 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGnetSeg: Semantic Segmentation Model Optimized on a 224mW CNN Accelerator Chip at the Speed of 318FPS
Jan 09, 2021

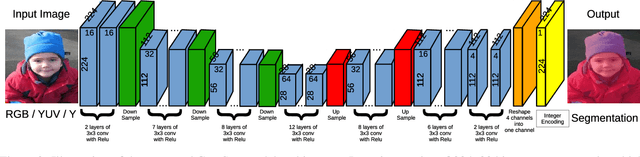
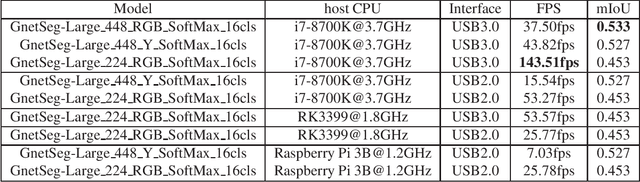
Semantic segmentation is the task to cluster pixels on an image belonging to the same class. It is widely used in the real-world applications including autonomous driving, medical imaging analysis, industrial inspection, smartphone camera for person segmentation and so on. Accelerating the semantic segmentation models on the mobile and edge devices are practical needs for the industry. Recent years have witnessed the wide availability of CNN (Convolutional Neural Networks) accelerators. They have the advantages on power efficiency, inference speed, which are ideal for accelerating the semantic segmentation models on the edge devices. However, the CNN accelerator chips also have the limitations on flexibility and memory. In addition, the CPU load is very critical because the CNN accelerator chip works as a co-processor with a host CPU. In this paper, we optimize the semantic segmentation model in order to fully utilize the limited memory and the supported operators on the CNN accelerator chips, and at the same time reduce the CPU load of the CNN model to zero. The resulting model is called GnetSeg. Furthermore, we propose the integer encoding for the mask of the GnetSeg model, which minimizes the latency of data transfer between the CNN accelerator and the host CPU. The experimental result shows that the model running on the 224mW chip achieves the speed of 318FPS with excellent accuracy for applications such as person segmentation.
SuperOCR: A Conversion from Optical Character Recognition to Image Captioning
Nov 21, 2020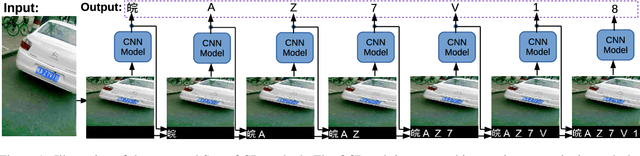
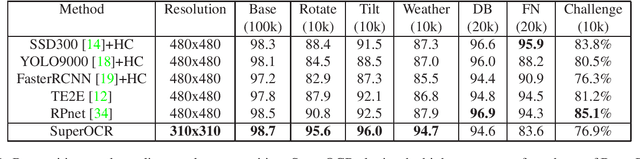
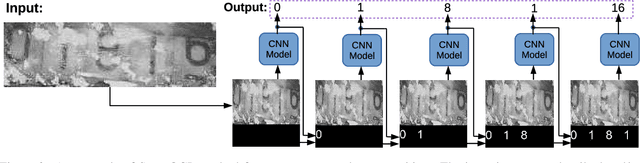
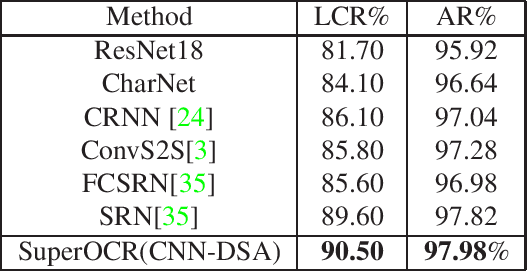
Optical Character Recognition (OCR) has many real world applications. The existing methods normally detect where the characters are, and then recognize the character for each detected location. Thus the accuracy of characters recognition is impacted by the performance of characters detection. In this paper, we propose a method for recognizing characters without detecting the location of each character. This is done by converting the OCR task into an image captioning task. One advantage of the proposed method is that the labeled bounding boxes for the characters are not needed during training. The experimental results show the proposed method outperforms the existing methods on both the license plate recognition and the watermeter character recognition tasks. The proposed method is also deployed into a low-power (300mW) CNN accelerator chip connected to a Raspberry Pi 3 for on-device applications.
Multi-modal Sentiment Analysis using Super Characters Method on Low-power CNN Accelerator Device
Jan 28, 2020
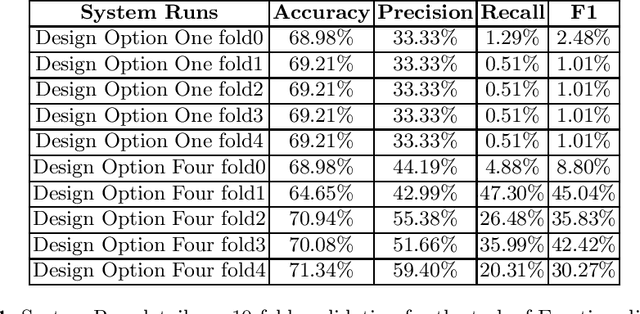

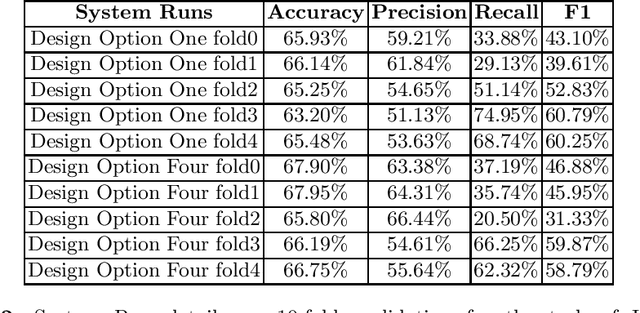
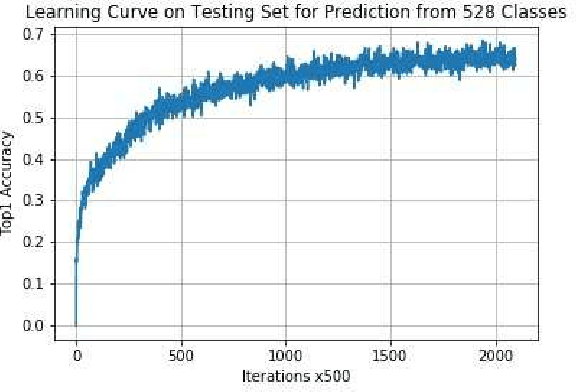
Recent years NLP research has witnessed the record-breaking accuracy improvement by DNN models. However, power consumption is one of the practical concerns for deploying NLP systems. Most of the current state-of-the-art algorithms are implemented on GPUs, which is not power-efficient and the deployment cost is also very high. On the other hand, CNN Domain Specific Accelerator (CNN-DSA) has been in mass production providing low-power and low cost computation power. In this paper, we will implement the Super Characters method on the CNN-DSA. In addition, we modify the Super Characters method to utilize the multi-modal data, i.e. text plus tabular data in the CL-Aff sharedtask.
SuperChat: Dialogue Generation by Transfer Learning from Vision to Language using Two-dimensional Word Embedding and Pretrained ImageNet CNN Models
Jun 04, 2019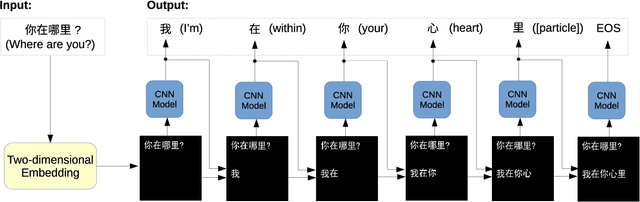
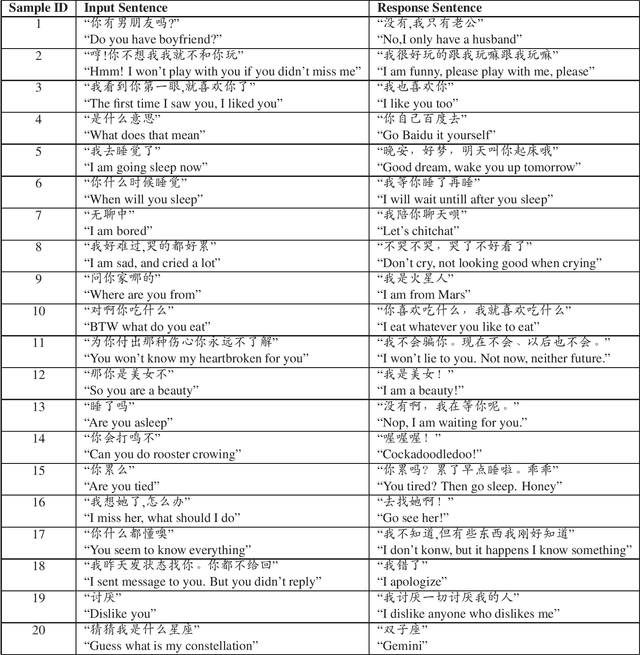
The recent work of Super Characters method using two-dimensional word embedding achieved state-of-the-art results in text classification tasks, showcasing the promise of this new approach. This paper borrows the idea of Super Characters method and two-dimensional embedding, and proposes a method of generating conversational response for open domain dialogues. The experimental results on a public dataset shows that the proposed SuperChat method generates high quality responses. An interactive demo is ready to show at the workshop.
System Demo for Transfer Learning across Vision and Text using Domain Specific CNN Accelerator for On-Device NLP Applications
Jun 04, 2019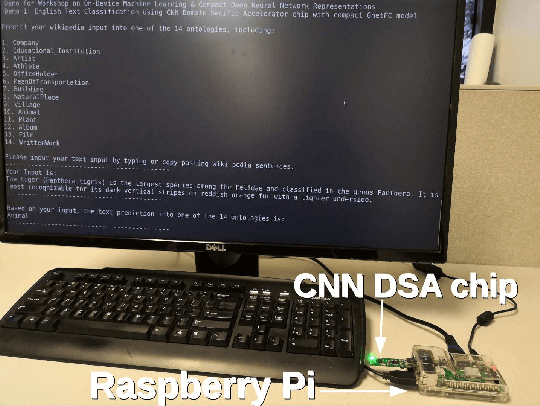

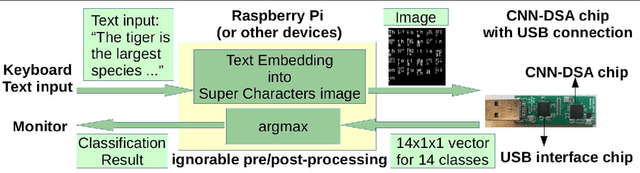
Power-efficient CNN Domain Specific Accelerator (CNN-DSA) chips are currently available for wide use in mobile devices. These chips are mainly used in computer vision applications. However, the recent work of Super Characters method for text classification and sentiment analysis tasks using two-dimensional CNN models has also achieved state-of-the-art results through the method of transfer learning from vision to text. In this paper, we implemented the text classification and sentiment analysis applications on mobile devices using CNN-DSA chips. Compact network representations using one-bit and three-bits precision for coefficients and five-bits for activations are used in the CNN-DSA chip with power consumption less than 300mW. For edge devices under memory and compute constraints, the network is further compressed by approximating the external Fully Connected (FC) layers within the CNN-DSA chip. At the workshop, we have two system demonstrations for NLP tasks. The first demo classifies the input English Wikipedia sentence into one of the 14 ontologies. The second demo classifies the Chinese online-shopping review into positive or negative.
SuperCaptioning: Image Captioning Using Two-dimensional Word Embedding
Jun 04, 2019
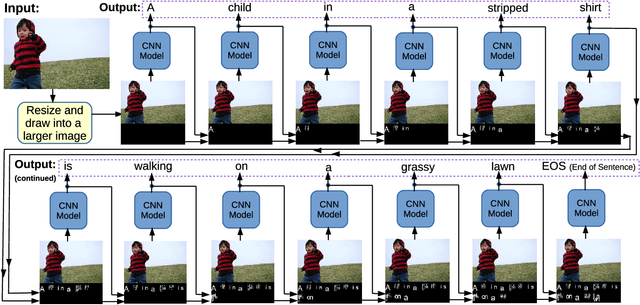
Language and vision are processed as two different modal in current work for image captioning. However, recent work on Super Characters method shows the effectiveness of two-dimensional word embedding, which converts text classification problem into image classification problem. In this paper, we propose the SuperCaptioning method, which borrows the idea of two-dimensional word embedding from Super Characters method, and processes the information of language and vision together in one single CNN model. The experimental results on Flickr30k data shows the proposed method gives high quality image captions. An interactive demo is ready to show at the workshop.
SuperTML: Two-Dimensional Word Embedding and Transfer Learning Using ImageNet Pretrained CNN Models for the Classifications on Tabular Data
Mar 22, 2019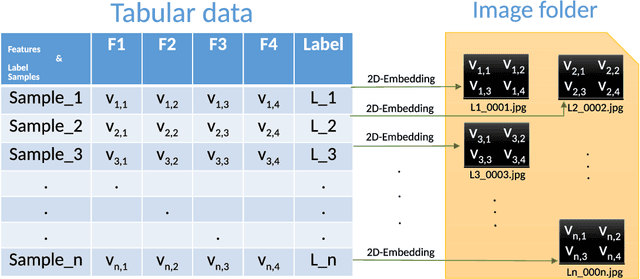


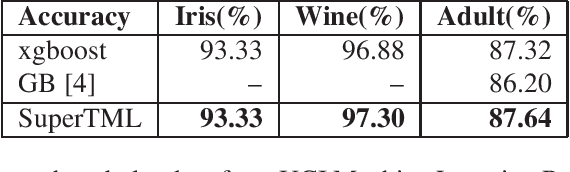
Tabular data is the most commonly used form of data in industry. Gradient Boosting Trees, Support Vector Machine, Random Forest, and Logistic Regression are typically used for classification tasks on tabular data. DNN models using categorical embeddings are also applied in this task, but all attempts thus far have used one-dimensional embeddings. The recent work of Super Characters method using two-dimensional word embeddings achieved the state of art result in text classification tasks, showcasing the promise of this new approach. In this paper, we propose the SuperTML method, which borrows the idea of Super Characters method and two-dimensional embeddings to address the problem of classification on tabular data. For each input of tabular data, the features are first projected into two-dimensional embeddings like an image, and then this image is fed into fine-tuned two-dimensional CNN models for classification. Experimental results have shown that the proposed SuperTML method had achieved state-of-the-art results on both large and small datasets.
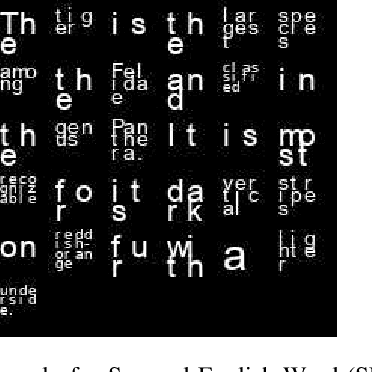
Squared English Word: A Method of Generating Glyph to Use Super Characters for Sentiment Analysis
Jan 24, 2019
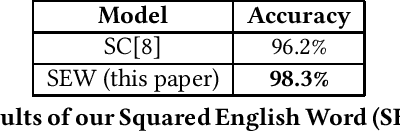


The Super Characters method addresses sentiment analysis problems by first converting the input text into images and then applying 2D-CNN models to classify the sentiment. It achieves state of the art performance on many benchmark datasets. However, it is not as straightforward to apply in Latin languages as in Asian languages. Because the 2D-CNN model is designed to recognize two-dimensional images, it is better if the inputs are in the form of glyphs. In this paper, we propose SEW (Squared English Word) method generating a squared glyph for each English word by drawing Super Characters images of each English word at the alphabet level, combining the squared glyph together into a whole Super Characters image at the sentence level, and then applying the CNN model to classify the sentiment within the sentence. We applied the SEW method to Wikipedia dataset and obtained a 2.1% accuracy gain compared to the original Super Characters method. In the CL-Aff shared task on the HappyDB dataset, we applied Super Characters with SEW method and obtained 86.9% accuracy for agency classification and 85.8% for social accuracy classification on the validation set based on 80%:20% random split on the given labeled dataset.
Super Characters: A Conversion from Sentiment Classification to Image Classification
Oct 15, 2018
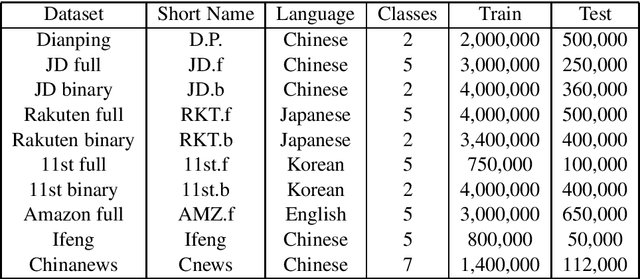


We propose a method named Super Characters for sentiment classification. This method converts the sentiment classification problem into image classification problem by projecting texts into images and then applying CNN models for classification. Text features are extracted automatically from the generated Super Characters images, hence there is no need of any explicit step of embedding the words or characters into numerical vector representations. Experimental results on large social media corpus show that the Super Characters method consistently outperforms other methods for sentiment classification and topic classification tasks on ten large social media datasets of millions of contents in four different languages, including Chinese, Japanese, Korean and English.
Ultra Power-Efficient CNN Domain Specific Accelerator with 9.3TOPS/Watt for Mobile and Embedded Applications
Apr 30, 2018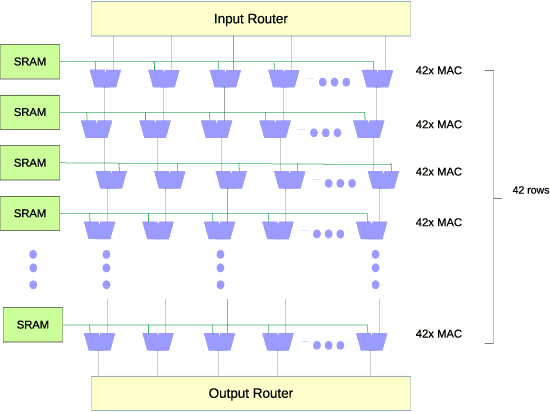
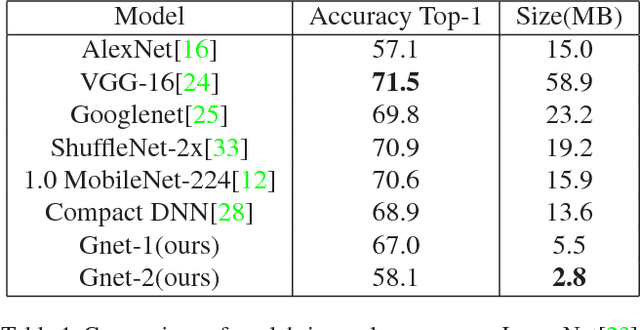
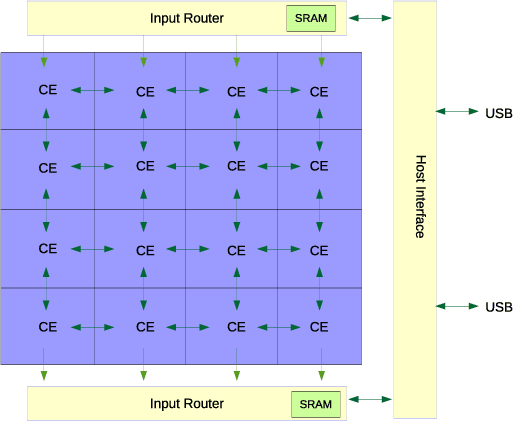
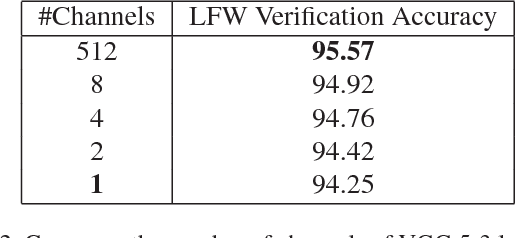
Computer vision performances have been significantly improved in recent years by Convolutional Neural Networks(CNN). Currently, applications using CNN algorithms are deployed mainly on general purpose hardwares, such as CPUs, GPUs or FPGAs. However, power consumption, speed, accuracy, memory footprint, and die size should all be taken into consideration for mobile and embedded applications. Domain Specific Architecture (DSA) for CNN is the efficient and practical solution for CNN deployment and implementation. We designed and produced a 28nm Two-Dimensional CNN-DSA accelerator with an ultra power-efficient performance of 9.3TOPS/Watt and with all processing done in the internal memory instead of outside DRAM. It classifies 224x224 RGB image inputs at more than 140fps with peak power consumption at less than 300mW and an accuracy comparable to the VGG benchmark. The CNN-DSA accelerator is reconfigurable to support CNN model coefficients of various layer sizes and layer types, including convolution, depth-wise convolution, short-cut connections, max pooling, and ReLU. Furthermore, in order to better support real-world deployment for various application scenarios, especially with low-end mobile and embedded platforms and MCUs (Microcontroller Units), we also designed algorithms to fully utilize the CNN-DSA accelerator efficiently by reducing the dependency on external accelerator computation resources, including implementation of Fully-Connected (FC) layers within the accelerator and compression of extracted features from the CNN-DSA accelerator. Live demos with our CNN-DSA accelerator on mobile and embedded systems show its capabilities to be widely and practically applied in the real world.