 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Fitness Coaching as a Testbed for Situated Interaction
Jul 11, 2024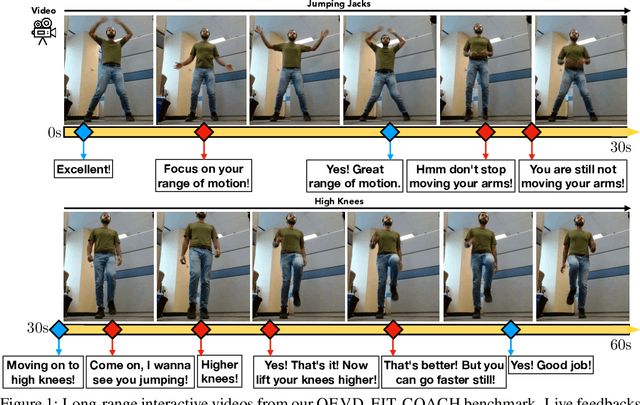



Tasks at the intersection of vision and language have had a profound impact in advancing the capabilities of vision-language models such as dialog-based assistants. However, models trained on existing tasks are largely limited to turn-based interactions, where each turn must be stepped (i.e., prompted) by the user. Open-ended, asynchronous interactions where an AI model may proactively deliver timely responses or feedback based on the unfolding situation in real-time are an open challenge. In this work, we present the QEVD benchmark and dataset which explores human-AI interaction in the challenging, yet controlled, real-world domain of fitness coaching - a task which intrinsically requires monitoring live user activity and providing timely feedback. It is the first benchmark that requires assistive vision-language models to recognize complex human actions, identify mistakes grounded in those actions, and provide appropriate feedback. Our experiments reveal the limitations of existing state of the art vision-language models for such asynchronous situated interactions. Motivated by this, we propose a simple end-to-end streaming baseline that can respond asynchronously to human actions with appropriate feedbacks at the appropriate time.
HexaGen3D: StableDiffusion is just one step away from Fast and Diverse Text-to-3D Generation
Jan 15, 2024Despite the latest remarkable advances in generative modeling, efficient generation of high-quality 3D assets from textual prompts remains a difficult task. A key challenge lies in data scarcity: the most extensive 3D datasets encompass merely millions of assets, while their 2D counterparts contain billions of text-image pairs. To address this, we propose a novel approach which harnesses the power of large, pretrained 2D diffusion models. More specifically, our approach, HexaGen3D, fine-tunes a pretrained text-to-image model to jointly predict 6 orthographic projections and the corresponding latent triplane. We then decode these latents to generate a textured mesh. HexaGen3D does not require per-sample optimization, and can infer high-quality and diverse objects from textual prompts in 7 seconds, offering significantly better quality-to-latency trade-offs when comparing to existing approaches. Furthermore, HexaGen3D demonstrates strong generalization to new objects or compositions.
Efficient neural supersampling on a novel gaming dataset
Aug 03, 2023Real-time rendering for video games has become increasingly challenging due to the need for higher resolutions, framerates and photorealism. Supersampling has emerged as an effective solution to address this challenge. Our work introduces a novel neural algorithm for supersampling rendered content that is 4 times more efficient than existing methods while maintaining the same level of accuracy. Additionally, we introduce a new dataset which provides auxiliary modalities such as motion vectors and depth generated using graphics rendering features like viewport jittering and mipmap biasing at different resolutions. We believe that this dataset fills a gap in the current dataset landscape and can serve as a valuable resource to help measure progress in the field and advance the state-of-the-art in super-resolution techniques for gaming content.
Is end-to-end learning enough for fitness activity recognition?
May 14, 2023



End-to-end learning has taken hold of many computer vision tasks, in particular, related to still images, with task-specific optimization yielding very strong performance. Nevertheless, human-centric action recognition is still largely dominated by hand-crafted pipelines, and only individual components are replaced by neural networks that typically operate on individual frames. As a testbed to study the relevance of such pipelines, we present a new fully annotated video dataset of fitness activities. Any recognition capabilities in this domain are almost exclusively a function of human poses and their temporal dynamics, so pose-based solutions should perform well. We show that, with this labelled data, end-to-end learning on raw pixels can compete with state-of-the-art action recognition pipelines based on pose estimation. We also show that end-to-end learning can support temporally fine-grained tasks such as real-time repetition counting.
QuickSRNet: Plain Single-Image Super-Resolution Architecture for Faster Inference on Mobile Platforms
Mar 08, 2023



In this work, we present QuickSRNet, an efficient super-resolution architecture for real-time applications on mobile platforms. Super-resolution clarifies, sharpens, and upscales an image to higher resolution. Applications such as gaming and video playback along with the ever-improving display capabilities of TVs, smartphones, and VR headsets are driving the need for efficient upscaling solutions. While existing deep learning-based super-resolution approaches achieve impressive results in terms of visual quality, enabling real-time DL-based super-resolution on mobile devices with compute, thermal, and power constraints is challenging. To address these challenges, we propose QuickSRNet, a simple yet effective architecture that provides better accuracy-to-latency trade-offs than existing neural architectures for single-image super resolution. We present training tricks to speed up existing residual-based super-resolution architectures while maintaining robustness to quantization. Our proposed architecture produces 1080p outputs via 2x upscaling in 2.2 ms on a modern smartphone, making it ideal for high-fps real-time applications.