 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Transformer Training Through Consensus
Jan 30, 2026Standard attention-based transformers are known to exhibit instability under learning rate overspecification during training, particularly at high learning rates. While various methods have been proposed to improve resilience to such overspecification by modifying the optimization procedure, fundamental architectural innovations to this end remain underexplored. In this work, we illustrate that the consensus mechanism, a drop-in replacement for attention, stabilizes transformer training across a wider effective range of learning rates. We formulate consensus as a graphical model and provide extensive empirical analysis demonstrating improved stability across learning rate sweeps on text, DNA, and protein modalities. We further propose a hybrid consensus-attention framework that preserves performance while improving stability. We provide theoretical analysis characterizing the properties of consensus.
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
Jun 26, 2025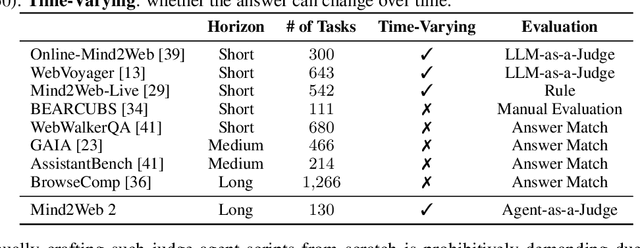
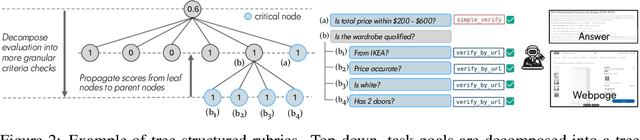

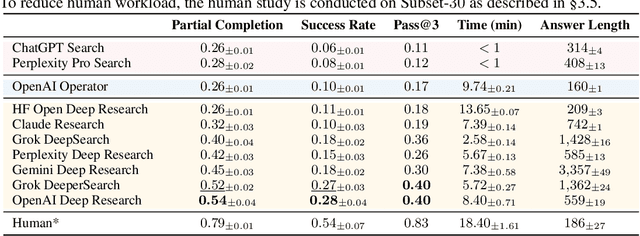
Agentic search such as Deep Research systems, where large language models autonomously browse the web, synthesize information, and return comprehensive citation-backed answers, represents a major shift in how users interact with web-scale information. While promising greater efficiency and cognitive offloading, the growing complexity and open-endedness of agentic search have outpaced existing evaluation benchmarks and methodologies, which largely assume short search horizons and static answers. In this paper, we introduce Mind2Web 2, a benchmark of 130 realistic, high-quality, and long-horizon tasks that require real-time web browsing and extensive information synthesis, constructed with over 1,000 hours of human labor. To address the challenge of evaluating time-varying and complex answers, we propose a novel Agent-as-a-Judge framework. Our method constructs task-specific judge agents based on a tree-structured rubric design to automatically assess both answer correctness and source attribution. We conduct a comprehensive evaluation of nine frontier agentic search systems and human performance, along with a detailed error analysis to draw insights for future development. The best-performing system, OpenAI Deep Research, can already achieve 50-70% of human performance while spending half the time, showing a great potential. Altogether, Mind2Web 2 provides a rigorous foundation for developing and benchmarking the next generation of agentic search systems.
FSL-SAGE: Accelerating Federated Split Learning via Smashed Activation Gradient Estimation
May 29, 2025Collaborative training methods like Federated Learning (FL) and Split Learning (SL) enable distributed machine learning without sharing raw data. However, FL assumes clients can train entire models, which is infeasible for large-scale models. In contrast, while SL alleviates the client memory constraint in FL by offloading most training to the server, it increases network latency due to its sequential nature. Other methods address the conundrum by using local loss functions for parallel client-side training to improve efficiency, but they lack server feedback and potentially suffer poor accuracy. We propose FSL-SAGE (Federated Split Learning via Smashed Activation Gradient Estimation), a new federated split learning algorithm that estimates server-side gradient feedback via auxiliary models. These auxiliary models periodically adapt to emulate server behavior on local datasets. We show that FSL-SAGE achieves a convergence rate of $\mathcal{O}(1/\sqrt{T})$, where $T$ is the number of communication rounds. This result matches FedAvg, while significantly reducing communication costs and client memory requirements. Our empirical results also verify that it outperforms existing state-of-the-art FSL methods, offering both communication efficiency and accuracy.
Tactile-Informed Action Primitives Mitigate Jamming in Dense Clutter
Feb 14, 2024



It is difficult for robots to retrieve objects in densely cluttered lateral access scenes with movable objects as jamming against adjacent objects and walls can inhibit progress. We propose the use of two action primitives -- burrowing and excavating -- that can fluidize the scene to un-jam obstacles and enable continued progress. Even when these primitives are implemented in an open loop manner at clock-driven intervals, we observe a decrease in the final distance to the target location. Furthermore, we combine the primitives into a closed loop hybrid control strategy using tactile and proprioceptive information to leverage the advantages of both primitives without being overly disruptive. In doing so, we achieve a 10-fold increase in success rate above the baseline control strategy and significantly improve completion times as compared to the primitives alone or a naive combination of them.
SuperOCR: A Conversion from Optical Character Recognition to Image Captioning
Nov 21, 2020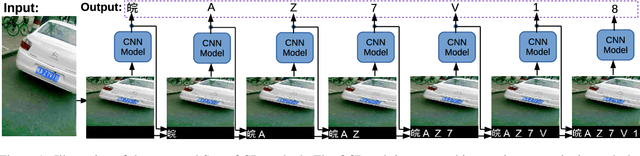
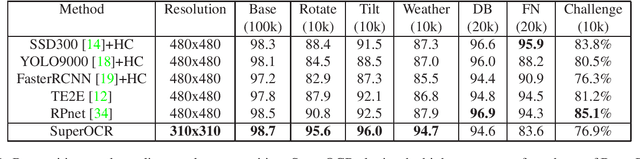
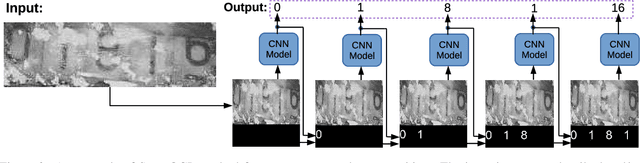
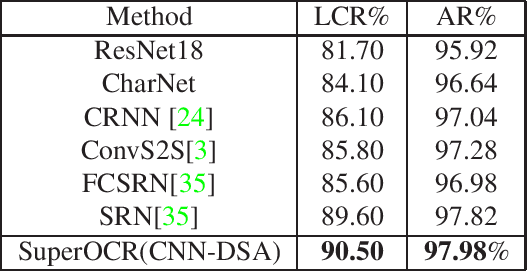
Optical Character Recognition (OCR) has many real world applications. The existing methods normally detect where the characters are, and then recognize the character for each detected location. Thus the accuracy of characters recognition is impacted by the performance of characters detection. In this paper, we propose a method for recognizing characters without detecting the location of each character. This is done by converting the OCR task into an image captioning task. One advantage of the proposed method is that the labeled bounding boxes for the characters are not needed during training. The experimental results show the proposed method outperforms the existing methods on both the license plate recognition and the watermeter character recognition tasks. The proposed method is also deployed into a low-power (300mW) CNN accelerator chip connected to a Raspberry Pi 3 for on-device applications.
Multi-modal Sentiment Analysis using Super Characters Method on Low-power CNN Accelerator Device
Jan 28, 2020
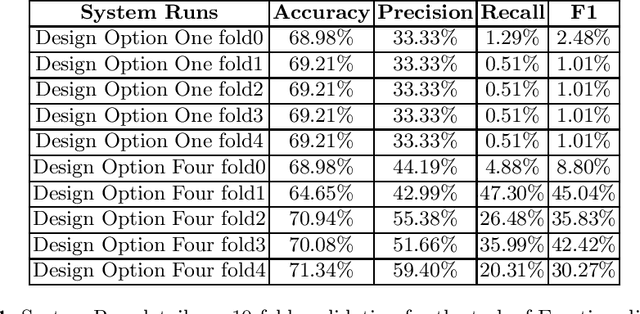

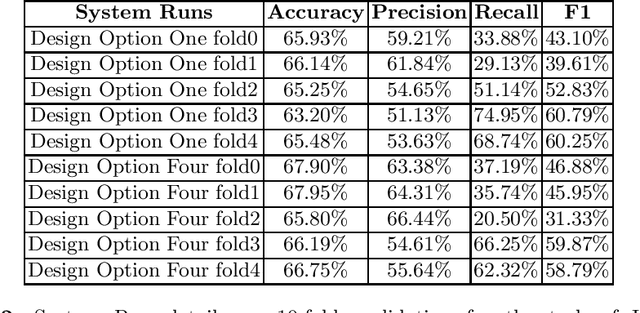
Recent years NLP research has witnessed the record-breaking accuracy improvement by DNN models. However, power consumption is one of the practical concerns for deploying NLP systems. Most of the current state-of-the-art algorithms are implemented on GPUs, which is not power-efficient and the deployment cost is also very high. On the other hand, CNN Domain Specific Accelerator (CNN-DSA) has been in mass production providing low-power and low cost computation power. In this paper, we will implement the Super Characters method on the CNN-DSA. In addition, we modify the Super Characters method to utilize the multi-modal data, i.e. text plus tabular data in the CL-Aff sharedtask.
SuperChat: Dialogue Generation by Transfer Learning from Vision to Language using Two-dimensional Word Embedding and Pretrained ImageNet CNN Models
Jun 04, 2019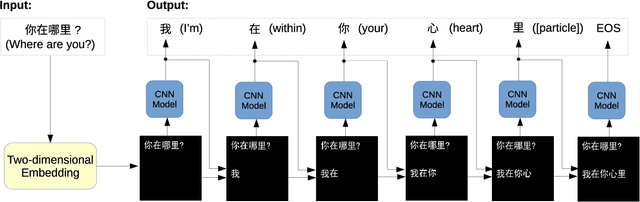
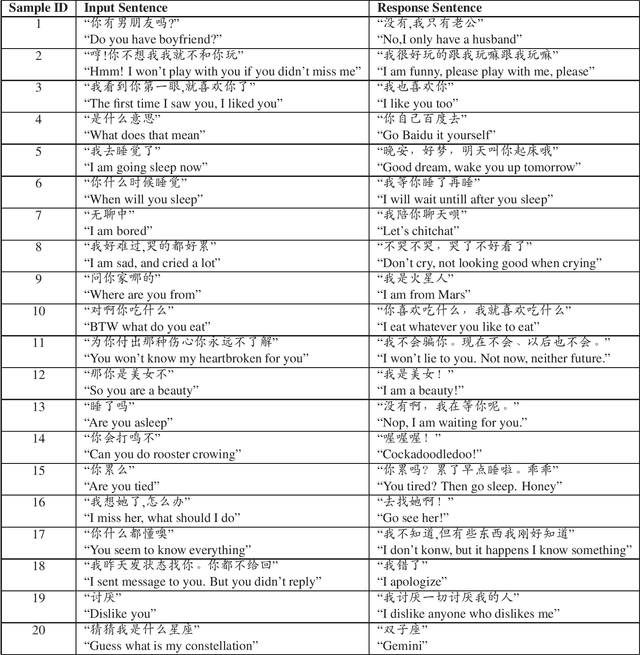
The recent work of Super Characters method using two-dimensional word embedding achieved state-of-the-art results in text classification tasks, showcasing the promise of this new approach. This paper borrows the idea of Super Characters method and two-dimensional embedding, and proposes a method of generating conversational response for open domain dialogues. The experimental results on a public dataset shows that the proposed SuperChat method generates high quality responses. An interactive demo is ready to show at the workshop.
System Demo for Transfer Learning across Vision and Text using Domain Specific CNN Accelerator for On-Device NLP Applications
Jun 04, 2019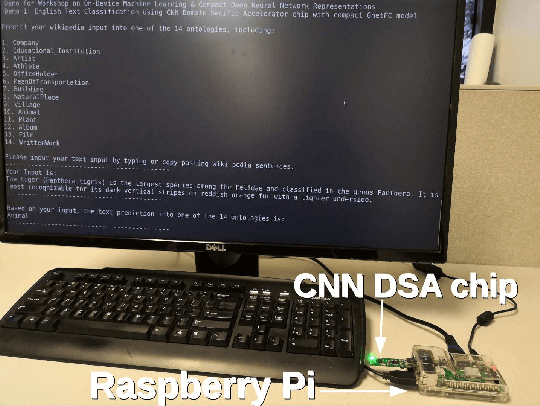

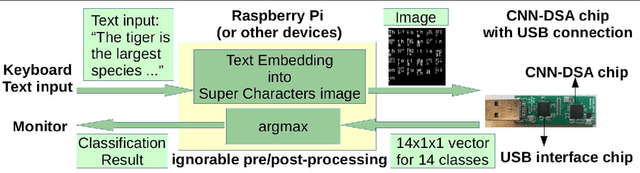
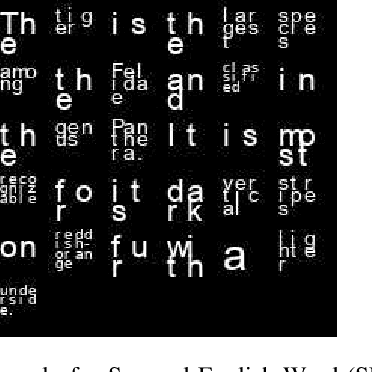
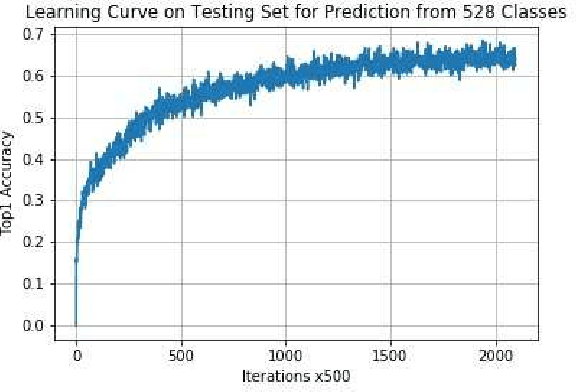
Power-efficient CNN Domain Specific Accelerator (CNN-DSA) chips are currently available for wide use in mobile devices. These chips are mainly used in computer vision applications. However, the recent work of Super Characters method for text classification and sentiment analysis tasks using two-dimensional CNN models has also achieved state-of-the-art results through the method of transfer learning from vision to text. In this paper, we implemented the text classification and sentiment analysis applications on mobile devices using CNN-DSA chips. Compact network representations using one-bit and three-bits precision for coefficients and five-bits for activations are used in the CNN-DSA chip with power consumption less than 300mW. For edge devices under memory and compute constraints, the network is further compressed by approximating the external Fully Connected (FC) layers within the CNN-DSA chip. At the workshop, we have two system demonstrations for NLP tasks. The first demo classifies the input English Wikipedia sentence into one of the 14 ontologies. The second demo classifies the Chinese online-shopping review into positive or negative.
SuperCaptioning: Image Captioning Using Two-dimensional Word Embedding
Jun 04, 2019
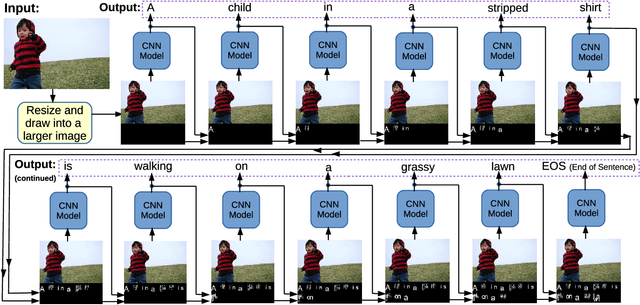
Language and vision are processed as two different modal in current work for image captioning. However, recent work on Super Characters method shows the effectiveness of two-dimensional word embedding, which converts text classification problem into image classification problem. In this paper, we propose the SuperCaptioning method, which borrows the idea of two-dimensional word embedding from Super Characters method, and processes the information of language and vision together in one single CNN model. The experimental results on Flickr30k data shows the proposed method gives high quality image captions. An interactive demo is ready to show at the workshop.
SuperTML: Two-Dimensional Word Embedding and Transfer Learning Using ImageNet Pretrained CNN Models for the Classifications on Tabular Data
Mar 22, 2019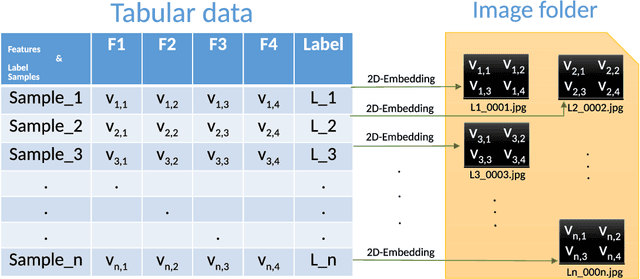


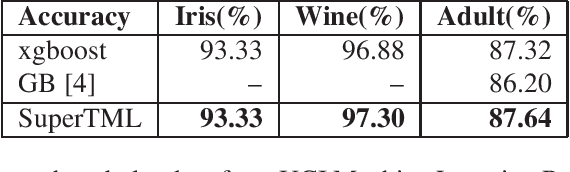
Tabular data is the most commonly used form of data in industry. Gradient Boosting Trees, Support Vector Machine, Random Forest, and Logistic Regression are typically used for classification tasks on tabular data. DNN models using categorical embeddings are also applied in this task, but all attempts thus far have used one-dimensional embeddings. The recent work of Super Characters method using two-dimensional word embeddings achieved the state of art result in text classification tasks, showcasing the promise of this new approach. In this paper, we propose the SuperTML method, which borrows the idea of Super Characters method and two-dimensional embeddings to address the problem of classification on tabular data. For each input of tabular data, the features are first projected into two-dimensional embeddings like an image, and then this image is fed into fine-tuned two-dimensional CNN models for classification. Experimental results have shown that the proposed SuperTML method had achieved state-of-the-art results on both large and small datasets.