 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Property-Driven Data Augmentation for Hyperspectral Single-Source Domain Generalization
Mar 17, 2026While hyperspectral images (HSI) benefit from numerous spectral channels that provide rich information for classification, the increased dimensionality and sensor variability make them more sensitive to distributional discrepancies across domains, which in turn can affect classification performance. To tackle this issue, hyperspectral single-source domain generalization (SDG) typically employs data augmentation to simulate potential domain shifts and enhance model robustness under the condition of single-source domain training data availability. However, blind augmentation may produce samples misaligned with real-world scenarios, while excessive emphasis on realism can suppress diversity, highlighting a tradeoff between realism and diversity that limits generalization to target domains. To address this challenge, we propose a spectral property-driven data augmentation (SPDDA) that explicitly accounts for the inherent properties of HSI, namely the device-dependent variation in the number of spectral channels and the mixing of adjacent channels. Specifically, SPDDA employs a spectral diversity module that resamples data from the source domain along the spectral dimension to generate samples with varying spectral channels, and constructs a channel-wise adaptive spectral mixer by modeling inter-channel similarity, thereby avoiding fixed augmentation patterns. To further enhance the realism of the augmented samples, we propose a spatial-spectral co-optimization mechanism, which jointly optimizes a spatial fidelity constraint and a spectral continuity self-constraint. Moreover, the weight of the spectral self-constraint is adaptively adjusted based on the spatial counterpart, thus preventing over-smoothing in the spectral dimension and preserving spatial structure. Extensive experiments conducted on three remote sensing benchmarks demonstrate that SPDDA outperforms state-of-the-art methods.
LanguageMPC: Large Language Models as Decision Makers for Autonomous Driving
Oct 13, 2023Existing learning-based autonomous driving (AD) systems face challenges in comprehending high-level information, generalizing to rare events, and providing interpretability. To address these problems, this work employs Large Language Models (LLMs) as a decision-making component for complex AD scenarios that require human commonsense understanding. We devise cognitive pathways to enable comprehensive reasoning with LLMs, and develop algorithms for translating LLM decisions into actionable driving commands. Through this approach, LLM decisions are seamlessly integrated with low-level controllers by guided parameter matrix adaptation. Extensive experiments demonstrate that our proposed method not only consistently surpasses baseline approaches in single-vehicle tasks, but also helps handle complex driving behaviors even multi-vehicle coordination, thanks to the commonsense reasoning capabilities of LLMs. This paper presents an initial step toward leveraging LLMs as effective decision-makers for intricate AD scenarios in terms of safety, efficiency, generalizability, and interoperability. We aspire for it to serve as inspiration for future research in this field. Project page: https://sites.google.com/view/llm-mpc
Lensless coherent diffraction imaging based on spatial light modulator with unknown modulation curve
Apr 08, 2022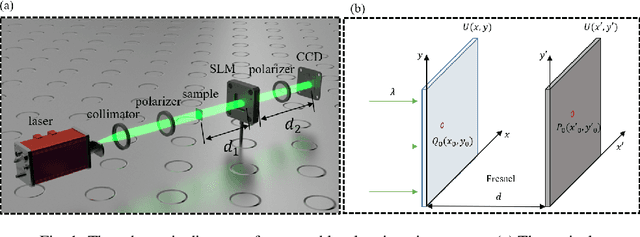
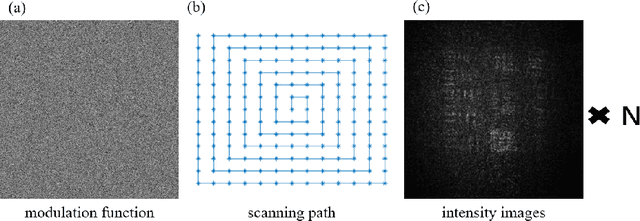

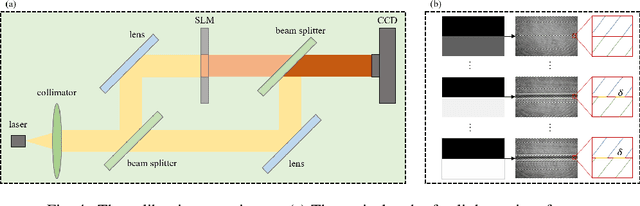
Lensless imaging is a popular research field for the advantages of small size, wide field-of-view and low aberration in recent years. However, some traditional lensless imaging methods suffer from slow convergence, mechanical errors and conjugate solution interference, which limit its further application and development. In this work, we proposed a lensless imaging method based on spatial light modulator (SLM) with unknown modulation curve. In our imaging system, we use SLM to modulate the wavefront of object, and introduce the ptychographic scanning algorithm that is able to recover the complex amplitude information even the SLM modulation curve is inaccurate or unknown. In addition, we also design a split-beam interference experiment to calibrate the modulation curve of SLM, and using the calibrated modulation function as the initial value of the expended ptychography iterative engine (ePIE) algorithm can improve the convergence speed. We further analyze the effect of modulation function, algorithm parameters and the characteristics of the coherent light source on the quality of reconstructed image. The simulated and real experiments show that the proposed method is superior to traditional mechanical scanning methods in terms of recovering speed and accuracy, with the recovering resolution up to 14 um.
GnetSeg: Semantic Segmentation Model Optimized on a 224mW CNN Accelerator Chip at the Speed of 318FPS
Jan 09, 2021

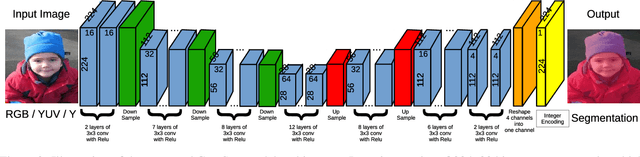
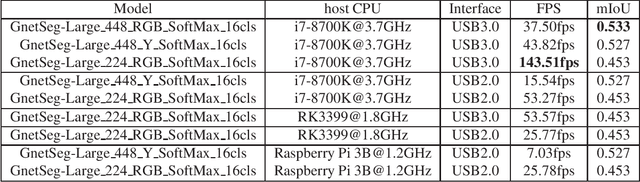
Semantic segmentation is the task to cluster pixels on an image belonging to the same class. It is widely used in the real-world applications including autonomous driving, medical imaging analysis, industrial inspection, smartphone camera for person segmentation and so on. Accelerating the semantic segmentation models on the mobile and edge devices are practical needs for the industry. Recent years have witnessed the wide availability of CNN (Convolutional Neural Networks) accelerators. They have the advantages on power efficiency, inference speed, which are ideal for accelerating the semantic segmentation models on the edge devices. However, the CNN accelerator chips also have the limitations on flexibility and memory. In addition, the CPU load is very critical because the CNN accelerator chip works as a co-processor with a host CPU. In this paper, we optimize the semantic segmentation model in order to fully utilize the limited memory and the supported operators on the CNN accelerator chips, and at the same time reduce the CPU load of the CNN model to zero. The resulting model is called GnetSeg. Furthermore, we propose the integer encoding for the mask of the GnetSeg model, which minimizes the latency of data transfer between the CNN accelerator and the host CPU. The experimental result shows that the model running on the 224mW chip achieves the speed of 318FPS with excellent accuracy for applications such as person segmentation.
SuperOCR: A Conversion from Optical Character Recognition to Image Captioning
Nov 21, 2020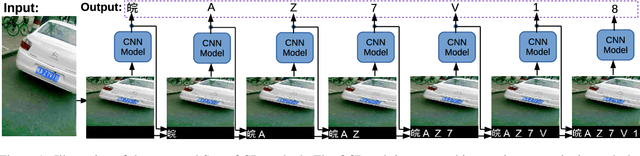
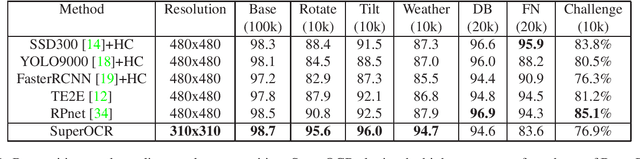
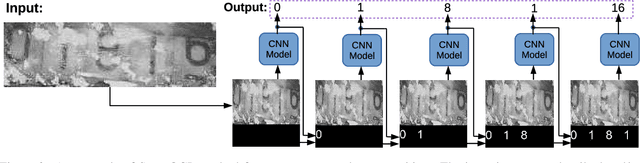
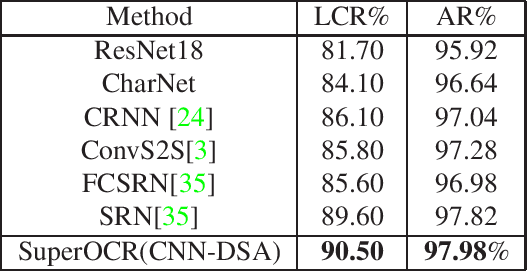
Optical Character Recognition (OCR) has many real world applications. The existing methods normally detect where the characters are, and then recognize the character for each detected location. Thus the accuracy of characters recognition is impacted by the performance of characters detection. In this paper, we propose a method for recognizing characters without detecting the location of each character. This is done by converting the OCR task into an image captioning task. One advantage of the proposed method is that the labeled bounding boxes for the characters are not needed during training. The experimental results show the proposed method outperforms the existing methods on both the license plate recognition and the watermeter character recognition tasks. The proposed method is also deployed into a low-power (300mW) CNN accelerator chip connected to a Raspberry Pi 3 for on-device applications.
Multi-modal Sentiment Analysis using Super Characters Method on Low-power CNN Accelerator Device
Jan 28, 2020
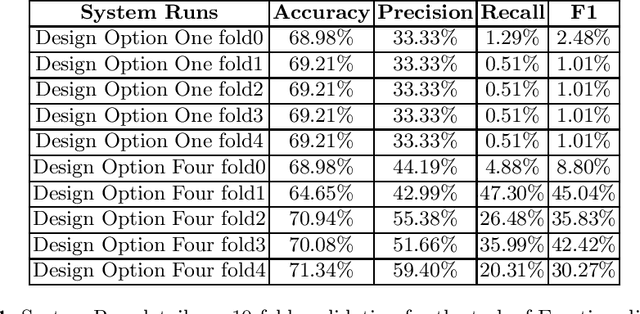

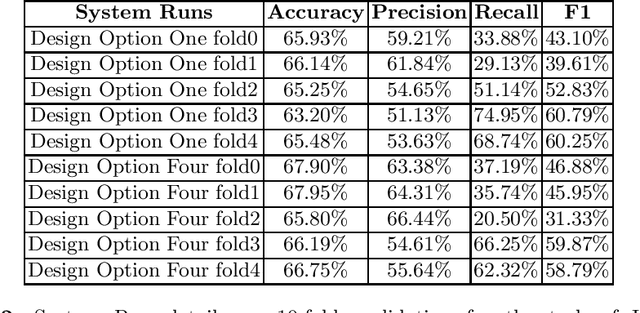
Recent years NLP research has witnessed the record-breaking accuracy improvement by DNN models. However, power consumption is one of the practical concerns for deploying NLP systems. Most of the current state-of-the-art algorithms are implemented on GPUs, which is not power-efficient and the deployment cost is also very high. On the other hand, CNN Domain Specific Accelerator (CNN-DSA) has been in mass production providing low-power and low cost computation power. In this paper, we will implement the Super Characters method on the CNN-DSA. In addition, we modify the Super Characters method to utilize the multi-modal data, i.e. text plus tabular data in the CL-Aff sharedtask.