 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrompt Tuning for Item Cold-start Recommendation
Dec 24, 2024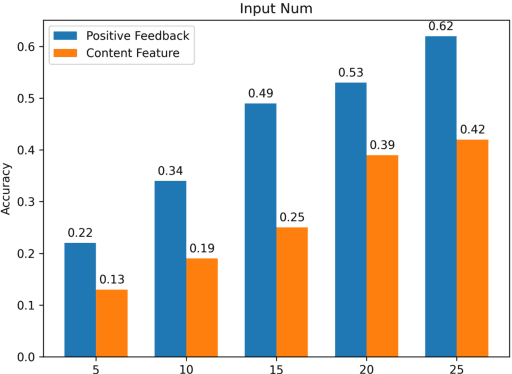
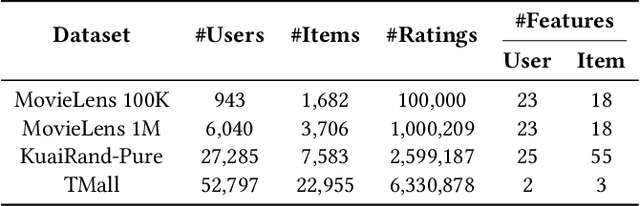
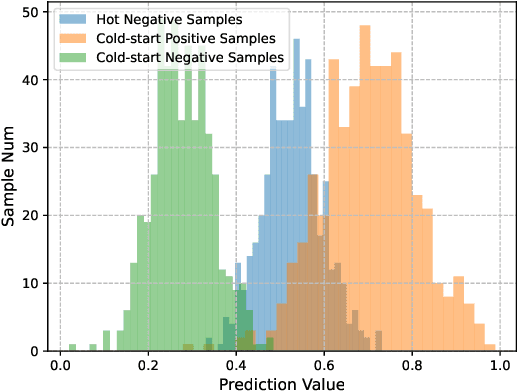
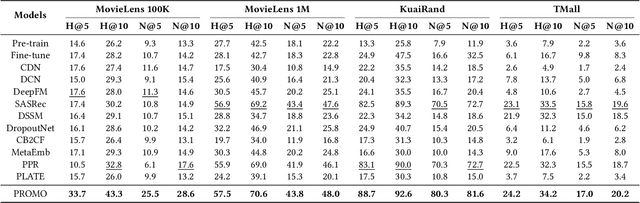
The item cold-start problem is crucial for online recommender systems, as the success of the cold-start phase determines whether items can transition into popular ones. Prompt learning, a powerful technique used in natural language processing (NLP) to address zero- or few-shot problems, has been adapted for recommender systems to tackle similar challenges. However, existing methods typically rely on content-based properties or text descriptions for prompting, which we argue may be suboptimal for cold-start recommendations due to 1) semantic gaps with recommender tasks, 2) model bias caused by warm-up items contribute most of the positive feedback to the model, which is the core of the cold-start problem that hinders the recommender quality on cold-start items. We propose to leverage high-value positive feedback, termed pinnacle feedback as prompt information, to simultaneously resolve the above two problems. We experimentally prove that compared to the content description proposed in existing works, the positive feedback is more suitable to serve as prompt information by bridging the semantic gaps. Besides, we propose item-wise personalized prompt networks to encode pinnaclce feedback to relieve the model bias by the positive feedback dominance problem. Extensive experiments on four real-world datasets demonstrate the superiority of our model over state-of-the-art methods. Moreover, PROMO has been successfully deployed on a popular short-video sharing platform, a billion-user scale commercial short-video application, achieving remarkable performance gains across various commercial metrics within cold-start scenarios
Online Item Cold-Start Recommendation with Popularity-Aware Meta-Learning
Nov 18, 2024



With the rise of e-commerce and short videos, online recommender systems that can capture users' interests and update new items in real-time play an increasingly important role. In both online and offline recommendation, the cold-start problem due to interaction sparsity has been affecting the recommendation effect of cold-start items, which is also known as the long-tail problem of item distribution. Many cold-start scheme based on fine-tuning or knowledge transferring shows excellent performance on offline recommendation. Yet, these schemes are infeasible for online recommendation on streaming data pipelines due to different training method, computational overhead and time constraints. Inspired by the above questions, we propose a model-agnostic recommendation algorithm called Popularity-Aware Meta-learning (PAM), to address the item cold-start problem under streaming data settings. PAM divides the incoming data into different meta-learning tasks by predefined item popularity thresholds. The model can distinguish and reweight behavior-related features and content-related features in each task based on their different roles in different popularity levels, thus adapting to recommendations for cold-start samples. These task-fixing design significantly reduces additional computation and storage costs compared to offline methods. Furthermore, PAM also introduced data augmentation and an additional self-supervised loss specifically designed for low-popularity tasks, leveraging insights from high-popularity samples. This approach effectively mitigates the issue of inadequate supervision due to the scarcity of cold-start samples. Experimental results across multiple public datasets demonstrate the superiority of our approach over other baseline methods in addressing cold-start challenges in online streaming data scenarios.
Model Degradation Hinders Deep Graph Neural Networks
Jun 09, 2022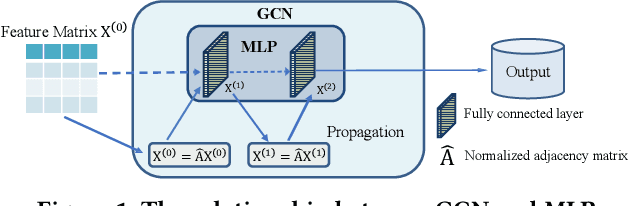
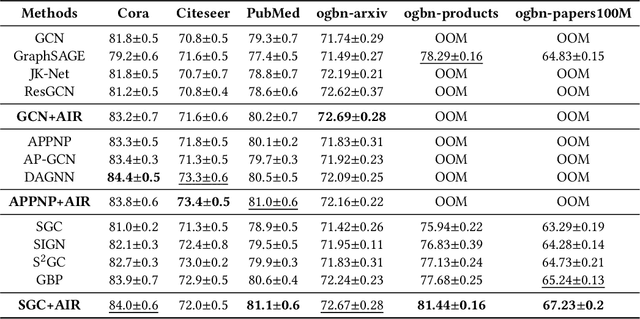
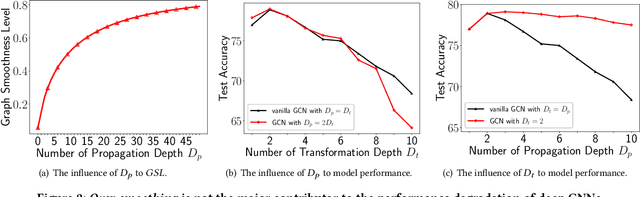
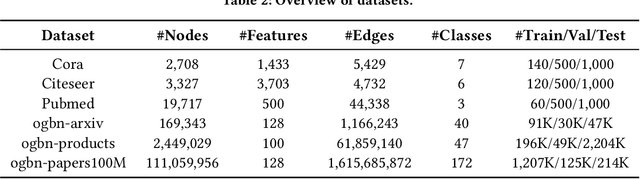
Graph Neural Networks (GNNs) have achieved great success in various graph mining tasks.However, drastic performance degradation is always observed when a GNN is stacked with many layers. As a result, most GNNs only have shallow architectures, which limits their expressive power and exploitation of deep neighborhoods.Most recent studies attribute the performance degradation of deep GNNs to the \textit{over-smoothing} issue. In this paper, we disentangle the conventional graph convolution operation into two independent operations: \textit{Propagation} (\textbf{P}) and \textit{Transformation} (\textbf{T}).Following this, the depth of a GNN can be split into the propagation depth ($D_p$) and the transformation depth ($D_t$). Through extensive experiments, we find that the major cause for the performance degradation of deep GNNs is the \textit{model degradation} issue caused by large $D_t$ rather than the \textit{over-smoothing} issue mainly caused by large $D_p$. Further, we present \textit{Adaptive Initial Residual} (AIR), a plug-and-play module compatible with all kinds of GNN architectures, to alleviate the \textit{model degradation} issue and the \textit{over-smoothing} issue simultaneously. Experimental results on six real-world datasets demonstrate that GNNs equipped with AIR outperform most GNNs with shallow architectures owing to the benefits of both large $D_p$ and $D_t$, while the time costs associated with AIR can be ignored.
* 11 pages, 10 figures
Instance-wise Prompt Tuning for Pretrained Language Models
Jun 04, 2022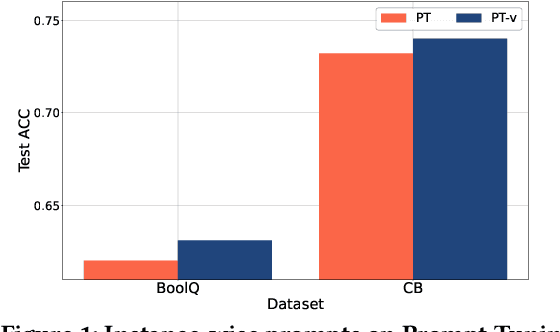

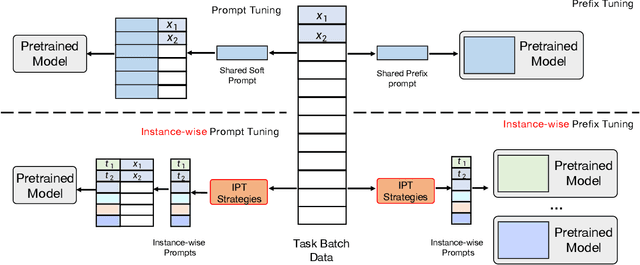
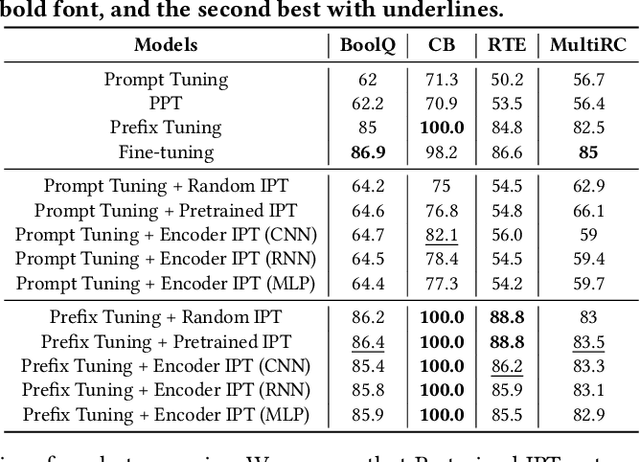
Prompt Learning has recently gained great popularity in bridging the gap between pretraining tasks and various downstream tasks. It freezes Pretrained Language Models (PLMs) and only tunes a few task-related parameters (prompts) for downstream tasks, greatly reducing the cost of tuning giant models. The key enabler of this is the idea of querying PLMs with task-specific knowledge implicated in prompts. This paper reveals a major limitation of existing methods that the indiscriminate prompts for all input data in a task ignore the intrinsic knowledge from input data, resulting in sub-optimal performance. We introduce Instance-wise Prompt Tuning (IPT), the first prompt learning paradigm that injects knowledge from the input data instances to the prompts, thereby providing PLMs with richer and more concrete context information. We devise a series of strategies to produce instance-wise prompts, addressing various concerns like model quality and cost-efficiency. Across multiple tasks and resource settings, IPT significantly outperforms task-based prompt learning methods, and achieves comparable performance to conventional finetuning with only 0.5% - 1.5% of tuned parameters.
ZOOMER: Boosting Retrieval on Web-scale Graphs by Regions of Interest
Mar 20, 2022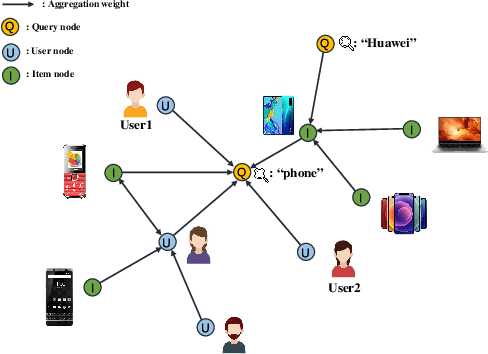
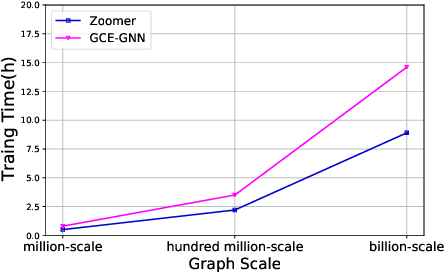
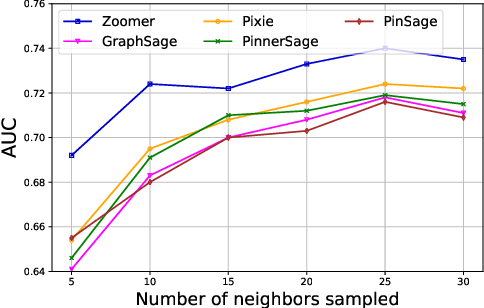
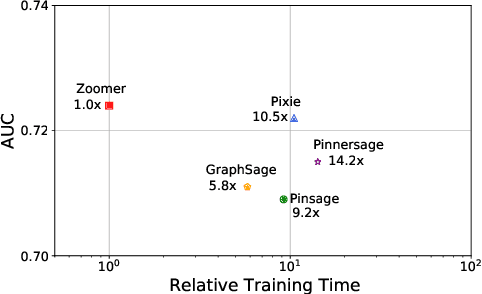
We introduce ZOOMER, a system deployed at Taobao, the largest e-commerce platform in China, for training and serving GNN-based recommendations over web-scale graphs. ZOOMER is designed for tackling two challenges presented by the massive user data at Taobao: low training/serving efficiency due to the huge scale of the graphs, and low recommendation quality due to the information overload which distracts the recommendation model from specific user intentions. ZOOMER achieves this by introducing a key concept, Region of Interests (ROI) in GNNs for recommendations, i.e., a neighborhood region in the graph with significant relevance to a strong user intention. ZOOMER narrows the focus from the whole graph and "zooms in" on the more relevant ROIs, thereby reducing the training/serving cost and mitigating the information overload at the same time. With carefully designed mechanisms, ZOOMER identifies the interest expressed by each recommendation request, constructs an ROI subgraph by sampling with respect to the interest, and guides the GNN to reweigh different parts of the ROI towards the interest by a multi-level attention module. Deployed as a large-scale distributed system, ZOOMER supports graphs with billions of nodes for training and thousands of requests per second for serving. ZOOMER achieves up to 14x speedup when downsizing sampling scales with comparable (even better) AUC performance than baseline methods. Besides, both the offline evaluation and online A/B test demonstrate the effectiveness of ZOOMER.
Evaluating Deep Graph Neural Networks
Aug 02, 2021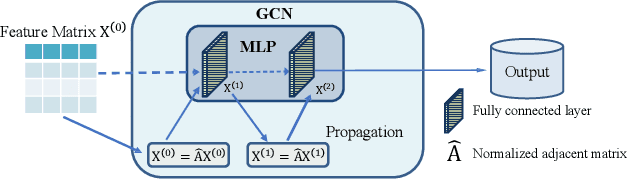

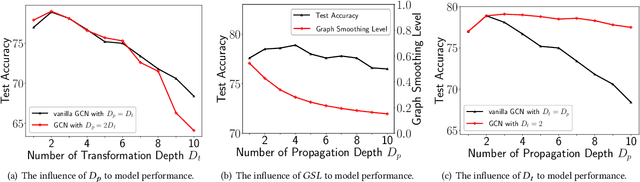
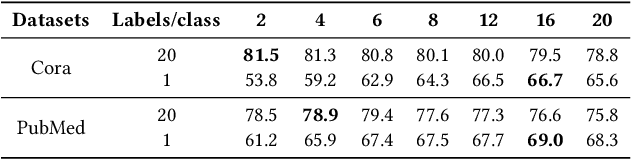
Graph Neural Networks (GNNs) have already been widely applied in various graph mining tasks. However, they suffer from the shallow architecture issue, which is the key impediment that hinders the model performance improvement. Although several relevant approaches have been proposed, none of the existing studies provides an in-depth understanding of the root causes of performance degradation in deep GNNs. In this paper, we conduct the first systematic experimental evaluation to present the fundamental limitations of shallow architectures. Based on the experimental results, we answer the following two essential questions: (1) what actually leads to the compromised performance of deep GNNs; (2) when we need and how to build deep GNNs. The answers to the above questions provide empirical insights and guidelines for researchers to design deep and well-performed GNNs. To show the effectiveness of our proposed guidelines, we present Deep Graph Multi-Layer Perceptron (DGMLP), a powerful approach (a paradigm in its own right) that helps guide deep GNN designs. Experimental results demonstrate three advantages of DGMLP: 1) high accuracy -- it achieves state-of-the-art node classification performance on various datasets; 2) high flexibility -- it can flexibly choose different propagation and transformation depths according to graph size and sparsity; 3) high scalability and efficiency -- it supports fast training on large-scale graphs. Our code is available in https://github.com/zwt233/DGMLP.
ROD: Reception-aware Online Distillation for Sparse Graphs
Jul 25, 2021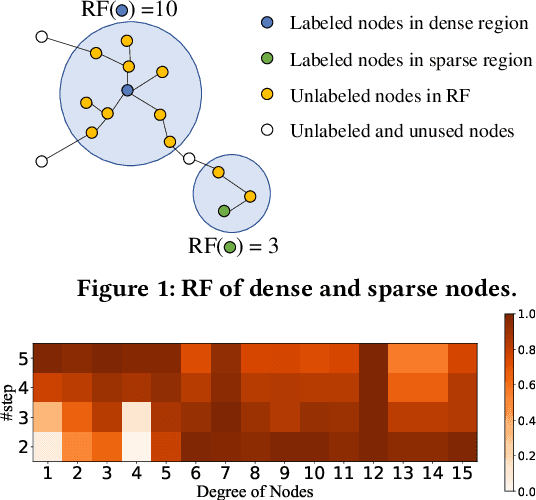
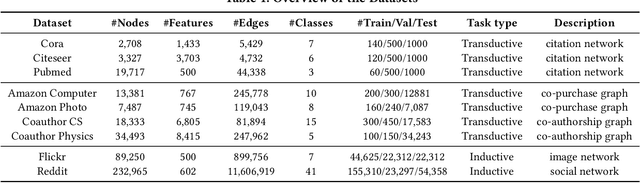
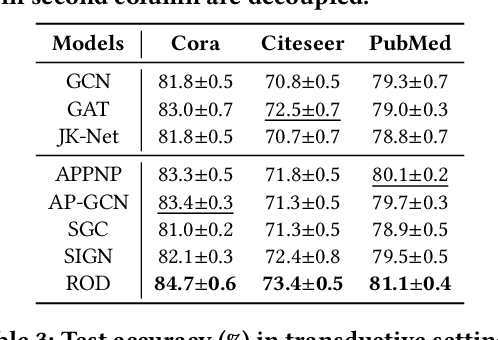
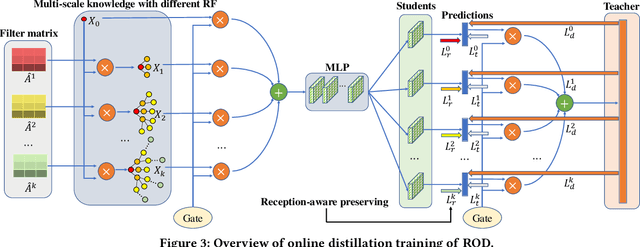
Graph neural networks (GNNs) have been widely used in many graph-based tasks such as node classification, link prediction, and node clustering. However, GNNs gain their performance benefits mainly from performing the feature propagation and smoothing across the edges of the graph, thus requiring sufficient connectivity and label information for effective propagation. Unfortunately, many real-world networks are sparse in terms of both edges and labels, leading to sub-optimal performance of GNNs. Recent interest in this sparse problem has focused on the self-training approach, which expands supervised signals with pseudo labels. Nevertheless, the self-training approach inherently cannot realize the full potential of refining the learning performance on sparse graphs due to the unsatisfactory quality and quantity of pseudo labels. In this paper, we propose ROD, a novel reception-aware online knowledge distillation approach for sparse graph learning. We design three supervision signals for ROD: multi-scale reception-aware graph knowledge, task-based supervision, and rich distilled knowledge, allowing online knowledge transfer in a peer-teaching manner. To extract knowledge concealed in the multi-scale reception fields, ROD explicitly requires individual student models to preserve different levels of locality information. For a given task, each student would predict based on its reception-scale knowledge, while simultaneously a strong teacher is established on-the-fly by combining multi-scale knowledge. Our approach has been extensively evaluated on 9 datasets and a variety of graph-based tasks, including node classification, link prediction, and node clustering. The result demonstrates that ROD achieves state-of-art performance and is more robust for the graph sparsity.