 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPrompt4EM: Augmented Prompt Tuning for Generalized Entity Matching
May 08, 2024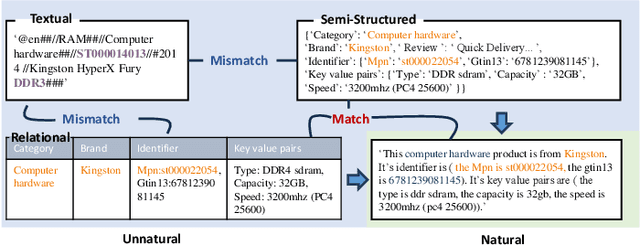
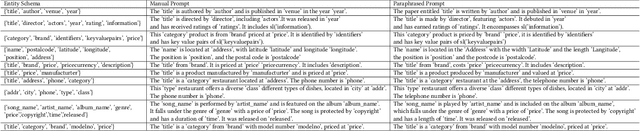
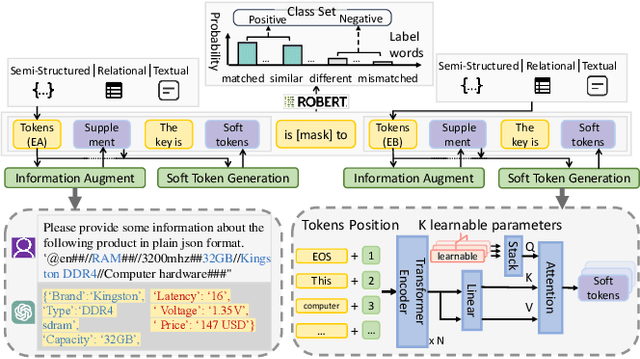
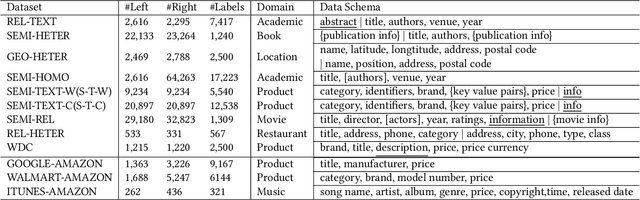
Generalized Entity Matching (GEM), which aims at judging whether two records represented in different formats refer to the same real-world entity, is an essential task in data management. The prompt tuning paradigm for pre-trained language models (PLMs), including the recent PromptEM model, effectively addresses the challenges of low-resource GEM in practical applications, offering a robust solution when labeled data is scarce. However, existing prompt tuning models for GEM face the challenges of prompt design and information gap. This paper introduces an augmented prompt tuning framework for the challenges, which consists of two main improvements. The first is an augmented contextualized soft token-based prompt tuning method that extracts a guiding soft token benefit for the PLMs' prompt tuning, and the second is a cost-effective information augmentation strategy leveraging large language models (LLMs). Our approach performs well on the low-resource GEM challenges. Extensive experiments show promising advancements of our basic model without information augmentation over existing methods based on moderate-size PLMs (average 5.24%+), and our model with information augmentation achieves comparable performance compared with fine-tuned LLMs, using less than 14% of the API fee.
Model Degradation Hinders Deep Graph Neural Networks
Jun 09, 2022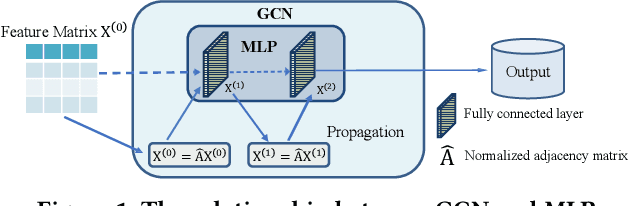
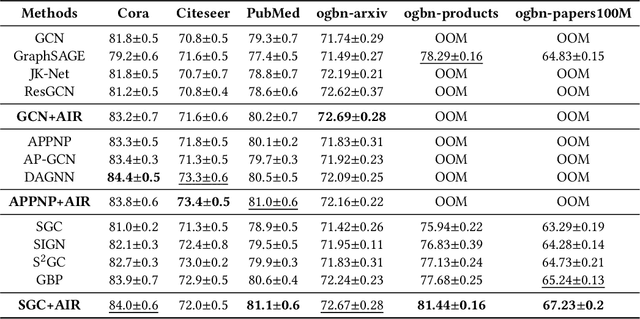
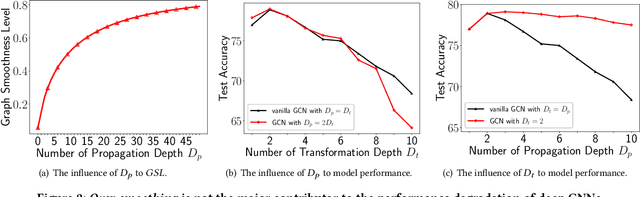
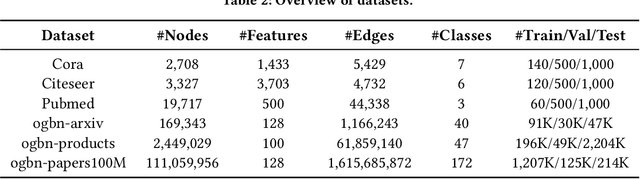
Graph Neural Networks (GNNs) have achieved great success in various graph mining tasks.However, drastic performance degradation is always observed when a GNN is stacked with many layers. As a result, most GNNs only have shallow architectures, which limits their expressive power and exploitation of deep neighborhoods.Most recent studies attribute the performance degradation of deep GNNs to the \textit{over-smoothing} issue. In this paper, we disentangle the conventional graph convolution operation into two independent operations: \textit{Propagation} (\textbf{P}) and \textit{Transformation} (\textbf{T}).Following this, the depth of a GNN can be split into the propagation depth ($D_p$) and the transformation depth ($D_t$). Through extensive experiments, we find that the major cause for the performance degradation of deep GNNs is the \textit{model degradation} issue caused by large $D_t$ rather than the \textit{over-smoothing} issue mainly caused by large $D_p$. Further, we present \textit{Adaptive Initial Residual} (AIR), a plug-and-play module compatible with all kinds of GNN architectures, to alleviate the \textit{model degradation} issue and the \textit{over-smoothing} issue simultaneously. Experimental results on six real-world datasets demonstrate that GNNs equipped with AIR outperform most GNNs with shallow architectures owing to the benefits of both large $D_p$ and $D_t$, while the time costs associated with AIR can be ignored.
* 11 pages, 10 figures
Evaluating Deep Graph Neural Networks
Aug 02, 2021

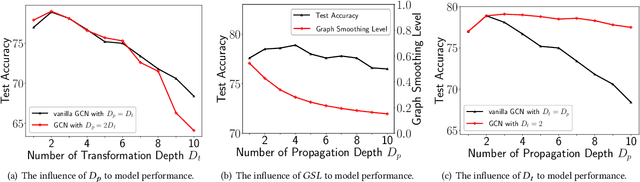
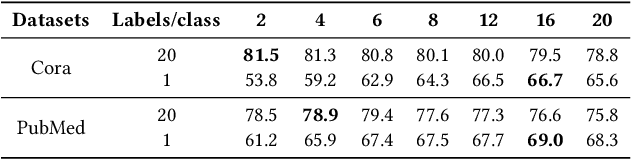
Graph Neural Networks (GNNs) have already been widely applied in various graph mining tasks. However, they suffer from the shallow architecture issue, which is the key impediment that hinders the model performance improvement. Although several relevant approaches have been proposed, none of the existing studies provides an in-depth understanding of the root causes of performance degradation in deep GNNs. In this paper, we conduct the first systematic experimental evaluation to present the fundamental limitations of shallow architectures. Based on the experimental results, we answer the following two essential questions: (1) what actually leads to the compromised performance of deep GNNs; (2) when we need and how to build deep GNNs. The answers to the above questions provide empirical insights and guidelines for researchers to design deep and well-performed GNNs. To show the effectiveness of our proposed guidelines, we present Deep Graph Multi-Layer Perceptron (DGMLP), a powerful approach (a paradigm in its own right) that helps guide deep GNN designs. Experimental results demonstrate three advantages of DGMLP: 1) high accuracy -- it achieves state-of-the-art node classification performance on various datasets; 2) high flexibility -- it can flexibly choose different propagation and transformation depths according to graph size and sparsity; 3) high scalability and efficiency -- it supports fast training on large-scale graphs. Our code is available in https://github.com/zwt233/DGMLP.
SAPIEN: A SimulAted Part-based Interactive ENvironment
Mar 19, 2020


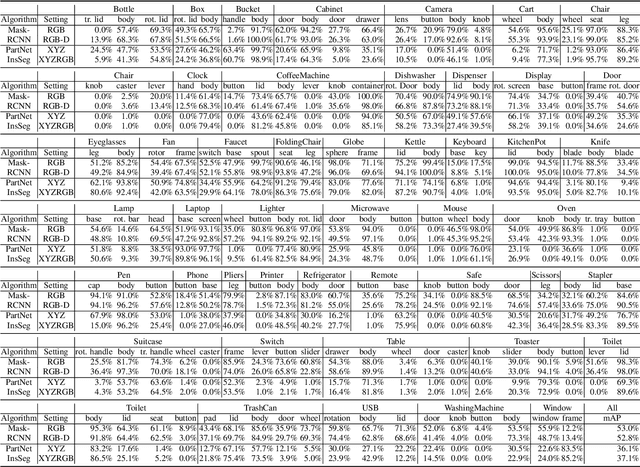
Building home assistant robots has long been a pursuit for vision and robotics researchers. To achieve this task, a simulated environment with physically realistic simulation, sufficient articulated objects, and transferability to the real robot is indispensable. Existing environments achieve these requirements for robotics simulation with different levels of simplification and focus. We take one step further in constructing an environment that supports household tasks for training robot learning algorithm. Our work, SAPIEN, is a realistic and physics-rich simulated environment that hosts a large-scale set for articulated objects. Our SAPIEN enables various robotic vision and interaction tasks that require detailed part-level understanding.We evaluate state-of-the-art vision algorithms for part detection and motion attribute recognition as well as demonstrate robotic interaction tasks using heuristic approaches and reinforcement learning algorithms. We hope that our SAPIEN can open a lot of research directions yet to be explored, including learning cognition through interaction, part motion discovery, and construction of robotics-ready simulated game environment.