 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIGaussian: Disentangle Gaussians for Spatial-Awared Text-Image-3D Alignment
Jan 27, 2026While visual-language models have profoundly linked features between texts and images, the incorporation of 3D modality data, such as point clouds and 3D Gaussians, further enables pretraining for 3D-related tasks, e.g., cross-modal retrieval, zero-shot classification, and scene recognition. As challenges remain in extracting 3D modal features and bridging the gap between different modalities, we propose TIGaussian, a framework that harnesses 3D Gaussian Splatting (3DGS) characteristics to strengthen cross-modality alignment through multi-branch 3DGS tokenizer and modality-specific 3D feature alignment strategies. Specifically, our multi-branch 3DGS tokenizer decouples the intrinsic properties of 3DGS structures into compact latent representations, enabling more generalizable feature extraction. To further bridge the modality gap, we develop a bidirectional cross-modal alignment strategies: a multi-view feature fusion mechanism that leverages diffusion priors to resolve perspective ambiguity in image-3D alignment, while a text-3D projection module adaptively maps 3D features to text embedding space for better text-3D alignment. Extensive experiments on various datasets demonstrate the state-of-the-art performance of TIGaussian in multiple tasks.
LARM: A Large Articulated-Object Reconstruction Model
Nov 14, 2025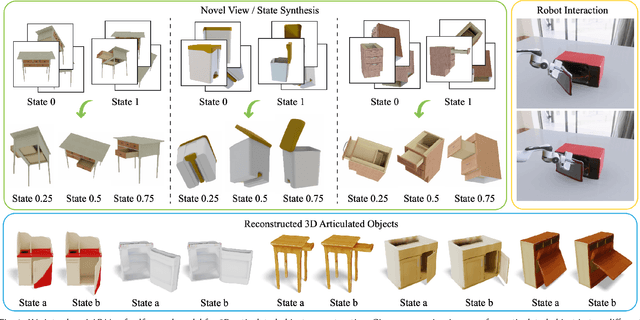
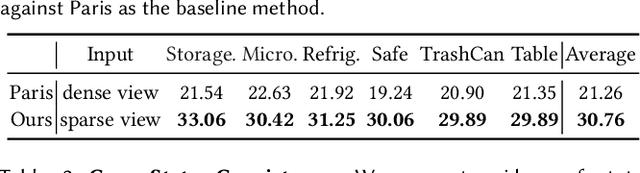


Modeling 3D articulated objects with realistic geometry, textures, and kinematics is essential for a wide range of applications. However, existing optimization-based reconstruction methods often require dense multi-view inputs and expensive per-instance optimization, limiting their scalability. Recent feedforward approaches offer faster alternatives but frequently produce coarse geometry, lack texture reconstruction, and rely on brittle, complex multi-stage pipelines. We introduce LARM, a unified feedforward framework that reconstructs 3D articulated objects from sparse-view images by jointly recovering detailed geometry, realistic textures, and accurate joint structures. LARM extends LVSM a recent novel view synthesis (NVS) approach for static 3D objects into the articulated setting by jointly reasoning over camera pose and articulation variation using a transformer-based architecture, enabling scalable and accurate novel view synthesis. In addition, LARM generates auxiliary outputs such as depth maps and part masks to facilitate explicit 3D mesh extraction and joint estimation. Our pipeline eliminates the need for dense supervision and supports high-fidelity reconstruction across diverse object categories. Extensive experiments demonstrate that LARM outperforms state-of-the-art methods in both novel view and state synthesis as well as 3D articulated object reconstruction, generating high-quality meshes that closely adhere to the input images. project page: https://sylviayuan-sy.github.io/larm-site/
FreeArt3D: Training-Free Articulated Object Generation using 3D Diffusion
Oct 29, 2025Articulated 3D objects are central to many applications in robotics, AR/VR, and animation. Recent approaches to modeling such objects either rely on optimization-based reconstruction pipelines that require dense-view supervision or on feed-forward generative models that produce coarse geometric approximations and often overlook surface texture. In contrast, open-world 3D generation of static objects has achieved remarkable success, especially with the advent of native 3D diffusion models such as Trellis. However, extending these methods to articulated objects by training native 3D diffusion models poses significant challenges. In this work, we present FreeArt3D, a training-free framework for articulated 3D object generation. Instead of training a new model on limited articulated data, FreeArt3D repurposes a pre-trained static 3D diffusion model (e.g., Trellis) as a powerful shape prior. It extends Score Distillation Sampling (SDS) into the 3D-to-4D domain by treating articulation as an additional generative dimension. Given a few images captured in different articulation states, FreeArt3D jointly optimizes the object's geometry, texture, and articulation parameters without requiring task-specific training or access to large-scale articulated datasets. Our method generates high-fidelity geometry and textures, accurately predicts underlying kinematic structures, and generalizes well across diverse object categories. Despite following a per-instance optimization paradigm, FreeArt3D completes in minutes and significantly outperforms prior state-of-the-art approaches in both quality and versatility.
PARTFIELD: Learning 3D Feature Fields for Part Segmentation and Beyond
Apr 15, 2025We propose PartField, a feedforward approach for learning part-based 3D features, which captures the general concept of parts and their hierarchy without relying on predefined templates or text-based names, and can be applied to open-world 3D shapes across various modalities. PartField requires only a 3D feedforward pass at inference time, significantly improving runtime and robustness compared to prior approaches. Our model is trained by distilling 2D and 3D part proposals from a mix of labeled datasets and image segmentations on large unsupervised datasets, via a contrastive learning formulation. It produces a continuous feature field which can be clustered to yield a hierarchical part decomposition. Comparisons show that PartField is up to 20% more accurate and often orders of magnitude faster than other recent class-agnostic part-segmentation methods. Beyond single-shape part decomposition, consistency in the learned field emerges across shapes, enabling tasks such as co-segmentation and correspondence, which we demonstrate in several applications of these general-purpose, hierarchical, and consistent 3D feature fields. Check our Webpage! https://research.nvidia.com/labs/toronto-ai/partfield-release/
MeshFormer: High-Quality Mesh Generation with 3D-Guided Reconstruction Model
Aug 19, 2024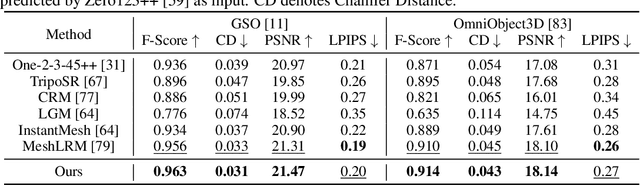
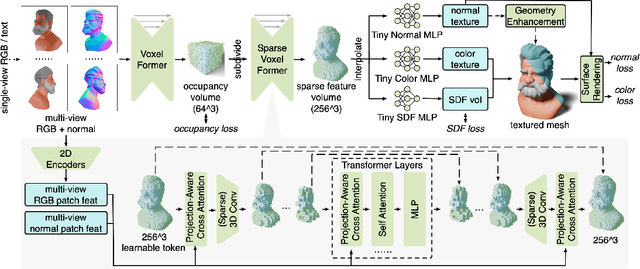


Open-world 3D reconstruction models have recently garnered significant attention. However, without sufficient 3D inductive bias, existing methods typically entail expensive training costs and struggle to extract high-quality 3D meshes. In this work, we introduce MeshFormer, a sparse-view reconstruction model that explicitly leverages 3D native structure, input guidance, and training supervision. Specifically, instead of using a triplane representation, we store features in 3D sparse voxels and combine transformers with 3D convolutions to leverage an explicit 3D structure and projective bias. In addition to sparse-view RGB input, we require the network to take input and generate corresponding normal maps. The input normal maps can be predicted by 2D diffusion models, significantly aiding in the guidance and refinement of the geometry's learning. Moreover, by combining Signed Distance Function (SDF) supervision with surface rendering, we directly learn to generate high-quality meshes without the need for complex multi-stage training processes. By incorporating these explicit 3D biases, MeshFormer can be trained efficiently and deliver high-quality textured meshes with fine-grained geometric details. It can also be integrated with 2D diffusion models to enable fast single-image-to-3D and text-to-3D tasks. Project page: https://meshformer3d.github.io
SpaRP: Fast 3D Object Reconstruction and Pose Estimation from Sparse Views
Aug 19, 2024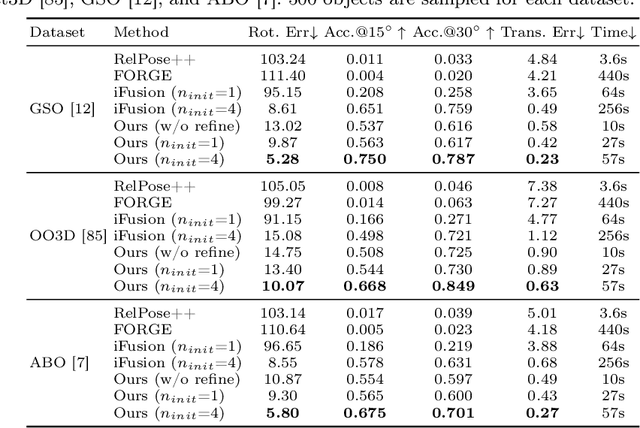

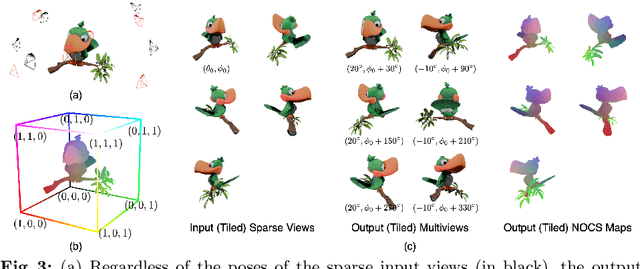

Open-world 3D generation has recently attracted considerable attention. While many single-image-to-3D methods have yielded visually appealing outcomes, they often lack sufficient controllability and tend to produce hallucinated regions that may not align with users' expectations. In this paper, we explore an important scenario in which the input consists of one or a few unposed 2D images of a single object, with little or no overlap. We propose a novel method, SpaRP, to reconstruct a 3D textured mesh and estimate the relative camera poses for these sparse-view images. SpaRP distills knowledge from 2D diffusion models and finetunes them to implicitly deduce the 3D spatial relationships between the sparse views. The diffusion model is trained to jointly predict surrogate representations for camera poses and multi-view images of the object under known poses, integrating all information from the input sparse views. These predictions are then leveraged to accomplish 3D reconstruction and pose estimation, and the reconstructed 3D model can be used to further refine the camera poses of input views. Through extensive experiments on three datasets, we demonstrate that our method not only significantly outperforms baseline methods in terms of 3D reconstruction quality and pose prediction accuracy but also exhibits strong efficiency. It requires only about 20 seconds to produce a textured mesh and camera poses for the input views. Project page: https://chaoxu.xyz/sparp.
Controllable Longer Image Animation with Diffusion Models
May 28, 2024



Generating realistic animated videos from static images is an important area of research in computer vision. Methods based on physical simulation and motion prediction have achieved notable advances, but they are often limited to specific object textures and motion trajectories, failing to exhibit highly complex environments and physical dynamics. In this paper, we introduce an open-domain controllable image animation method using motion priors with video diffusion models. Our method achieves precise control over the direction and speed of motion in the movable region by extracting the motion field information from videos and learning moving trajectories and strengths. Current pretrained video generation models are typically limited to producing very short videos, typically less than 30 frames. In contrast, we propose an efficient long-duration video generation method based on noise reschedule specifically tailored for image animation tasks, facilitating the creation of videos over 100 frames in length while maintaining consistency in content scenery and motion coordination. Specifically, we decompose the denoise process into two distinct phases: the shaping of scene contours and the refining of motion details. Then we reschedule the noise to control the generated frame sequences maintaining long-distance noise correlation. We conducted extensive experiments with 10 baselines, encompassing both commercial tools and academic methodologies, which demonstrate the superiority of our method. Our project page: https://wangqiang9.github.io/Controllable.github.io/
DrS: Learning Reusable Dense Rewards for Multi-Stage Tasks
Apr 25, 2024



The success of many RL techniques heavily relies on human-engineered dense rewards, which typically demand substantial domain expertise and extensive trial and error. In our work, we propose DrS (Dense reward learning from Stages), a novel approach for learning reusable dense rewards for multi-stage tasks in a data-driven manner. By leveraging the stage structures of the task, DrS learns a high-quality dense reward from sparse rewards and demonstrations if given. The learned rewards can be \textit{reused} in unseen tasks, thus reducing the human effort for reward engineering. Extensive experiments on three physical robot manipulation task families with 1000+ task variants demonstrate that our learned rewards can be reused in unseen tasks, resulting in improved performance and sample efficiency of RL algorithms. The learned rewards even achieve comparable performance to human-engineered rewards on some tasks. See our project page (https://sites.google.com/view/iclr24drs) for more details.
PartSLIP++: Enhancing Low-Shot 3D Part Segmentation via Multi-View Instance Segmentation and Maximum Likelihood Estimation
Dec 05, 2023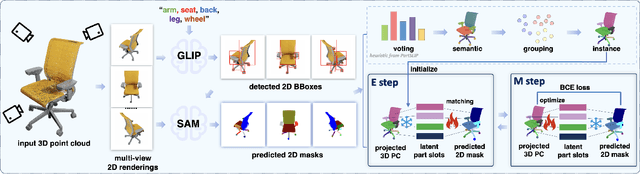
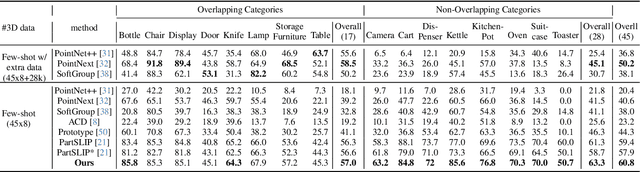
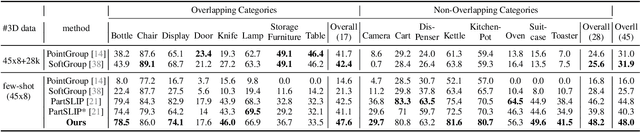
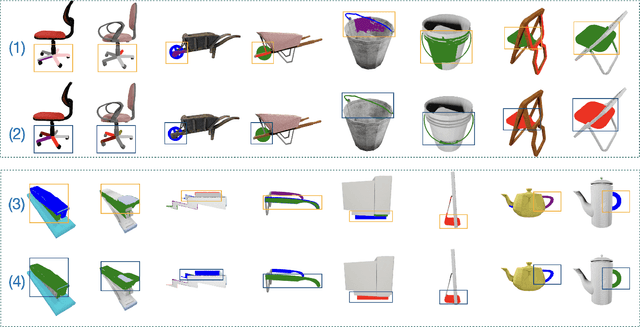
Open-world 3D part segmentation is pivotal in diverse applications such as robotics and AR/VR. Traditional supervised methods often grapple with limited 3D data availability and struggle to generalize to unseen object categories. PartSLIP, a recent advancement, has made significant strides in zero- and few-shot 3D part segmentation. This is achieved by harnessing the capabilities of the 2D open-vocabulary detection module, GLIP, and introducing a heuristic method for converting and lifting multi-view 2D bounding box predictions into 3D segmentation masks. In this paper, we introduce PartSLIP++, an enhanced version designed to overcome the limitations of its predecessor. Our approach incorporates two major improvements. First, we utilize a pre-trained 2D segmentation model, SAM, to produce pixel-wise 2D segmentations, yielding more precise and accurate annotations than the 2D bounding boxes used in PartSLIP. Second, PartSLIP++ replaces the heuristic 3D conversion process with an innovative modified Expectation-Maximization algorithm. This algorithm conceptualizes 3D instance segmentation as unobserved latent variables, and then iteratively refines them through an alternating process of 2D-3D matching and optimization with gradient descent. Through extensive evaluations, we show that PartSLIP++ demonstrates better performance over PartSLIP in both low-shot 3D semantic and instance-based object part segmentation tasks. Code released at https://github.com/zyc00/PartSLIP2.
One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion
Nov 14, 2023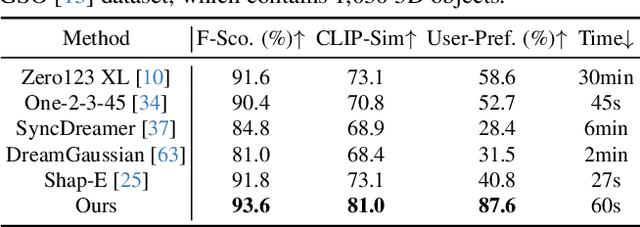
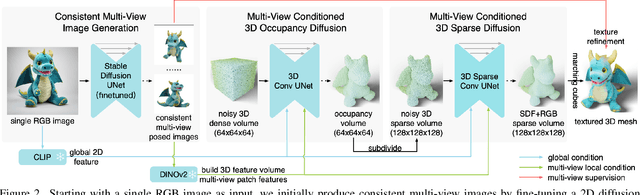
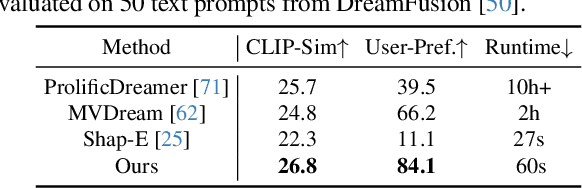
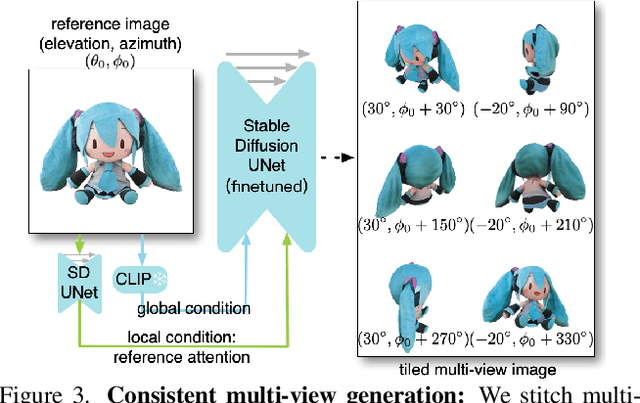
Recent advancements in open-world 3D object generation have been remarkable, with image-to-3D methods offering superior fine-grained control over their text-to-3D counterparts. However, most existing models fall short in simultaneously providing rapid generation speeds and high fidelity to input images - two features essential for practical applications. In this paper, we present One-2-3-45++, an innovative method that transforms a single image into a detailed 3D textured mesh in approximately one minute. Our approach aims to fully harness the extensive knowledge embedded in 2D diffusion models and priors from valuable yet limited 3D data. This is achieved by initially finetuning a 2D diffusion model for consistent multi-view image generation, followed by elevating these images to 3D with the aid of multi-view conditioned 3D native diffusion models. Extensive experimental evaluations demonstrate that our method can produce high-quality, diverse 3D assets that closely mirror the original input image. Our project webpage: https://sudo-ai-3d.github.io/One2345plus_page.