
OpenCUA: Open Foundations for Computer-Use Agents
Aug 12, 2025Vision-language models have demonstrated impressive capabilities as computer-use agents (CUAs) capable of automating diverse computer tasks. As their commercial potential grows, critical details of the most capable CUA systems remain closed. As these agents will increasingly mediate digital interactions and execute consequential decisions on our behalf, the research community needs access to open CUA frameworks to study their capabilities, limitations, and risks. To bridge this gap, we propose OpenCUA, a comprehensive open-source framework for scaling CUA data and foundation models. Our framework consists of: (1) an annotation infrastructure that seamlessly captures human computer-use demonstrations; (2) AgentNet, the first large-scale computer-use task dataset spanning 3 operating systems and 200+ applications and websites; (3) a scalable pipeline that transforms demonstrations into state-action pairs with reflective long Chain-of-Thought reasoning that sustain robust performance gains as data scales. Our end-to-end agent models demonstrate strong performance across CUA benchmarks. In particular, OpenCUA-32B achieves an average success rate of 34.8% on OSWorld-Verified, establishing a new state-of-the-art (SOTA) among open-source models and surpassing OpenAI CUA (GPT-4o). Further analysis confirms that our approach generalizes well across domains and benefits significantly from increased test-time computation. We release our annotation tool, datasets, code, and models to build open foundations for further CUA research.
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025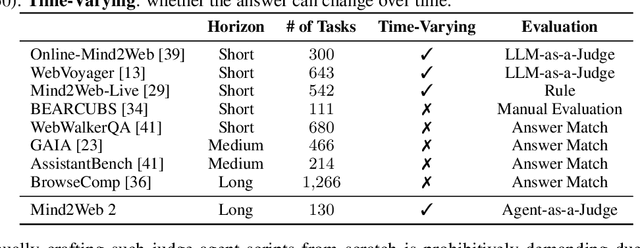
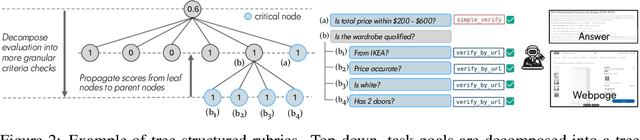

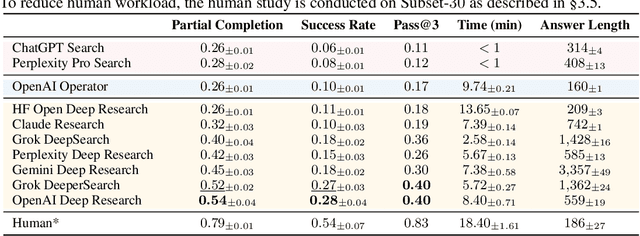
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
HuB: Learning Extreme Humanoid Balance
May 12, 2025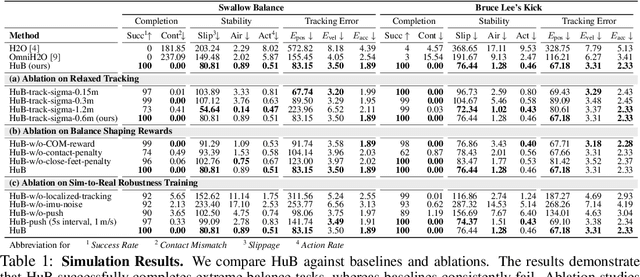
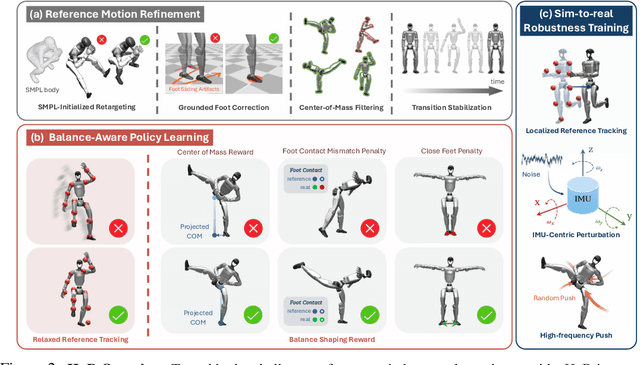
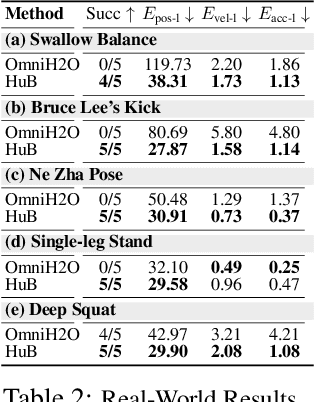
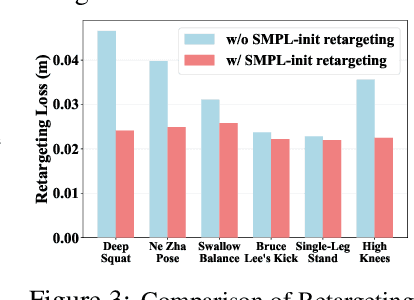
The human body demonstrates exceptional motor capabilities-such as standing steadily on one foot or performing a high kick with the leg raised over 1.5 meters-both requiring precise balance control. While recent research on humanoid control has leveraged reinforcement learning to track human motions for skill acquisition, applying this paradigm to balance-intensive tasks remains challenging. In this work, we identify three key obstacles: instability from reference motion errors, learning difficulties due to morphological mismatch, and the sim-to-real gap caused by sensor noise and unmodeled dynamics. To address these challenges, we propose HuB (Humanoid Balance), a unified framework that integrates reference motion refinement, balance-aware policy learning, and sim-to-real robustness training, with each component targeting a specific challenge. We validate our approach on the Unitree G1 humanoid robot across challenging quasi-static balance tasks, including extreme single-legged poses such as Swallow Balance and Bruce Lee's Kick. Our policy remains stable even under strong physical disturbances-such as a forceful soccer strike-while baseline methods consistently fail to complete these tasks. Project website: https://hub-robot.github.io