 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSG-VLA: Learning Spatially-Grounded Vision-Language-Action Models for Mobile Manipulation
Mar 24, 2026Vision-Language-Action (VLA) models show promise for robotic control, yet performance in complex household environments remains sub-optimal. Mobile manipulation requires reasoning about global scene layout, fine-grained geometry, and high-dimensional continuous actions, making standard imitation learning insufficient. We introduce a framework for learning spatially-grounded VLA models that strengthens perception and representation through auxiliary task co-training and multi-modal input enhancement. Our method addresses the challenge of controlling a 13-dimensional action space involving coordinated base motion, arm articulation, and gripper actuation. To enrich spatial understanding, the model incorporates multi-view RGB observations, depth cues, and short temporal history, providing perspectives of both global scene structure and local manipulation context. To improve representation quality, we co-train auxiliary decoders that reconstruct interpretable intermediate signals - including global robot position, joint configurations, grasp affordances, target-object relative pose, and segmentation masks - from shared visual-language features. These objectives provide dense supervision that encourages the backbone to develop spatially grounded, manipulation-aware latent representations. Through extensive evaluation on home rearrangement tasks, our approach achieves consistent improvements across picking, placing, opening, and closing operations, substantially outperforming direct imitation learning. Our findings suggest that spatial grounding through auxiliary and multi-modal learning provides a strong direction for scaling VLA models toward general-purpose domestic robots.
Planning-Guided Diffusion Policy Learning for Generalizable Contact-Rich Bimanual Manipulation
Dec 03, 2024



Contact-rich bimanual manipulation involves precise coordination of two arms to change object states through strategically selected contacts and motions. Due to the inherent complexity of these tasks, acquiring sufficient demonstration data and training policies that generalize to unseen scenarios remain a largely unresolved challenge. Building on recent advances in planning through contacts, we introduce Generalizable Planning-Guided Diffusion Policy Learning (GLIDE), an approach that effectively learns to solve contact-rich bimanual manipulation tasks by leveraging model-based motion planners to generate demonstration data in high-fidelity physics simulation. Through efficient planning in randomized environments, our approach generates large-scale and high-quality synthetic motion trajectories for tasks involving diverse objects and transformations. We then train a task-conditioned diffusion policy via behavior cloning using these demonstrations. To tackle the sim-to-real gap, we propose a set of essential design options in feature extraction, task representation, action prediction, and data augmentation that enable learning robust prediction of smooth action sequences and generalization to unseen scenarios. Through experiments in both simulation and the real world, we demonstrate that our approach can enable a bimanual robotic system to effectively manipulate objects of diverse geometries, dimensions, and physical properties. Website: https://glide-manip.github.io/
ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI
Oct 01, 2024



Simulation has enabled unprecedented compute-scalable approaches to robot learning. However, many existing simulation frameworks typically support a narrow range of scenes/tasks and lack features critical for scaling generalizable robotics and sim2real. We introduce and open source ManiSkill3, the fastest state-visual GPU parallelized robotics simulator with contact-rich physics targeting generalizable manipulation. ManiSkill3 supports GPU parallelization of many aspects including simulation+rendering, heterogeneous simulation, pointclouds/voxels visual input, and more. Simulation with rendering on ManiSkill3 can run 10-1000x faster with 2-3x less GPU memory usage than other platforms, achieving up to 30,000+ FPS in benchmarked environments due to minimal python/pytorch overhead in the system, simulation on the GPU, and the use of the SAPIEN parallel rendering system. Tasks that used to take hours to train can now take minutes. We further provide the most comprehensive range of GPU parallelized environments/tasks spanning 12 distinct domains including but not limited to mobile manipulation for tasks such as drawing, humanoids, and dextrous manipulation in realistic scenes designed by artists or real-world digital twins. In addition, millions of demonstration frames are provided from motion planning, RL, and teleoperation. ManiSkill3 also provides a comprehensive set of baselines that span popular RL and learning-from-demonstrations algorithms.
Live Fitness Coaching as a Testbed for Situated Interaction
Jul 11, 2024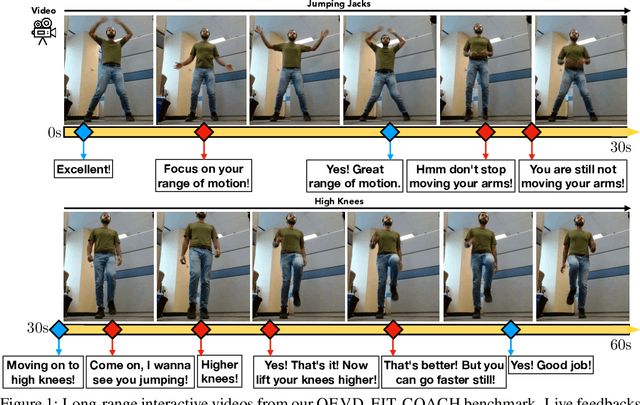



Tasks at the intersection of vision and language have had a profound impact in advancing the capabilities of vision-language models such as dialog-based assistants. However, models trained on existing tasks are largely limited to turn-based interactions, where each turn must be stepped (i.e., prompted) by the user. Open-ended, asynchronous interactions where an AI model may proactively deliver timely responses or feedback based on the unfolding situation in real-time are an open challenge. In this work, we present the QEVD benchmark and dataset which explores human-AI interaction in the challenging, yet controlled, real-world domain of fitness coaching - a task which intrinsically requires monitoring live user activity and providing timely feedback. It is the first benchmark that requires assistive vision-language models to recognize complex human actions, identify mistakes grounded in those actions, and provide appropriate feedback. Our experiments reveal the limitations of existing state of the art vision-language models for such asynchronous situated interactions. Motivated by this, we propose a simple end-to-end streaming baseline that can respond asynchronously to human actions with appropriate feedbacks at the appropriate time.
Evaluating Real-World Robot Manipulation Policies in Simulation
May 09, 2024



The field of robotics has made significant advances towards generalist robot manipulation policies. However, real-world evaluation of such policies is not scalable and faces reproducibility challenges, which are likely to worsen as policies broaden the spectrum of tasks they can perform. We identify control and visual disparities between real and simulated environments as key challenges for reliable simulated evaluation and propose approaches for mitigating these gaps without needing to craft full-fidelity digital twins of real-world environments. We then employ these approaches to create SIMPLER, a collection of simulated environments for manipulation policy evaluation on common real robot setups. Through paired sim-and-real evaluations of manipulation policies, we demonstrate strong correlation between policy performance in SIMPLER environments and in the real world. Additionally, we find that SIMPLER evaluations accurately reflect real-world policy behavior modes such as sensitivity to various distribution shifts. We open-source all SIMPLER environments along with our workflow for creating new environments at https://simpler-env.github.io to facilitate research on general-purpose manipulation policies and simulated evaluation frameworks.
PartSLIP++: Enhancing Low-Shot 3D Part Segmentation via Multi-View Instance Segmentation and Maximum Likelihood Estimation
Dec 05, 2023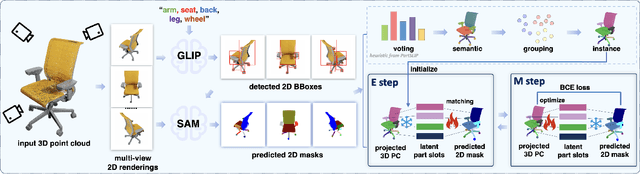
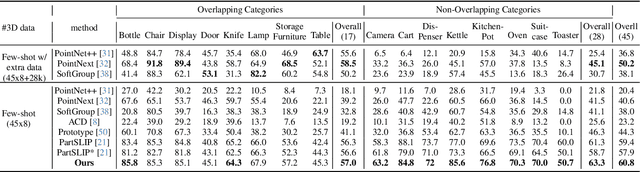
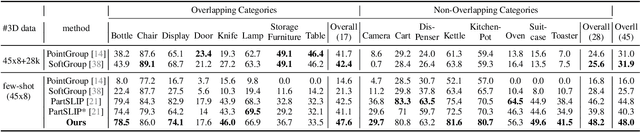
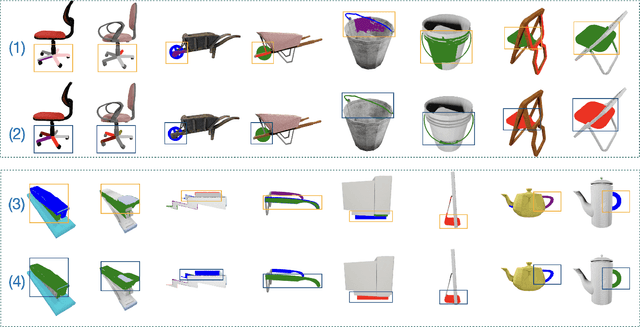
Open-world 3D part segmentation is pivotal in diverse applications such as robotics and AR/VR. Traditional supervised methods often grapple with limited 3D data availability and struggle to generalize to unseen object categories. PartSLIP, a recent advancement, has made significant strides in zero- and few-shot 3D part segmentation. This is achieved by harnessing the capabilities of the 2D open-vocabulary detection module, GLIP, and introducing a heuristic method for converting and lifting multi-view 2D bounding box predictions into 3D segmentation masks. In this paper, we introduce PartSLIP++, an enhanced version designed to overcome the limitations of its predecessor. Our approach incorporates two major improvements. First, we utilize a pre-trained 2D segmentation model, SAM, to produce pixel-wise 2D segmentations, yielding more precise and accurate annotations than the 2D bounding boxes used in PartSLIP. Second, PartSLIP++ replaces the heuristic 3D conversion process with an innovative modified Expectation-Maximization algorithm. This algorithm conceptualizes 3D instance segmentation as unobserved latent variables, and then iteratively refines them through an alternating process of 2D-3D matching and optimization with gradient descent. Through extensive evaluations, we show that PartSLIP++ demonstrates better performance over PartSLIP in both low-shot 3D semantic and instance-based object part segmentation tasks. Code released at https://github.com/zyc00/PartSLIP2.
Unleashing the Creative Mind: Language Model As Hierarchical Policy For Improved Exploration on Challenging Problem Solving
Nov 01, 2023



Large Language Models (LLMs) have achieved tremendous progress, yet they still often struggle with challenging reasoning problems. Current approaches address this challenge by sampling or searching detailed and low-level reasoning chains. However, these methods are still limited in their exploration capabilities, making it challenging for correct solutions to stand out in the huge solution space. In this work, we unleash LLMs' creative potential for exploring multiple diverse problem solving strategies by framing an LLM as a hierarchical policy via in-context learning. This policy comprises of a visionary leader that proposes multiple diverse high-level problem-solving tactics as hints, accompanied by a follower that executes detailed problem-solving processes following each of the high-level instruction. The follower uses each of the leader's directives as a guide and samples multiple reasoning chains to tackle the problem, generating a solution group for each leader proposal. Additionally, we propose an effective and efficient tournament-based approach to select among these explored solution groups to reach the final answer. Our approach produces meaningful and inspiring hints, enhances problem-solving strategy exploration, and improves the final answer accuracy on challenging problems in the MATH dataset. Code will be released at https://github.com/lz1oceani/LLM-As-Hierarchical-Policy.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Reparameterized Policy Learning for Multimodal Trajectory Optimization
Jul 20, 2023



We investigate the challenge of parametrizing policies for reinforcement learning (RL) in high-dimensional continuous action spaces. Our objective is to develop a multimodal policy that overcomes limitations inherent in the commonly-used Gaussian parameterization. To achieve this, we propose a principled framework that models the continuous RL policy as a generative model of optimal trajectories. By conditioning the policy on a latent variable, we derive a novel variational bound as the optimization objective, which promotes exploration of the environment. We then present a practical model-based RL method, called Reparameterized Policy Gradient (RPG), which leverages the multimodal policy parameterization and learned world model to achieve strong exploration capabilities and high data efficiency. Empirical results demonstrate that our method can help agents evade local optima in tasks with dense rewards and solve challenging sparse-reward environments by incorporating an object-centric intrinsic reward. Our method consistently outperforms previous approaches across a range of tasks. Code and supplementary materials are available on the project page https://haosulab.github.io/RPG/
Distilling Large Vision-Language Model with Out-of-Distribution Generalizability
Jul 19, 2023Large vision-language models have achieved outstanding performance, but their size and computational requirements make their deployment on resource-constrained devices and time-sensitive tasks impractical. Model distillation, the process of creating smaller, faster models that maintain the performance of larger models, is a promising direction towards the solution. This paper investigates the distillation of visual representations in large teacher vision-language models into lightweight student models using a small- or mid-scale dataset. Notably, this study focuses on open-vocabulary out-of-distribution (OOD) generalization, a challenging problem that has been overlooked in previous model distillation literature. We propose two principles from vision and language modality perspectives to enhance student's OOD generalization: (1) by better imitating teacher's visual representation space, and carefully promoting better coherence in vision-language alignment with the teacher; (2) by enriching the teacher's language representations with informative and finegrained semantic attributes to effectively distinguish between different labels. We propose several metrics and conduct extensive experiments to investigate their techniques. The results demonstrate significant improvements in zero-shot and few-shot student performance on open-vocabulary out-of-distribution classification, highlighting the effectiveness of our proposed approaches. Code released at https://github.com/xuanlinli17/large_vlm_distillation_ood