 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Fitness Coaching as a Testbed for Situated Interaction
Jul 11, 2024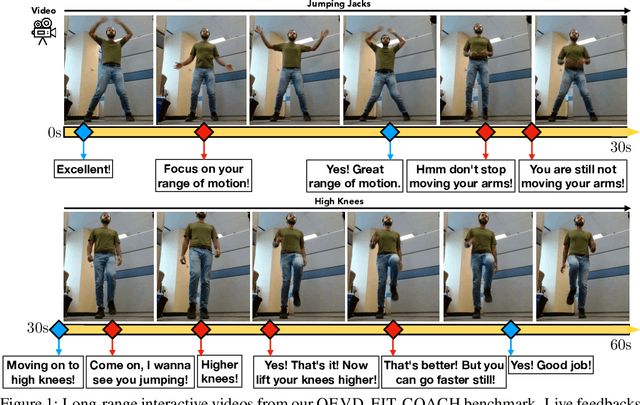



Tasks at the intersection of vision and language have had a profound impact in advancing the capabilities of vision-language models such as dialog-based assistants. However, models trained on existing tasks are largely limited to turn-based interactions, where each turn must be stepped (i.e., prompted) by the user. Open-ended, asynchronous interactions where an AI model may proactively deliver timely responses or feedback based on the unfolding situation in real-time are an open challenge. In this work, we present the QEVD benchmark and dataset which explores human-AI interaction in the challenging, yet controlled, real-world domain of fitness coaching - a task which intrinsically requires monitoring live user activity and providing timely feedback. It is the first benchmark that requires assistive vision-language models to recognize complex human actions, identify mistakes grounded in those actions, and provide appropriate feedback. Our experiments reveal the limitations of existing state of the art vision-language models for such asynchronous situated interactions. Motivated by this, we propose a simple end-to-end streaming baseline that can respond asynchronously to human actions with appropriate feedbacks at the appropriate time.