 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModel Degradation Hinders Deep Graph Neural Networks
Paper and Code
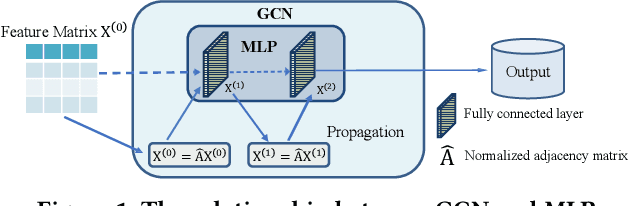
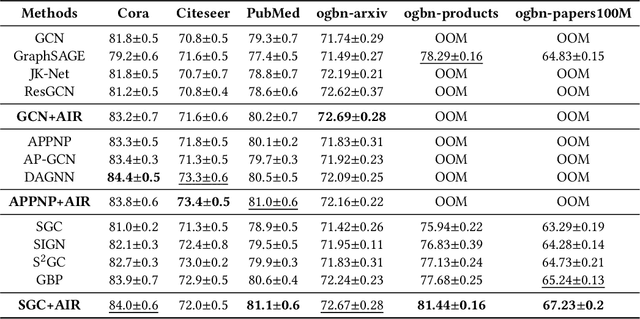
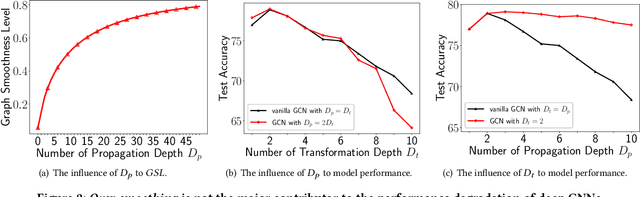
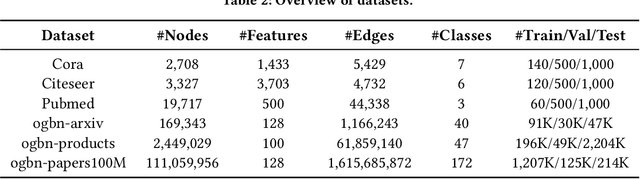
Graph Neural Networks (GNNs) have achieved great success in various graph mining tasks.However, drastic performance degradation is always observed when a GNN is stacked with many layers. As a result, most GNNs only have shallow architectures, which limits their expressive power and exploitation of deep neighborhoods.Most recent studies attribute the performance degradation of deep GNNs to the \textit{over-smoothing} issue. In this paper, we disentangle the conventional graph convolution operation into two independent operations: \textit{Propagation} (\textbf{P}) and \textit{Transformation} (\textbf{T}).Following this, the depth of a GNN can be split into the propagation depth ($D_p$) and the transformation depth ($D_t$). Through extensive experiments, we find that the major cause for the performance degradation of deep GNNs is the \textit{model degradation} issue caused by large $D_t$ rather than the \textit{over-smoothing} issue mainly caused by large $D_p$. Further, we present \textit{Adaptive Initial Residual} (AIR), a plug-and-play module compatible with all kinds of GNN architectures, to alleviate the \textit{model degradation} issue and the \textit{over-smoothing} issue simultaneously. Experimental results on six real-world datasets demonstrate that GNNs equipped with AIR outperform most GNNs with shallow architectures owing to the benefits of both large $D_p$ and $D_t$, while the time costs associated with AIR can be ignored.