 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Tuning for Item Cold-start Recommendation
Dec 24, 2024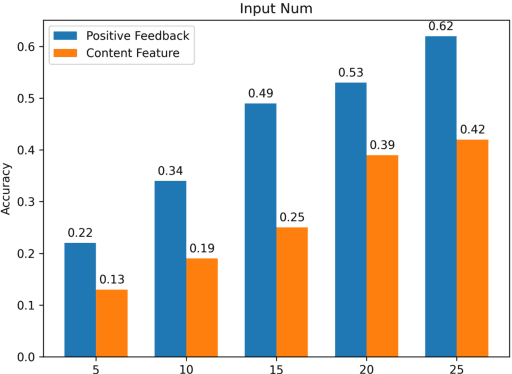
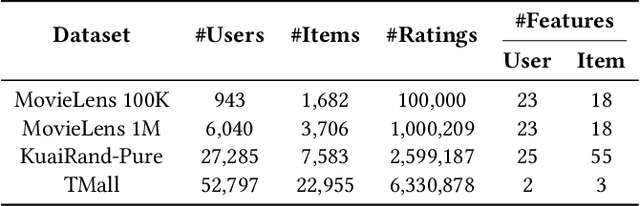
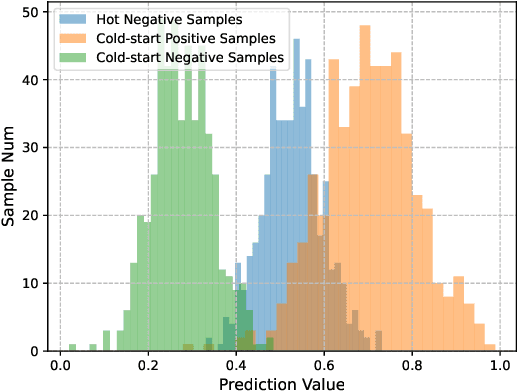
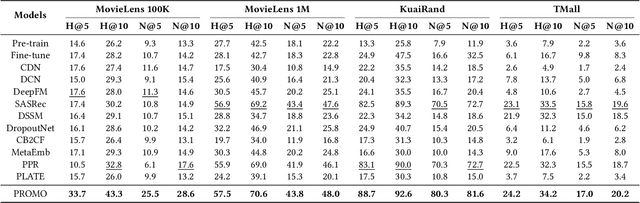
The item cold-start problem is crucial for online recommender systems, as the success of the cold-start phase determines whether items can transition into popular ones. Prompt learning, a powerful technique used in natural language processing (NLP) to address zero- or few-shot problems, has been adapted for recommender systems to tackle similar challenges. However, existing methods typically rely on content-based properties or text descriptions for prompting, which we argue may be suboptimal for cold-start recommendations due to 1) semantic gaps with recommender tasks, 2) model bias caused by warm-up items contribute most of the positive feedback to the model, which is the core of the cold-start problem that hinders the recommender quality on cold-start items. We propose to leverage high-value positive feedback, termed pinnacle feedback as prompt information, to simultaneously resolve the above two problems. We experimentally prove that compared to the content description proposed in existing works, the positive feedback is more suitable to serve as prompt information by bridging the semantic gaps. Besides, we propose item-wise personalized prompt networks to encode pinnaclce feedback to relieve the model bias by the positive feedback dominance problem. Extensive experiments on four real-world datasets demonstrate the superiority of our model over state-of-the-art methods. Moreover, PROMO has been successfully deployed on a popular short-video sharing platform, a billion-user scale commercial short-video application, achieving remarkable performance gains across various commercial metrics within cold-start scenarios
Filtered Randomized Smoothing: A New Defense for Robust Modulation Classification
Oct 08, 2024



Deep Neural Network (DNN) based classifiers have recently been used for the modulation classification of RF signals. These classifiers have shown impressive performance gains relative to conventional methods, however, they are vulnerable to imperceptible (low-power) adversarial attacks. Some of the prominent defense approaches include adversarial training (AT) and randomized smoothing (RS). While AT increases robustness in general, it fails to provide resilience against previously unseen adaptive attacks. Other approaches, such as Randomized Smoothing (RS), which injects noise into the input, address this shortcoming by providing provable certified guarantees against arbitrary attacks, however, they tend to sacrifice accuracy. In this paper, we study the problem of designing robust DNN-based modulation classifiers that can provide provable defense against arbitrary attacks without significantly sacrificing accuracy. To this end, we first analyze the spectral content of commonly studied attacks on modulation classifiers for the benchmark RadioML dataset. We observe that spectral signatures of un-perturbed RF signals are highly localized, whereas attack signals tend to be spread out in frequency. To exploit this spectral heterogeneity, we propose Filtered Randomized Smoothing (FRS), a novel defense which combines spectral filtering together with randomized smoothing. FRS can be viewed as a strengthening of RS by leveraging the specificity (spectral Heterogeneity) inherent to the modulation classification problem. In addition to providing an approach to compute the certified accuracy of FRS, we also provide a comprehensive set of simulations on the RadioML dataset to show the effectiveness of FRS and show that it significantly outperforms existing defenses including AT and RS in terms of accuracy on both attacked and benign signals.
Design and Implementation of A Soccer Ball Detection System with Multiple Cameras
Jan 31, 2023
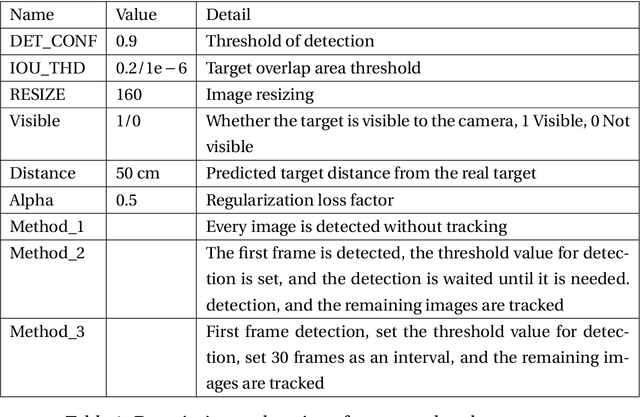


The detection of small and medium-sized objects in three dimensions has always been a frontier exploration problem. This technology has a very wide application in sports analysis, games, virtual reality, human animation and other fields. The traditional three-dimensional small target detection technology has the disadvantages of high cost, low precision and inconvenience, so it is difficult to apply in practice. With the development of machine learning and deep learning, the technology of computer vision algorithms is becoming more mature. Creating an immersive media experience is considered to be a very important research work in sports. The main work is to explore and solve the problem of football detection under the multiple cameras, aiming at the research and implementation of the live broadcast system of football matches. Using multi cameras detects a target ball and determines its position in three dimension with the occlusion, motion, low illumination of the target object. This paper designed and implemented football detection system under multiple cameras for the detection and capture of targets in real-time matches. The main work mainly consists of three parts, football detector, single camera detection, and multi-cameras detection. The system used bundle adjustment to obtain the three-dimensional position of the target, and the GPU to accelerates data pre-processing and achieve accurate real-time capture of the target. By testing the system, it shows that the system can accurately detect and capture the moving targets in 3D. In addition, the solution in this paper is reusable for large-scale competitions, like basketball and soccer. The system framework can be well transplanted into other similar engineering project systems. It has been put into the market.
SuperChat: Dialogue Generation by Transfer Learning from Vision to Language using Two-dimensional Word Embedding and Pretrained ImageNet CNN Models
Jun 04, 2019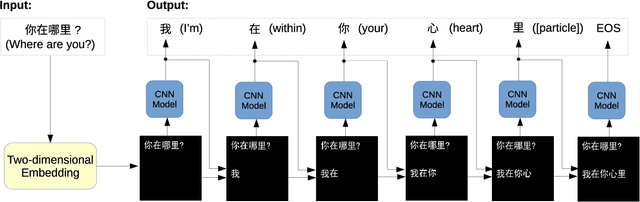
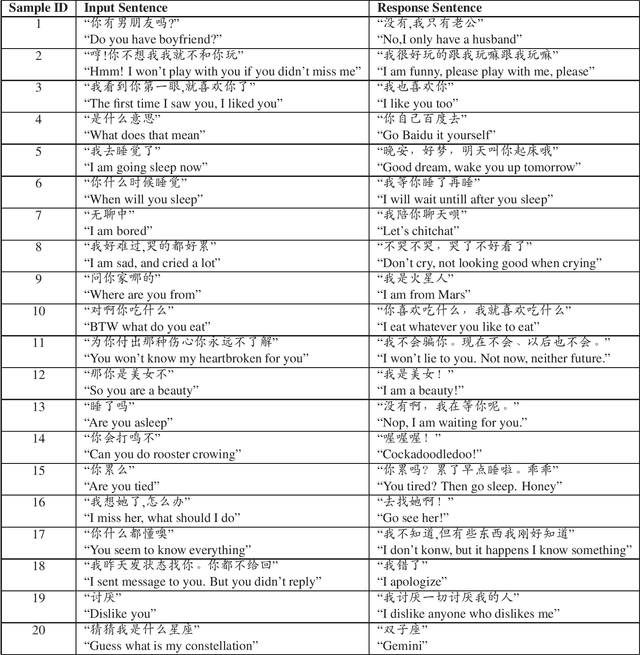
The recent work of Super Characters method using two-dimensional word embedding achieved state-of-the-art results in text classification tasks, showcasing the promise of this new approach. This paper borrows the idea of Super Characters method and two-dimensional embedding, and proposes a method of generating conversational response for open domain dialogues. The experimental results on a public dataset shows that the proposed SuperChat method generates high quality responses. An interactive demo is ready to show at the workshop.
System Demo for Transfer Learning across Vision and Text using Domain Specific CNN Accelerator for On-Device NLP Applications
Jun 04, 2019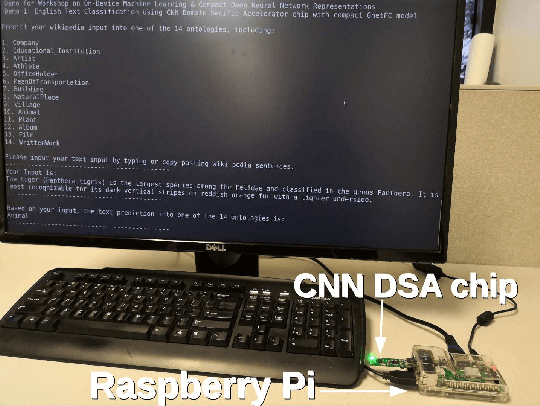

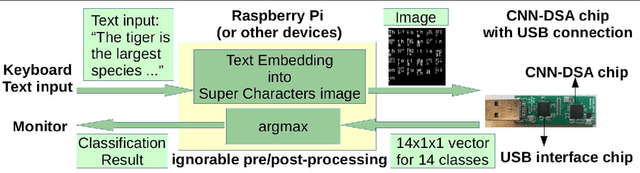
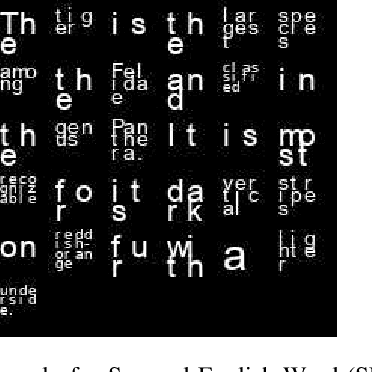
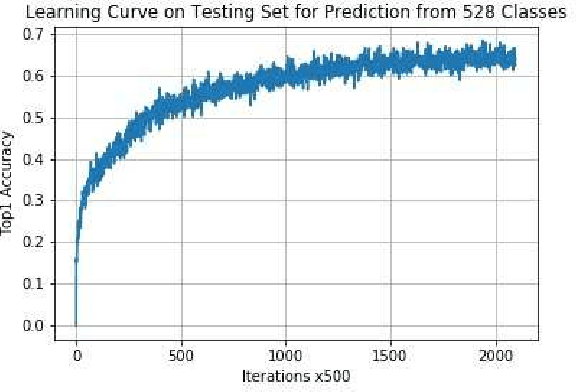
Power-efficient CNN Domain Specific Accelerator (CNN-DSA) chips are currently available for wide use in mobile devices. These chips are mainly used in computer vision applications. However, the recent work of Super Characters method for text classification and sentiment analysis tasks using two-dimensional CNN models has also achieved state-of-the-art results through the method of transfer learning from vision to text. In this paper, we implemented the text classification and sentiment analysis applications on mobile devices using CNN-DSA chips. Compact network representations using one-bit and three-bits precision for coefficients and five-bits for activations are used in the CNN-DSA chip with power consumption less than 300mW. For edge devices under memory and compute constraints, the network is further compressed by approximating the external Fully Connected (FC) layers within the CNN-DSA chip. At the workshop, we have two system demonstrations for NLP tasks. The first demo classifies the input English Wikipedia sentence into one of the 14 ontologies. The second demo classifies the Chinese online-shopping review into positive or negative.
SuperCaptioning: Image Captioning Using Two-dimensional Word Embedding
Jun 04, 2019
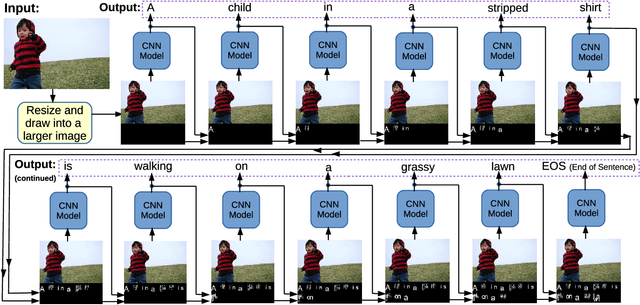
Language and vision are processed as two different modal in current work for image captioning. However, recent work on Super Characters method shows the effectiveness of two-dimensional word embedding, which converts text classification problem into image classification problem. In this paper, we propose the SuperCaptioning method, which borrows the idea of two-dimensional word embedding from Super Characters method, and processes the information of language and vision together in one single CNN model. The experimental results on Flickr30k data shows the proposed method gives high quality image captions. An interactive demo is ready to show at the workshop.
2-bit Model Compression of Deep Convolutional Neural Network on ASIC Engine for Image Retrieval
May 08, 2019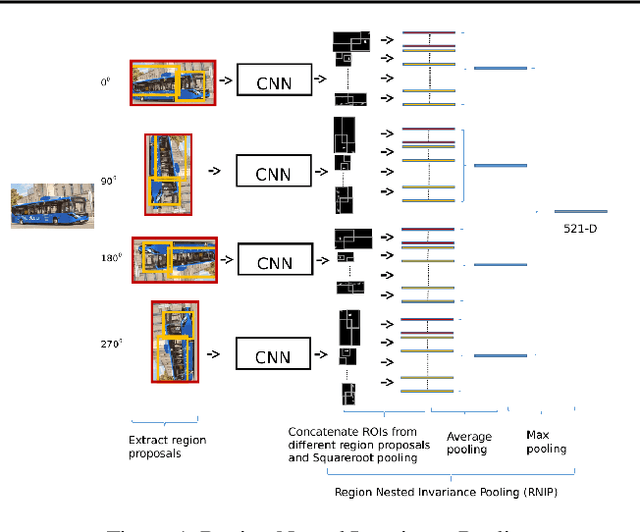
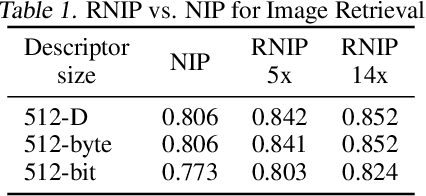
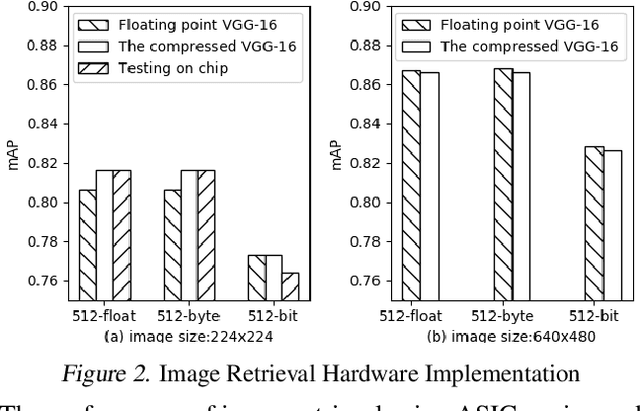

Image retrieval utilizes image descriptors to retrieve the most similar images to a given query image. Convolutional neural network (CNN) is becoming the dominant approach to extract image descriptors for image retrieval. For low-power hardware implementation of image retrieval, the drawback of CNN-based feature descriptor is that it requires hundreds of megabytes of storage. To address this problem, this paper applies deep model quantization and compression to CNN in ASIC chip for image retrieval. It is demonstrated that the CNN-based features descriptor can be extracted using as few as 2-bit weights quantization to deliver a similar performance as floating-point model for image retrieval. In addition, to implement CNN in ASIC, especially for large scale images, the limited buffer size of chips should be considered. To retrieve large scale images, we propose an improved pooling strategy, region nested invariance pooling (RNIP), which uses cropped sub-images for CNN. Testing results on chip show that integrating RNIP with the proposed 2-bit CNN model compression approach is capable of retrieving large scale images.
SuperTML: Two-Dimensional Word Embedding and Transfer Learning Using ImageNet Pretrained CNN Models for the Classifications on Tabular Data
Mar 22, 2019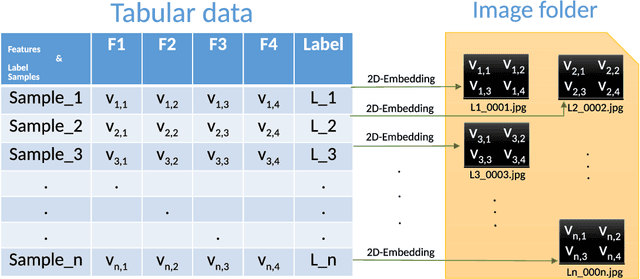


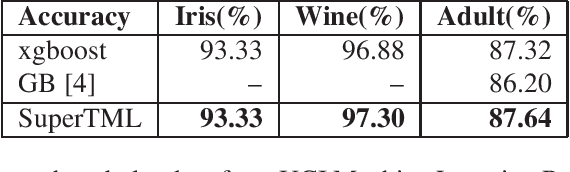
Tabular data is the most commonly used form of data in industry. Gradient Boosting Trees, Support Vector Machine, Random Forest, and Logistic Regression are typically used for classification tasks on tabular data. DNN models using categorical embeddings are also applied in this task, but all attempts thus far have used one-dimensional embeddings. The recent work of Super Characters method using two-dimensional word embeddings achieved the state of art result in text classification tasks, showcasing the promise of this new approach. In this paper, we propose the SuperTML method, which borrows the idea of Super Characters method and two-dimensional embeddings to address the problem of classification on tabular data. For each input of tabular data, the features are first projected into two-dimensional embeddings like an image, and then this image is fed into fine-tuned two-dimensional CNN models for classification. Experimental results have shown that the proposed SuperTML method had achieved state-of-the-art results on both large and small datasets.
Squared English Word: A Method of Generating Glyph to Use Super Characters for Sentiment Analysis
Jan 24, 2019
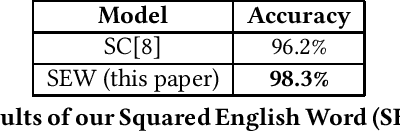


The Super Characters method addresses sentiment analysis problems by first converting the input text into images and then applying 2D-CNN models to classify the sentiment. It achieves state of the art performance on many benchmark datasets. However, it is not as straightforward to apply in Latin languages as in Asian languages. Because the 2D-CNN model is designed to recognize two-dimensional images, it is better if the inputs are in the form of glyphs. In this paper, we propose SEW (Squared English Word) method generating a squared glyph for each English word by drawing Super Characters images of each English word at the alphabet level, combining the squared glyph together into a whole Super Characters image at the sentence level, and then applying the CNN model to classify the sentiment within the sentence. We applied the SEW method to Wikipedia dataset and obtained a 2.1% accuracy gain compared to the original Super Characters method. In the CL-Aff shared task on the HappyDB dataset, we applied Super Characters with SEW method and obtained 86.9% accuracy for agency classification and 85.8% for social accuracy classification on the validation set based on 80%:20% random split on the given labeled dataset.
Super Characters: A Conversion from Sentiment Classification to Image Classification
Oct 15, 2018
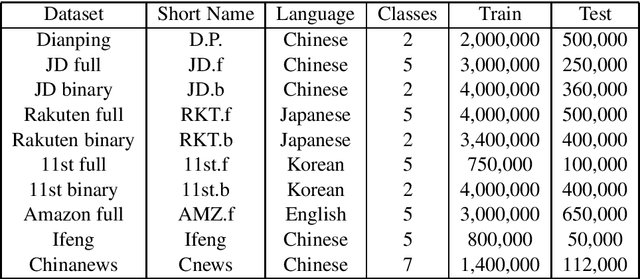


We propose a method named Super Characters for sentiment classification. This method converts the sentiment classification problem into image classification problem by projecting texts into images and then applying CNN models for classification. Text features are extracted automatically from the generated Super Characters images, hence there is no need of any explicit step of embedding the words or characters into numerical vector representations. Experimental results on large social media corpus show that the Super Characters method consistently outperforms other methods for sentiment classification and topic classification tasks on ten large social media datasets of millions of contents in four different languages, including Chinese, Japanese, Korean and English.